

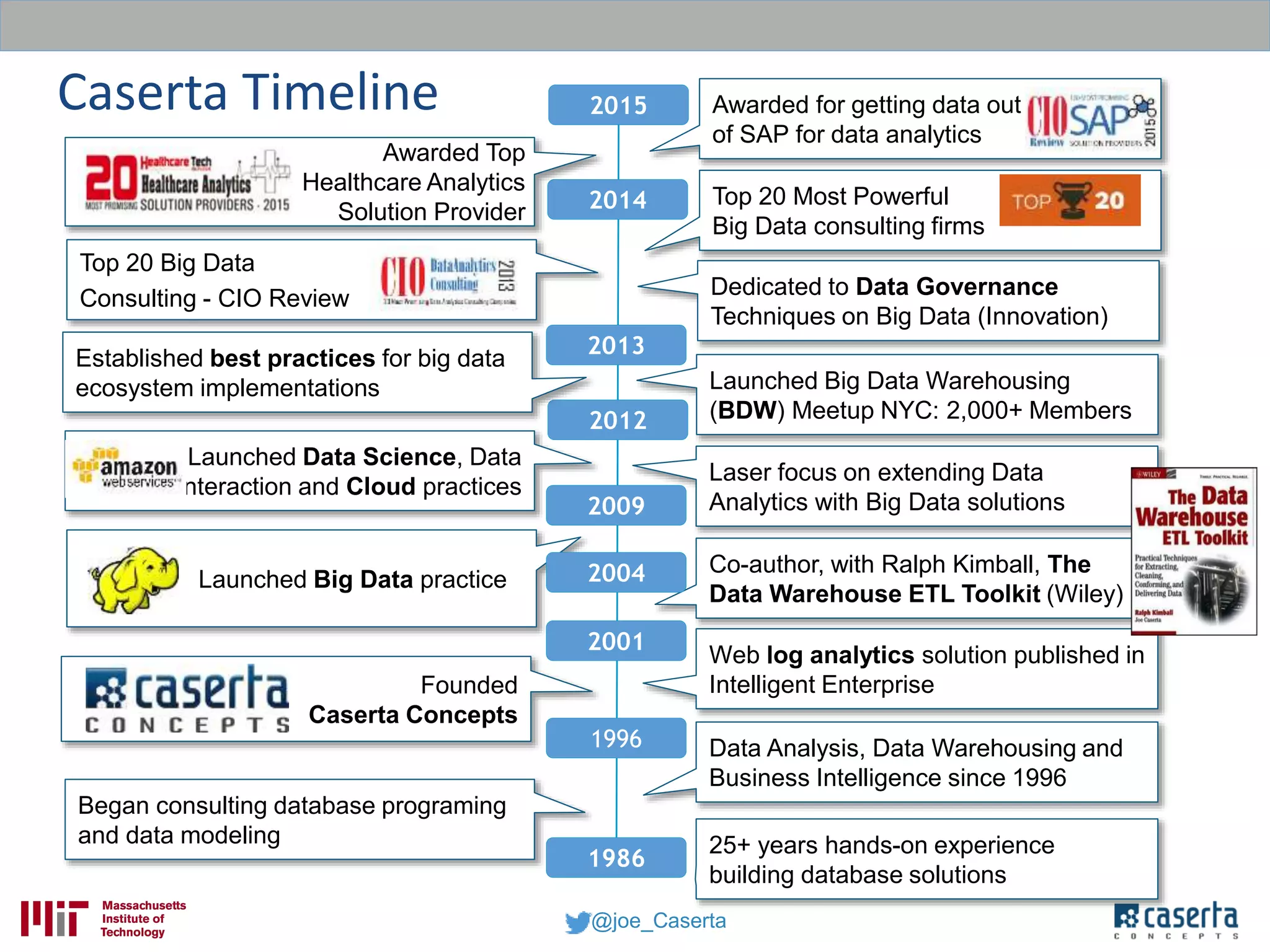









