Download as PDF, PPTX






























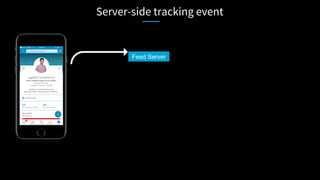
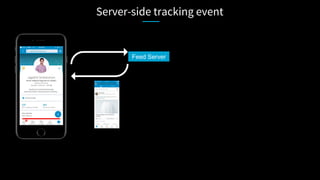
![Server-side tracking event
Feed Server
{
“paginationId”:
“feedUpdates”: [{
“updateUrn”: “update1”
“trackingId”:
“position”:
“creationTime”:
“numLikes”:
“numComments”:
“comments”: [
{“commentId”: }
]
}, {
“updateUrn”:“update2”
“trackingId”:
..
}
Rich payload](https://image.slidesharecdn.com/apachecon-talk-jagadish-1-170523162431/85/ApacheCon-BigData-What-it-takes-to-process-a-trillion-events-a-day-57-320.jpg)
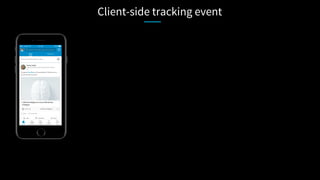
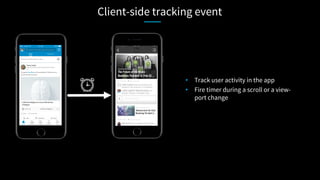
![Client-side tracking event
“feedImpression”: {
“urn”:
“trackingId”:
“duration”:
“height”:
}, {
“urn”:
“trackingId”:
} ,]
• Light pay load
• Bandwidth friendly
• Battery friendly](https://image.slidesharecdn.com/apachecon-talk-jagadish-1-170523162431/85/ApacheCon-BigData-What-it-takes-to-process-a-trillion-events-a-day-60-320.jpg)
![Join client-side event with server-side event
“FEED_IMPRESSION”: {
“trackingId”: “abc”
“duration”: “100”
“height”: “50”
}, {
“trackingId”:
} ,]
“FEED_SERVED”: {
“paginationId”:
“feedUpdates”: [{
“updateUrn”: “update1”
“trackingId”: “abc”
“position”:
“creationTime”:
“numLikes”:
“numComments”:
“comments”: [
{“commentId”: }
]
}, {
“updateUrn”:“update2”
“trackingId”: “def”
“creationTime”:](https://image.slidesharecdn.com/apachecon-talk-jagadish-1-170523162431/85/ApacheCon-BigData-What-it-takes-to-process-a-trillion-events-a-day-61-320.jpg)
![“FEED_IMPRESSION”: {
“trackingId”: “abc”
“duration”: “100”
“height”: “50”
}, {
“trackingId”:
} ,]
“FEED_SERVED”: {
“paginationId”:
“feedUpdates”: [{
“updateUrn”: “update1”
“trackingId”: “abc”
“position”:
“creationTime”:
“numLikes”:
“numComments”:
“comments”: [
{“commentId”: }
]
}, {
“updateUrn”:“update2”
“trackingId”: “def”
“creationTime”:
“JOINED_EVENT”:{
“paginationId”:
“feedUpdates”: [{
“updateUrn”: “update1”
“trackingId”: “abc”
“duration”: “100”
“height”: “50”
“position”:
