Download to read offline













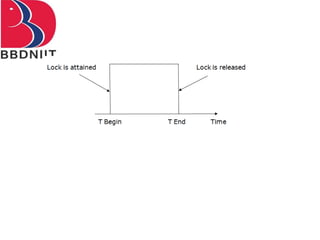

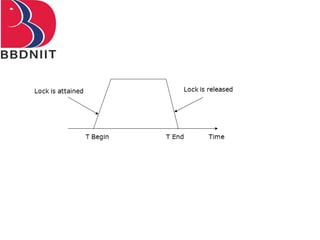

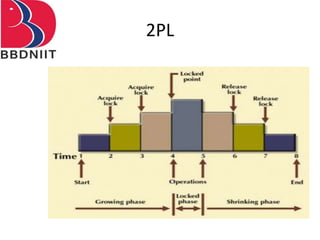
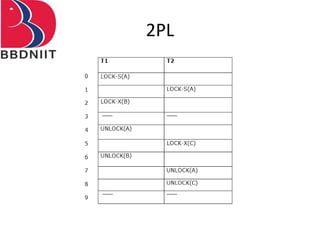


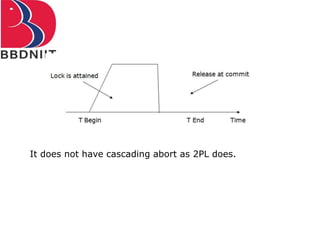






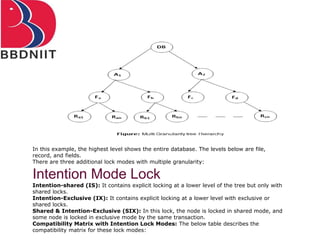







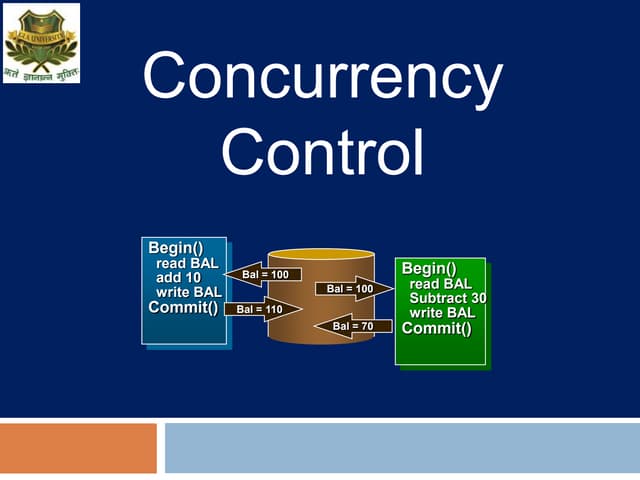
The document discusses concurrency control techniques in database management systems, highlighting problems such as lost updates, dirty reads, and unrepeatable reads. It explains several protocols for concurrency control, including lock-based, timestamp ordering, and validation-based protocols, each with its unique methods for ensuring transaction integrity and consistency. Additionally, it defines concepts like multiple granularity and checkpoints to facilitate recovery during concurrent transactions.