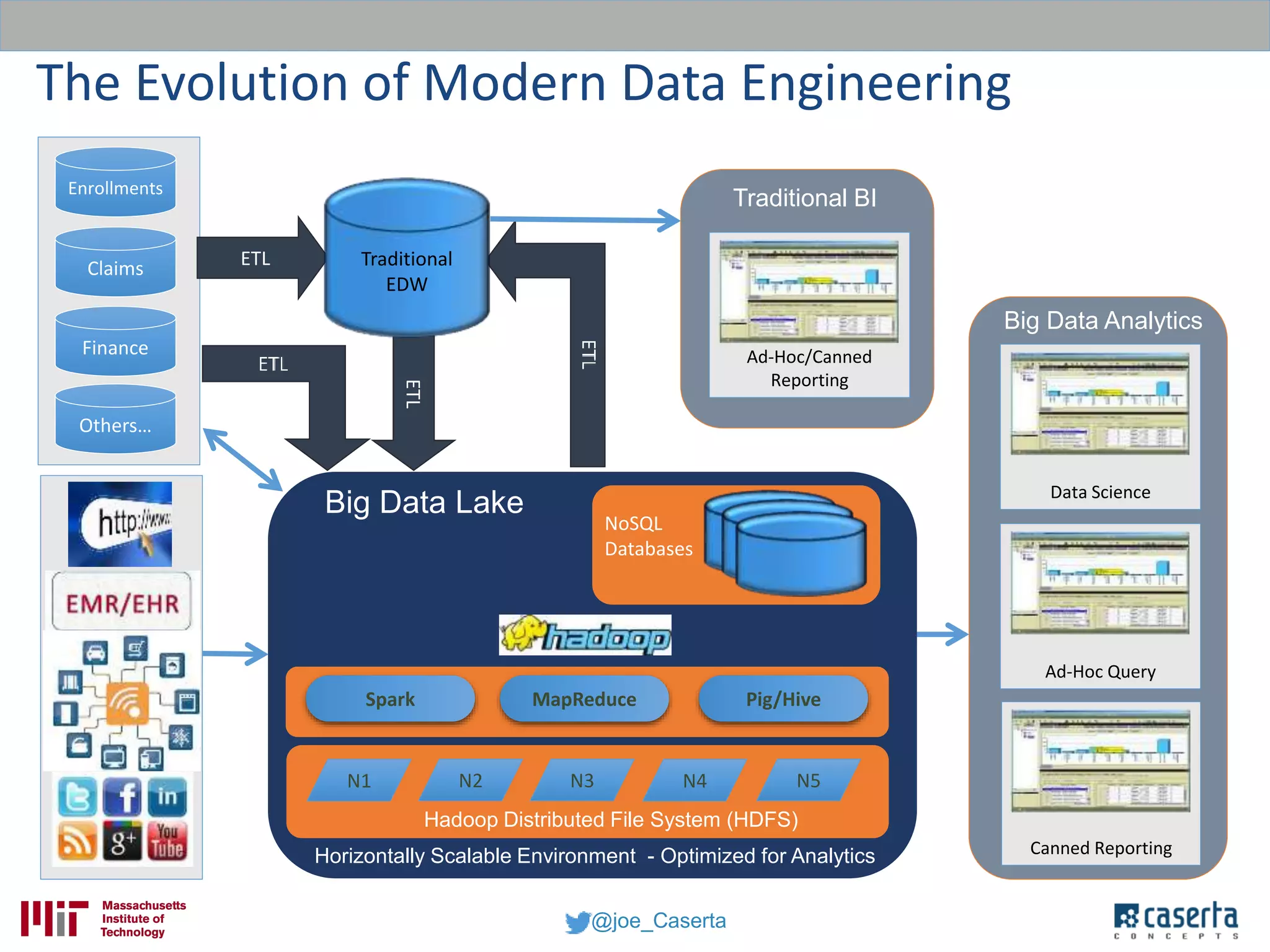
