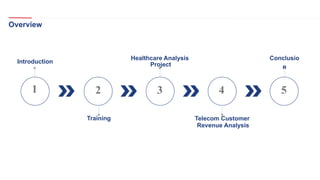
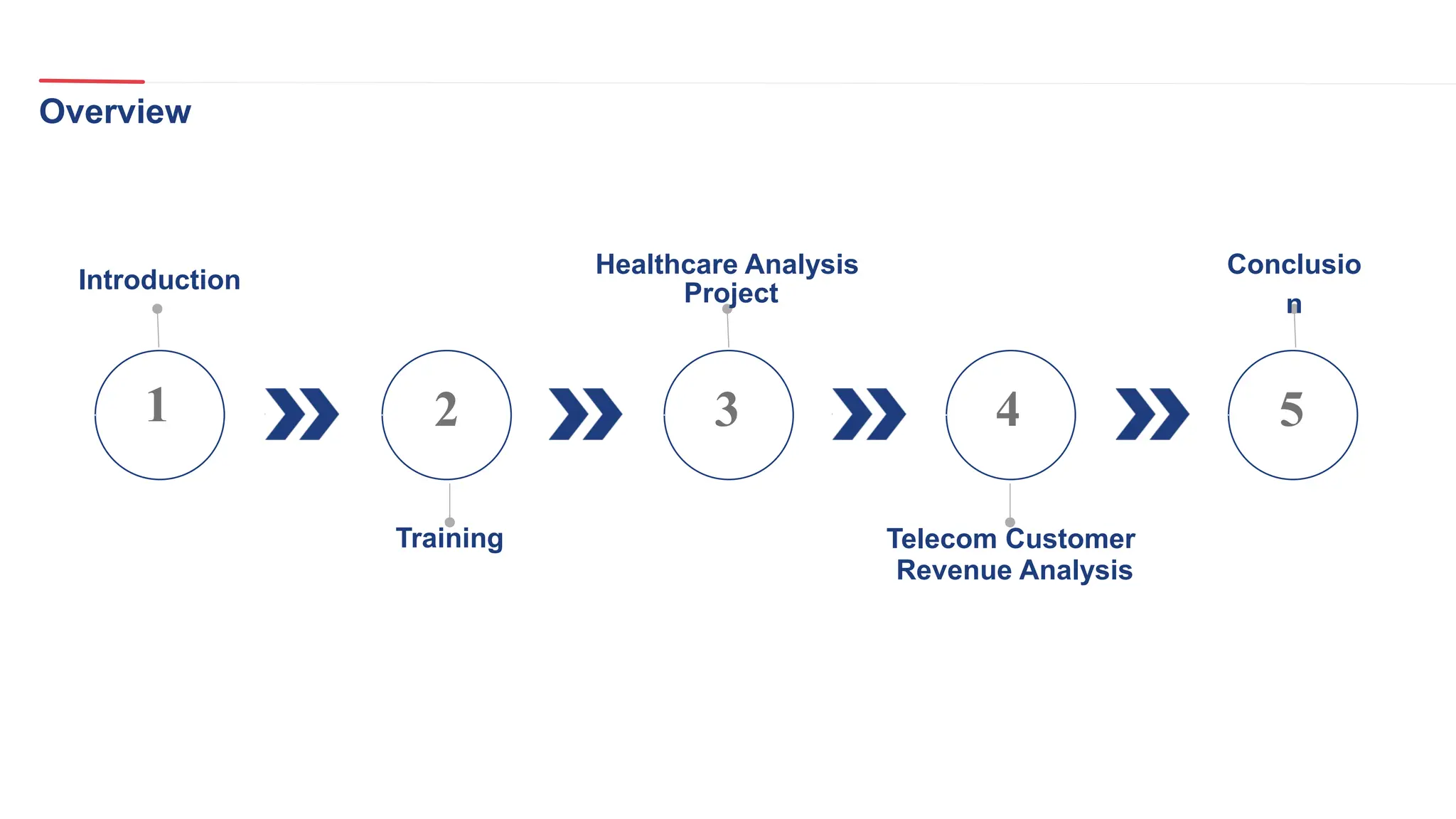
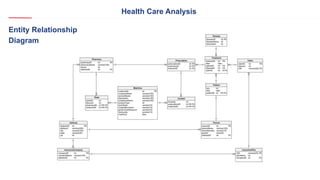
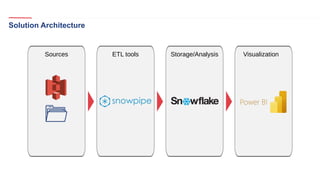
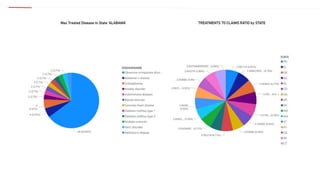
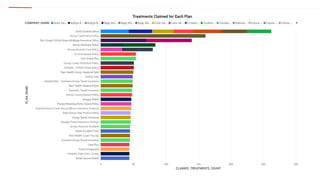
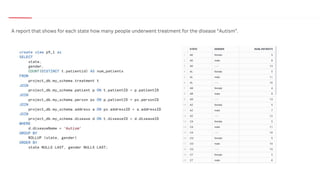
The document outlines a healthcare and telecom revenue analysis project focusing on data engineering practices, including data extraction, transformation, and loading (ETL) processes utilizing tools like Python, Snowflake, and Apache Spark. It details the workflow for analyzing customer behavior and financial insights, employing technologies for real-time data processing and analytics. A comprehensive approach to data management is highlighted, emphasizing both monitoring and reporting capabilities to improve decision-making across industries.






























![[IJCT-V3I2P32] Authors: Amarbir Singh, Palwinder Singh](https://cdn.slidesharecdn.com/ss_thumbnails/ijct-v3i2p32-160609071950-thumbnail.jpg?width=640&height=640&fit=bounds)



















![[Deck] What's New in Spark-Iceberg Integration via DSV2.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/deckwhatsnewinspark-icebergintegrationviadsv2-260210005337-25955b12-thumbnail.jpg?width=640&height=640&fit=bounds)