“creationTime”:
“numLikes”:
“numComments”:
“comments”: [
{“commentId”: }
]
}
}
Samza Joins client-side event with server-side event](https://image.slidesharecdn.com/apachecon-talk-jagadish-1-170523162431/85/ApacheCon-BigData-What-it-takes-to-process-a-trillion-events-a-day-62-320.jpg)
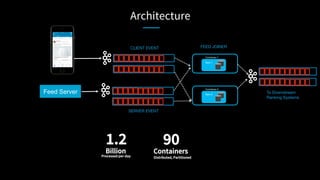








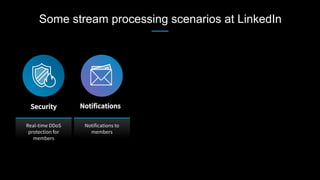
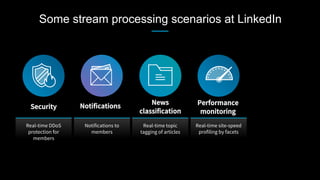
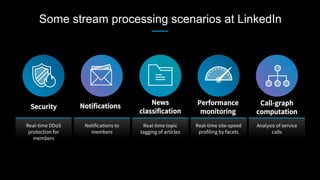
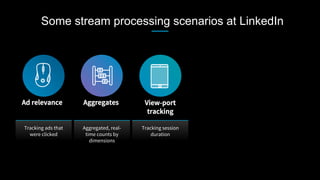
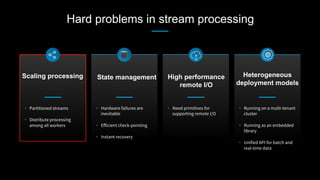
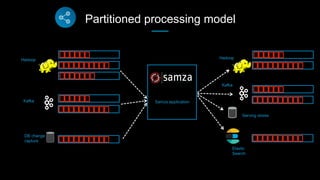
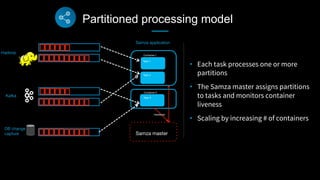
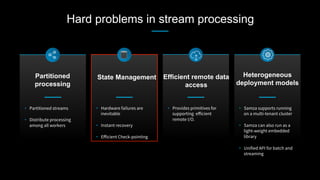
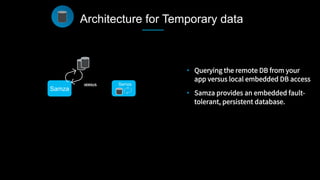
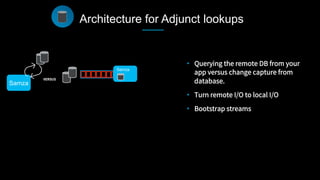
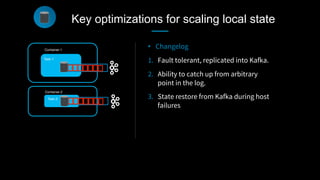
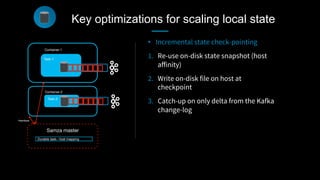
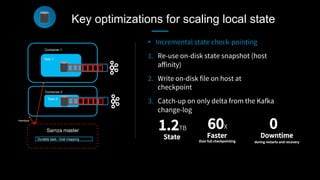
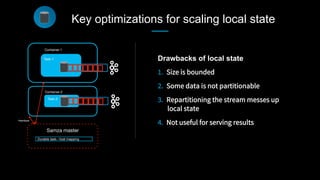
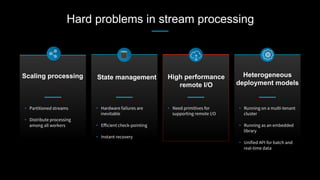
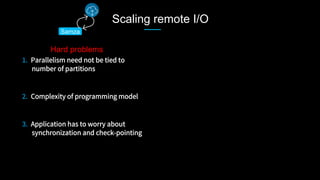
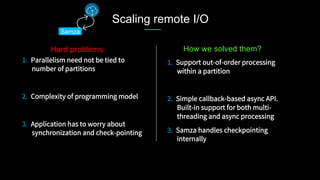
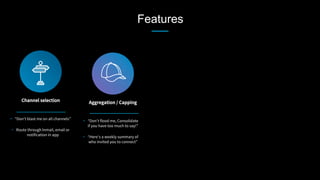
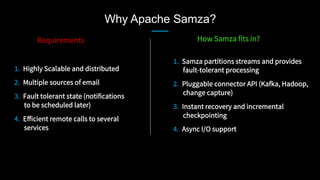
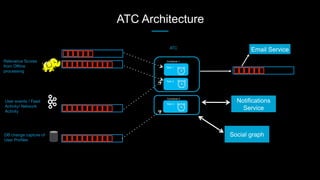
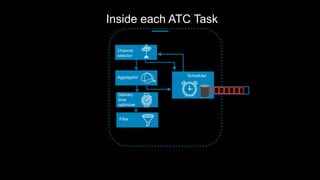
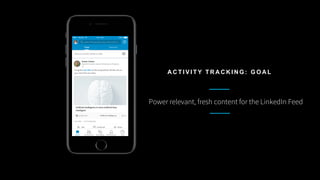
This document discusses stream processing at LinkedIn and summarizes two case studies: 1. LinkedIn's communications platform processes over a trillion events per day using Apache Samza for real-time notifications, security monitoring, and other applications. 2. Activity tracking in the News Feed uses stream processing to track metrics like ads clicked and session durations in real-time for hundreds of applications across LinkedIn. 3. The document also outlines some of the hard problems in stream processing like state management, remote I/O, and deployment models that Samza addresses through techniques such as local state caching, asynchronous remote access, and running on YARN or embedded.


































