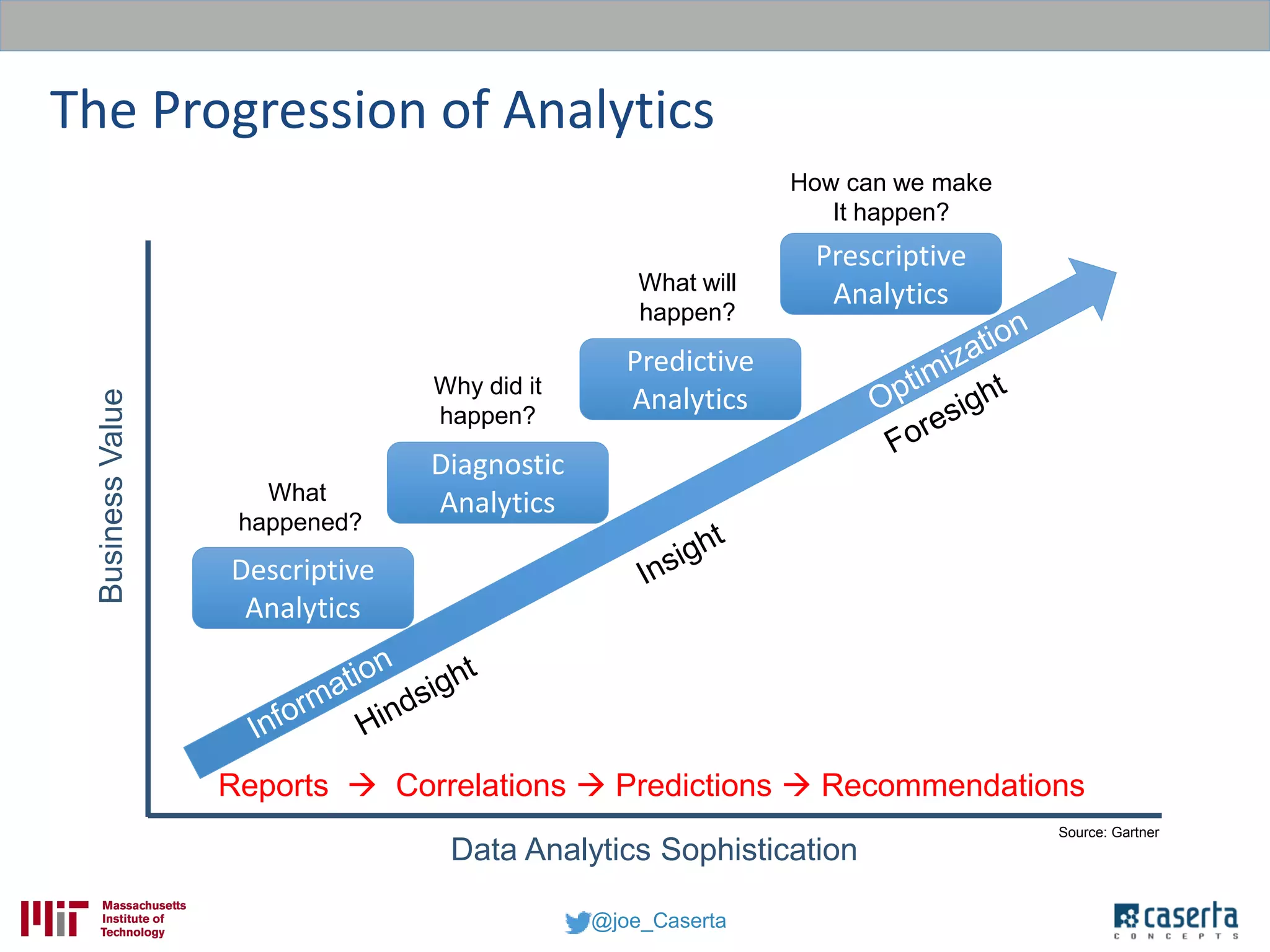


