Downloaded 20 times





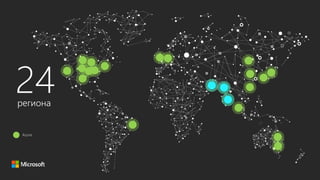
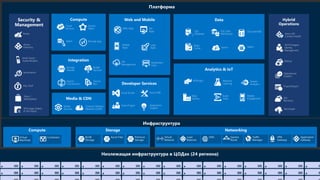

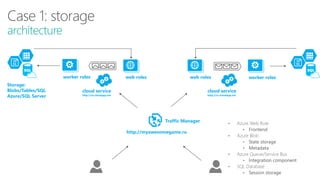

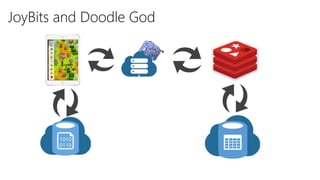
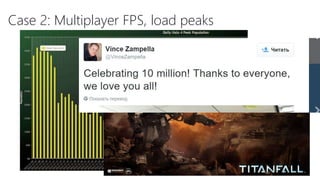

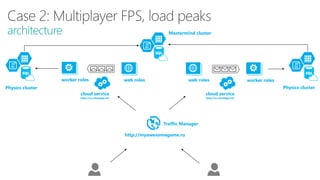
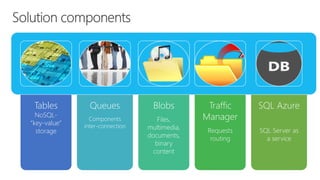

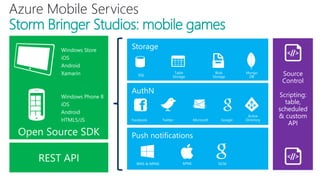
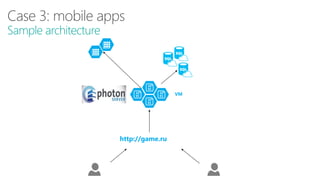
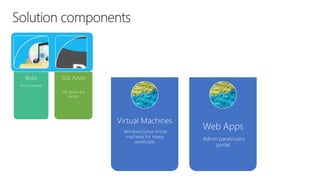

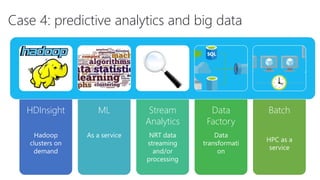
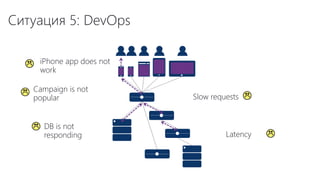

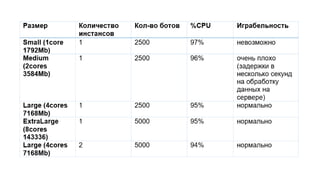





The document discusses using Microsoft Azure cloud services for game development and operations. It provides examples of how games use Azure for scalable storage, global load balancing for multiplayer games, predictive analytics using big data, and DevOps approaches for deployment, monitoring, and development. Key Azure services highlighted include Storage, SQL Database, Virtual Machines, Mobile Services, HDInsight, and Application Insights.















![[Webinar] Getting to Insights Faster: A Framework for Agile Big Data](https://cdn.slidesharecdn.com/ss_thumbnails/agile-big-datav2-131122164332-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






















































































