This document summarizes research on sparse representations by Joel Tropp. It discusses how sparse approximation problems arise in applications like variable selection in regression and seismic imaging. It presents algorithms for solving sparse representation problems, including orthogonal matching pursuit and 1-minimization. It analyzes when these algorithms can recover sparse solutions and proves performance guarantees for random matrices and random sparse vectors. The document also discusses related areas like compressive sampling and simultaneous sparsity.









![Variable Selection in Regression
l The oldest application of sparse approximation is linear regression
l The columns of Φ are explanatory variables
l The right-hand side b is the response variable
l Φx is a linear predictor of the response
l Want to use few explanatory variables
l Reduces variance of estimator
l Limits sensitivity to noise
Reference: [Miller 2002]
Sparse Representations (Numerical Analysis Seminar, NYU, 20 April 2007) 9](https://image.slidesharecdn.com/tro07-sparse-solutions-talk-110519000357-phpapp01/85/Tro07-sparse-solutions-talk-9-320.jpg)
![Seismic Imaging
"In deconvolving any observed seismic trace, it is
rather disappointing to discover that there is a
nonzero spike at every point in time regardless of the
data sampling rate. One might hope to find spikes only
where real geologic discontinuities take place."
References: [Claerbout–Muir 1973]
Sparse Representations (Numerical Analysis Seminar, NYU, 20 April 2007) 10](https://image.slidesharecdn.com/tro07-sparse-solutions-talk-110519000357-phpapp01/85/Tro07-sparse-solutions-talk-10-320.jpg)
![Transform Coding
l Transform coding can be viewed as a sparse approximation problem
DCT
−−
−→
IDCT
←−−
−−
Reference: [Daubechies–DeVore–Donoho–Vetterli 1998]
Sparse Representations (Numerical Analysis Seminar, NYU, 20 April 2007) 11](https://image.slidesharecdn.com/tro07-sparse-solutions-talk-110519000357-phpapp01/85/Tro07-sparse-solutions-talk-11-320.jpg)

![Sparse Representation is Hard
Theorem 2. [Davis (1994), Natarajan (1995)] Any algorithm that
can solve the sparse representation problem for every matrix and
right-hand side must solve an NP-hard problem.
Sparse Representations (Numerical Analysis Seminar, NYU, 20 April 2007) 13](https://image.slidesharecdn.com/tro07-sparse-solutions-talk-110519000357-phpapp01/85/Tro07-sparse-solutions-talk-13-320.jpg)

![Algorithms for Sparse Representation
l Greedy methods make a sequence of locally optimal choices in hope of
determining a globally optimal solution
l Convex relaxation methods replace the combinatorial sparse
approximation problem with a related convex program in hope that the
solutions coincide
l Other approaches include brute force, nonlinear programming, Bayesian
methods, dynamic programming, algebraic techniques...
Refs: [Baraniuk, Barron, Bresler, Cand`s, DeVore, Donoho, Efron, Fuchs,
e
Gilbert, Golub, Hastie, Huo, Indyk, Jones, Mallat, Muthukrishnan, Rao,
Romberg, Stewart, Strauss, Tao, Temlyakov, Tewfik, Tibshirani, Willsky...]
Sparse Representations (Numerical Analysis Seminar, NYU, 20 April 2007) 15](https://image.slidesharecdn.com/tro07-sparse-solutions-talk-110519000357-phpapp01/85/Tro07-sparse-solutions-talk-15-320.jpg)
![Orthogonal Matching Pursuit (OMP)
Input: The matrix Φ, right-hand side b, and sparsity level m
Initialize the residual r0 = b
For t = 1, . . . , m do
A. Find a column most correlated with the residual:
ωt = arg maxj=1,...,N | rt−1, ϕj |
B. Update residual by solving a least-squares problem:
yt = arg miny b − Φt y 2
rt = b − Φt yt
where Φt = [ϕω1 . . . ϕωt ]
Output: Estimate x(ωj ) = ym(j)
Sparse Representations (Numerical Analysis Seminar, NYU, 20 April 2007) 16](https://image.slidesharecdn.com/tro07-sparse-solutions-talk-110519000357-phpapp01/85/Tro07-sparse-solutions-talk-16-320.jpg)
![1 Minimization
Sparse Representation as a Combinatorial Problem
min x 0 subject to Φx = b (P0)
Relax to a Convex Program
min x 1 subject to Φx = b (P1)
l Any numerical method can be used to perform the minimization
l Projected gradient and interior-point methods seem to work best
References: [Donoho et al. 1999, Figueredo et al. 2007]
Sparse Representations (Numerical Analysis Seminar, NYU, 20 April 2007) 17](https://image.slidesharecdn.com/tro07-sparse-solutions-talk-110519000357-phpapp01/85/Tro07-sparse-solutions-talk-17-320.jpg)
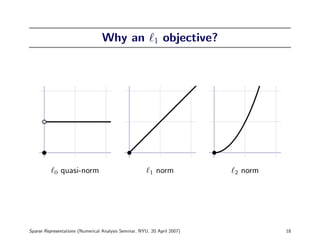
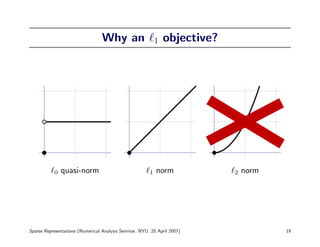



![Finding Sparse Solutions
Theorem 3. [T 2004] Let Φ be incoherent. Suppose that the linear
system Φx = b has a solution x that satisfies
√
1
x 0 < 2 ( d + 1).
Then the vector x is
1. the unique minimal 0 solution to the linear system, and
2. the output of both OMP and 1 minimization.
References: [Donoho–Huo 2001, Greed is Good, Just Relax]
Sparse Representations (Numerical Analysis Seminar, NYU, 20 April 2007) 25](https://image.slidesharecdn.com/tro07-sparse-solutions-talk-110519000357-phpapp01/85/Tro07-sparse-solutions-talk-25-320.jpg)