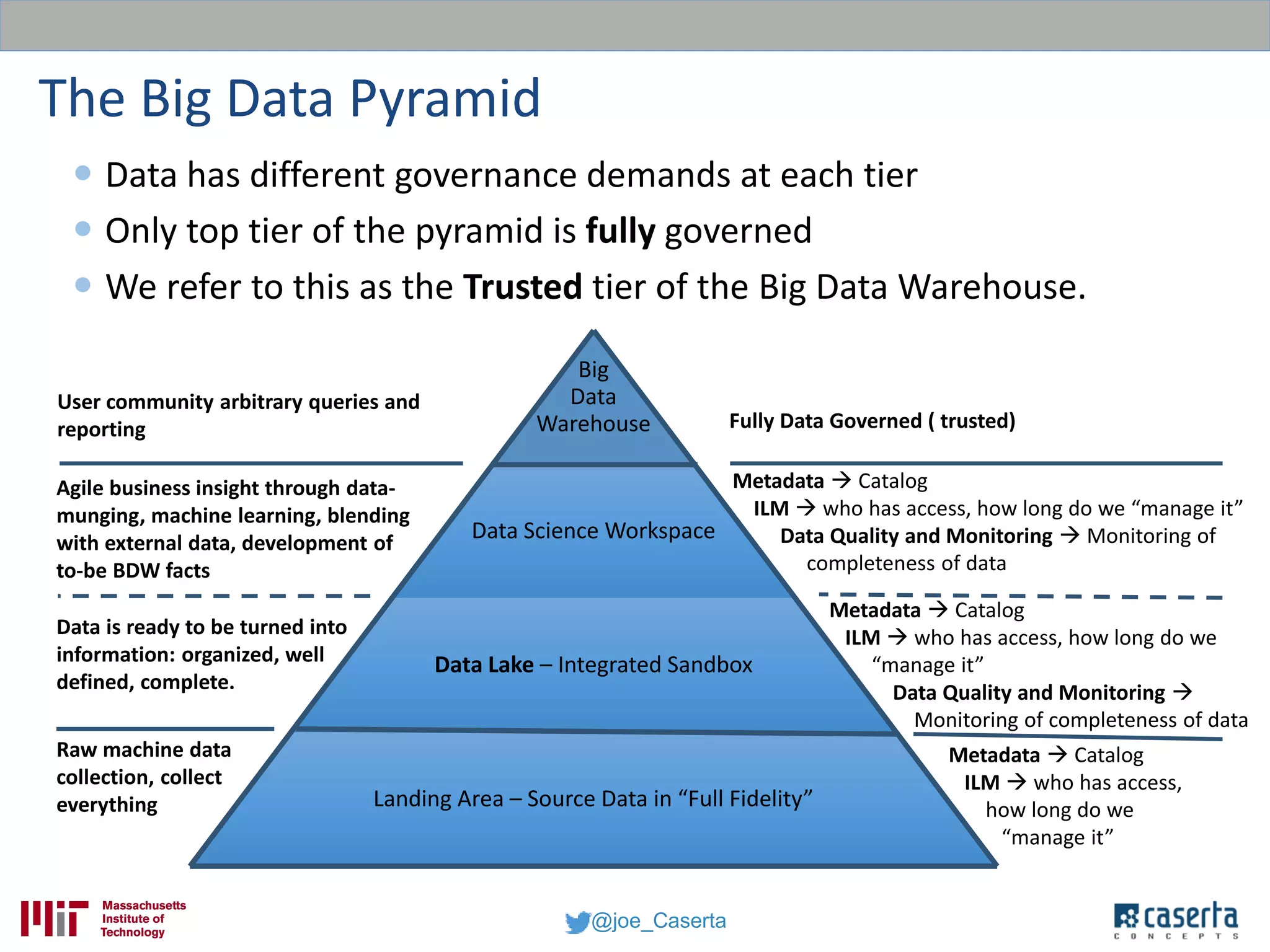
