Download to read offline
























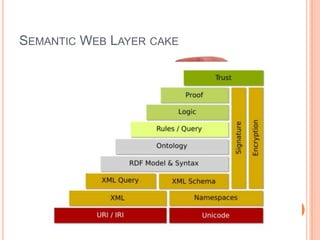


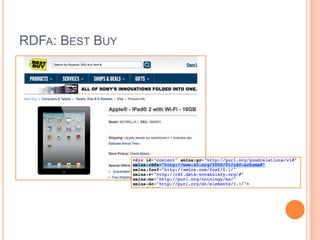
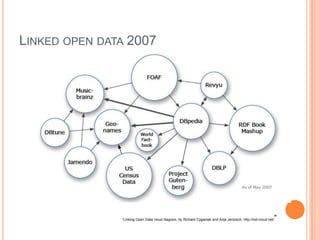




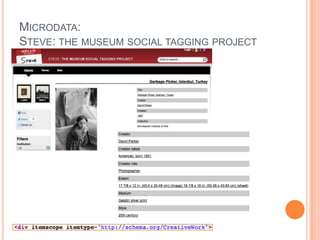

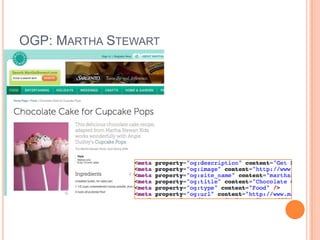
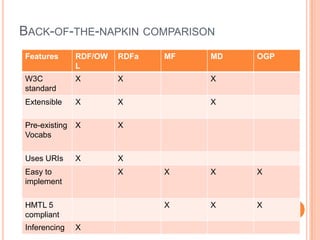





This document discusses the evolving semantic web. It defines the semantic web as making knowledge machine and human-readable by providing context and meaning for information on the web. The semantic web utilizes technologies like URIs, RDF, and OWL to describe relationships between web resources in a machine-readable way. Lighter semantic standards like RDFa, microformats, and microdata are also discussed as easier ways to add semantics to existing web pages. The status and potential future applications of the semantic web are outlined.



































