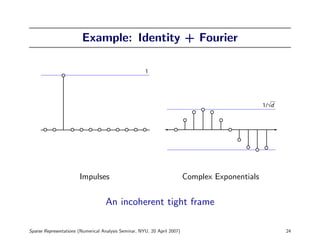
![Conditioning of Random Submatrices
Theorem 4. [T 2006] Let Φ be an incoherent tight frame with at least
twice as many columns as rows. Suppose that
cd
m ≤ .
log d
If A is a random m-column submatrix of Φ then
1
Prob A∗ A − I < ≥ 99.44%.
2
The number c is a positive absolute constant.
Reference: [Random Subdictionaries]
Sparse Representations (Numerical Analysis Seminar, NYU, 20 April 2007) 28](https://image.slidesharecdn.com/tro07-sparse-solutions-talk-110519000357-phpapp01/85/Tro07-sparse-solutions-talk-28-320.jpg)
![Recovering Random Sparse Vectors
Model (M) for b = Φx
The matrix Φ is an incoherent tight frame
Nonzero entries of x number m ≤ cd/ log N
have uniformly random positions
are independent, zero-mean Gaussian RVs
Theorem 5. [T 2006] Let b = Φx be a random vector drawn according
to Model (M). Then x is
1. the unique minimal 0 solution w.p. at least 99.44% and
2. the unique minimal 1 solution w.p. at least 99.44%.
Reference: [Random Subdictionaries]
Sparse Representations (Numerical Analysis Seminar, NYU, 20 April 2007) 29](https://image.slidesharecdn.com/tro07-sparse-solutions-talk-110519000357-phpapp01/85/Tro07-sparse-solutions-talk-29-320.jpg)



![Compressive Sampling II
14.1
–2.6
–5.3
10.4
3.2
sparse signal ( ) linear measurement process data (b = Φx )
l Given data b = Φx, must identify sparse signal x
l This is a sparse representation problem with a random matrix
References: [Cand`s–Romberg–Tao 2004, Donoho 2004]
e
Sparse Representations (Numerical Analysis Seminar, NYU, 20 April 2007) 33](https://image.slidesharecdn.com/tro07-sparse-solutions-talk-110519000357-phpapp01/85/Tro07-sparse-solutions-talk-33-320.jpg)
![Compressive Sampling and OMP
Theorem 6. [T, Gilbert 2005] Assume that
l x is a vector in RN with m nonzeros and
l Φ is a d × N Gaussian matrix with d ≥ Cm log N
l Execute OMP with b = Φx to obtain estimate x
The estimate x equals the vector x with probability at least 99.44%.
Reference: [Signal Recovery via OMP]
Sparse Representations (Numerical Analysis Seminar, NYU, 20 April 2007) 34](https://image.slidesharecdn.com/tro07-sparse-solutions-talk-110519000357-phpapp01/85/Tro07-sparse-solutions-talk-34-320.jpg)
![Compressive Sampling with 1 Minimization
Theorem 7. [Various] Assume that
l Φ is a d × N Gaussian matrix with d ≥ Cm log(N/m)
With probability 99.44%, the following statement holds.
l Let x be a vector in RN with m nonzeros
l Execute 1 minimization with b = Φx to obtain estimate x
The estimate x equals the vector x.
References: [Cand`s et al. 2004–2006], [Donoho et al. 2004–2006],
e
[Rudelson–Vershynin 2006]
Sparse Representations (Numerical Analysis Seminar, NYU, 20 April 2007) 35](https://image.slidesharecdn.com/tro07-sparse-solutions-talk-110519000357-phpapp01/85/Tro07-sparse-solutions-talk-35-320.jpg)

![Sublinear Compressive Sampling
l There are algorithms that can recover sparse signals from random
measurements in time proportional to the number of measurements
l This is an exponential speedup over OMP and 1 minimization
l The cost is a logarithmic number of additional measurements
References: [Algorithmic dimension reduction, One sketch for all]
Joint with Gilbert, Strauss, Vershynin
Sparse Representations (Numerical Analysis Seminar, NYU, 20 April 2007) 37](https://image.slidesharecdn.com/tro07-sparse-solutions-talk-110519000357-phpapp01/85/Tro07-sparse-solutions-talk-37-320.jpg)
![Simultaneous Sparsity
l In some applications, one seeks solutions to the matrix equation
ΦX = B
where X has a minimal number of nonzero rows
l We have studied algorithms for this problem
References: [Simultaneous Sparse Approximation I and II ]
Joint with Gilbert, Strauss
Sparse Representations (Numerical Analysis Seminar, NYU, 20 April 2007) 38](https://image.slidesharecdn.com/tro07-sparse-solutions-talk-110519000357-phpapp01/85/Tro07-sparse-solutions-talk-38-320.jpg)
![Projective Packings
l The coherence statistic plays an important role in sparse representation
l What can we say about matrices Φ with minimal coherence?
l Equivalent to studying packing in projective space
l We have theory about when optimal packings can exist
l We have numerical algorithms for constructing packings
References: [Existence of ETFs, Constructing Structured TFs, . . . ]
Joint with Dhillon, Heath, Sra, Strohmer, Sustik
Sparse Representations (Numerical Analysis Seminar, NYU, 20 April 2007) 39](https://image.slidesharecdn.com/tro07-sparse-solutions-talk-110519000357-phpapp01/85/Tro07-sparse-solutions-talk-39-320.jpg)




































