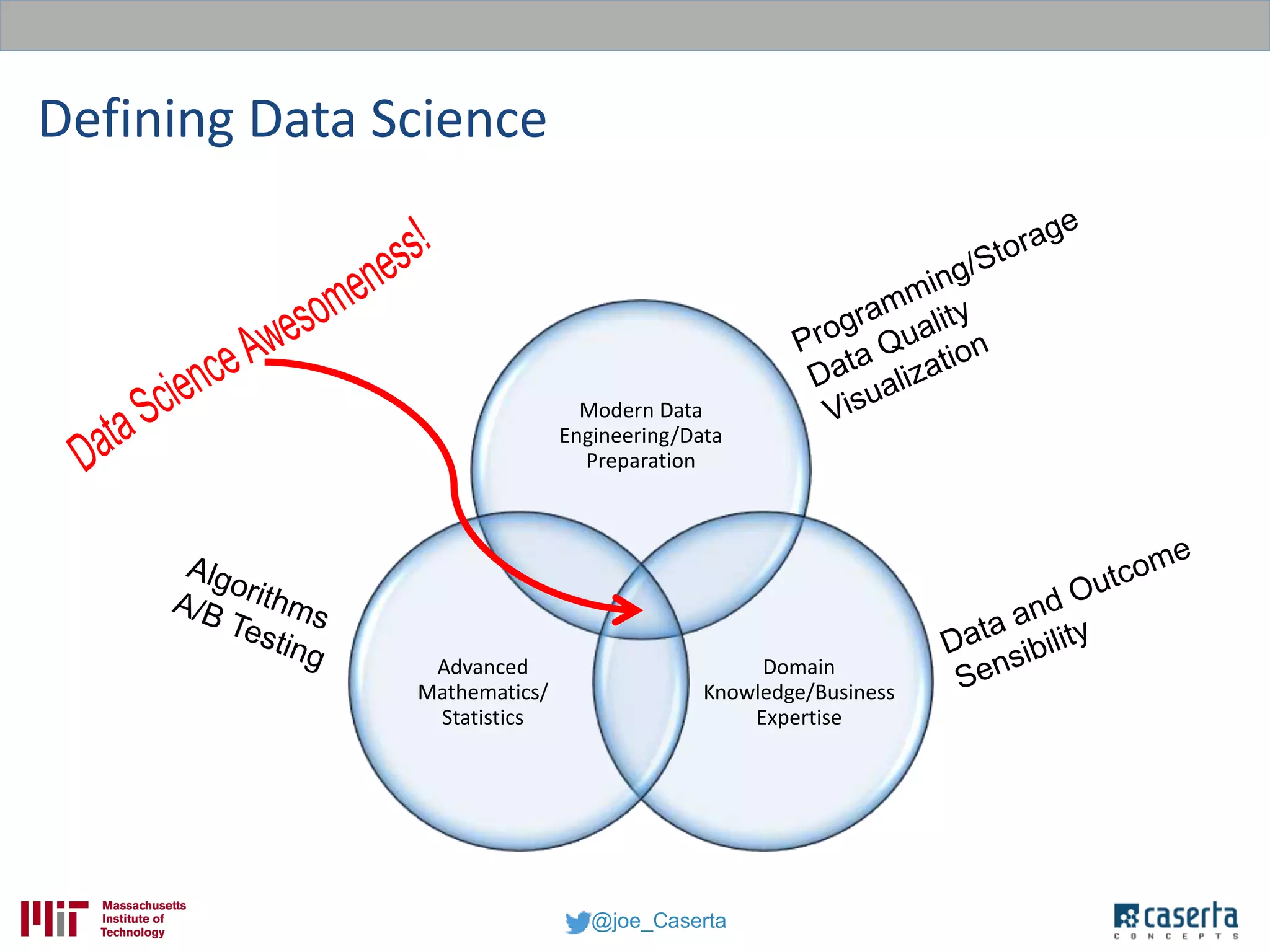

