Downloaded 37 times









![© Freddie Mac 13
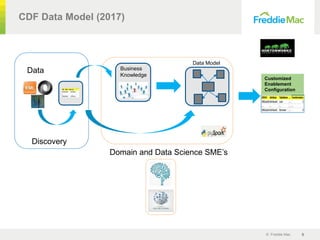
CDF Autogenerated Data Model Prediction
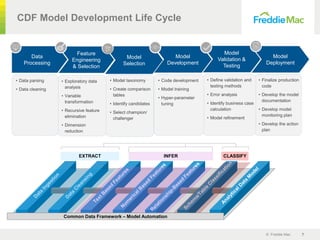
Feature
Extraction
SME Review
and Update
Data
Discovery
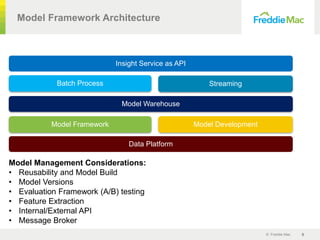
New data for the same business area
/path/to/a AvailableBalance [5400, 6000, 3000, 1500, …]
/path/to/b AssetType [MNMT, …]
Numeric:
• Min, Max
• Mean, STD
• Percentiles
• …
Free-form text:
• Tokenize
• TF-IDF
• …
Path+Name:
• Tokenize
• TF-IDF
• …
Random
Forest
Naïve-
Bayes
Cosine-
similarity
PredictionPrediction
Source Predicted
AvailableBalance AssetAccountBalance
AssetType AccountType](https://image.slidesharecdn.com/freddiemackpmgnewfinal-180622055750/85/Freddie-Mac-KPMG-Case-Study-Advanced-Machine-Learning-Data-Integration-with-Common-Data-Framework-Model-Robot-13-320.jpg)

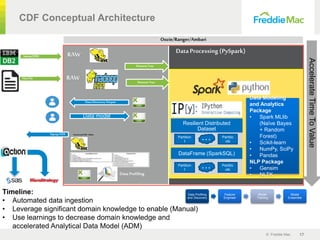


The document outlines the development and implementation of an advanced machine learning data integration framework by Freddie Mac, aiming to automate and enhance the data munging process. The framework, known as 'Model Robot,' seeks to reduce data application implementation time, improving access for data scientists and analysts. By leveraging self-learning AI, the framework aims to create flexible data models that facilitate faster insights and better business decisions within the housing finance system.





![[Slides] Digital Transformation, with Brian Solis](https://cdn.slidesharecdn.com/ss_thumbnails/slidesdigitaltransformationbriansolis-140429142804-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
















































































