Download as PDF, PPTX



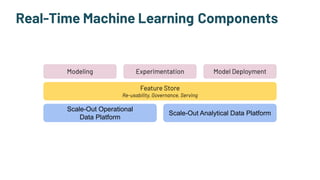
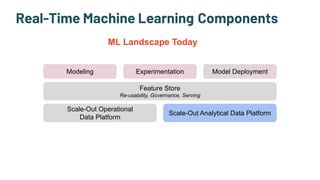
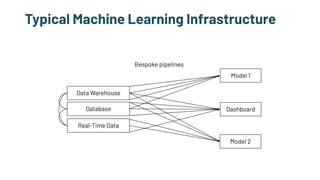


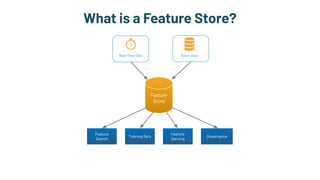
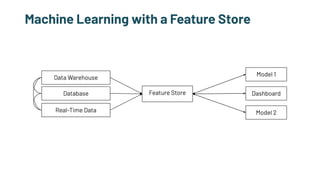

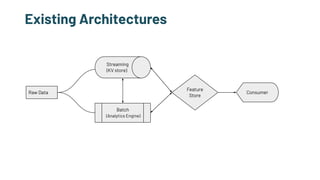
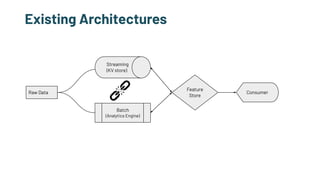
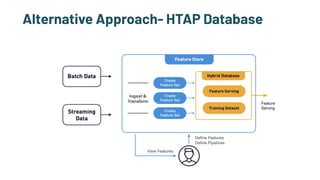

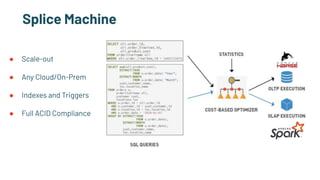
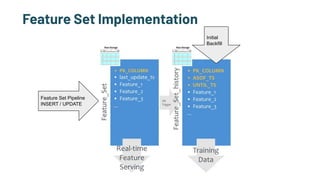


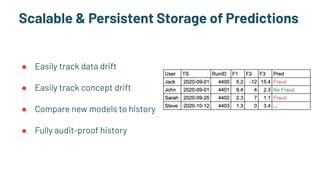
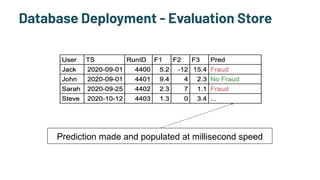
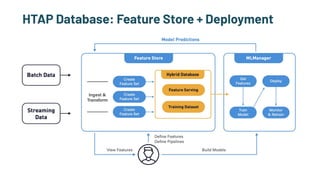
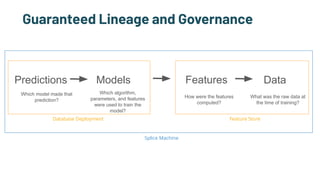


The document discusses the challenges and solutions in production machine learning, emphasizing the significance of feature stores for model deployment and governance. It outlines key requirements for an effective feature store and presents Splice Machine's approach, highlighting scalability, speed, and compliance. The presentation also addresses the limitations of traditional pipelines and the need for a unified operational data platform.























































































