Download as PDF, PPTX








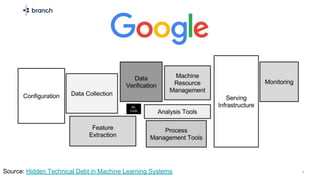
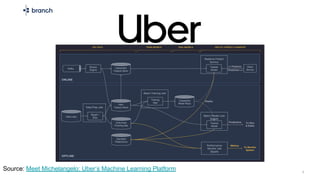
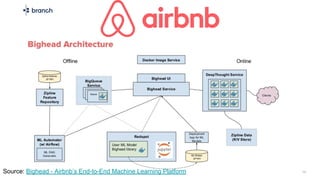

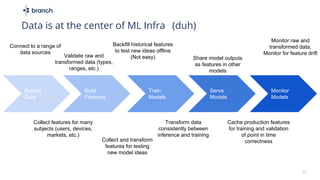



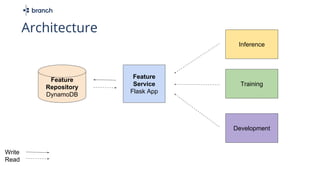
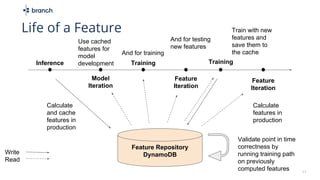


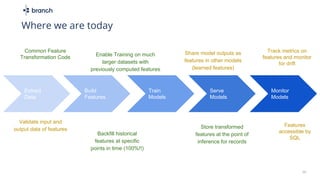






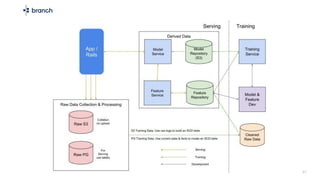

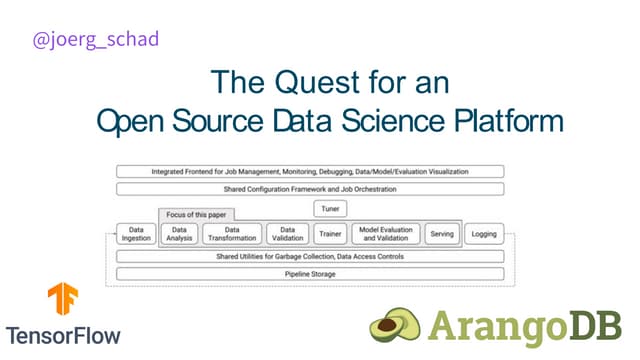
The document discusses the challenges of building machine learning infrastructure for early-stage feature services, emphasizing that existing public solutions are inadequate. It outlines the importance of feature services in managing ML data, includes steps for development, and highlights key components like feature repositories and computation engines. Predictions indicate that feature stores will become central to machine learning infrastructure within three years.