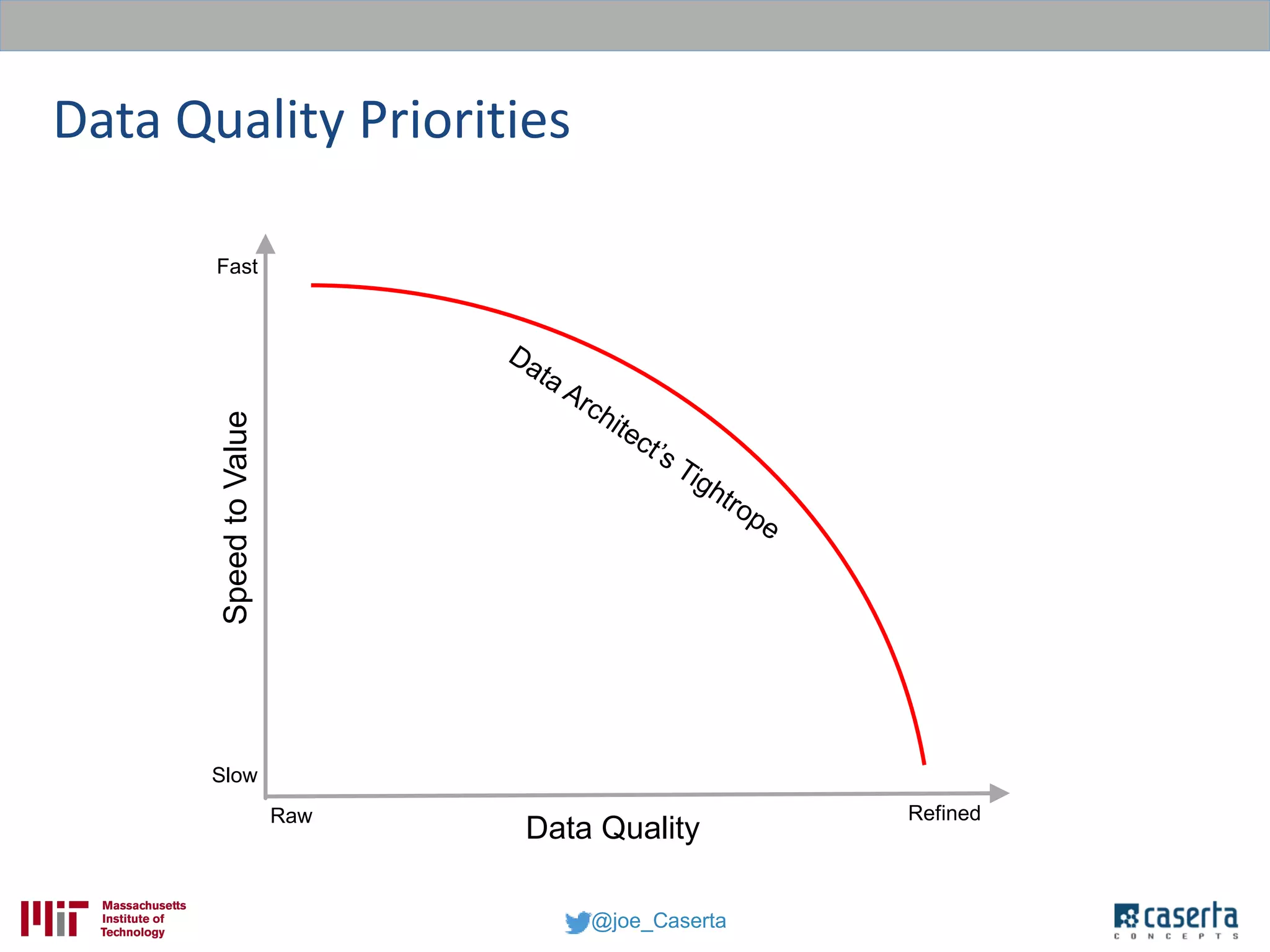




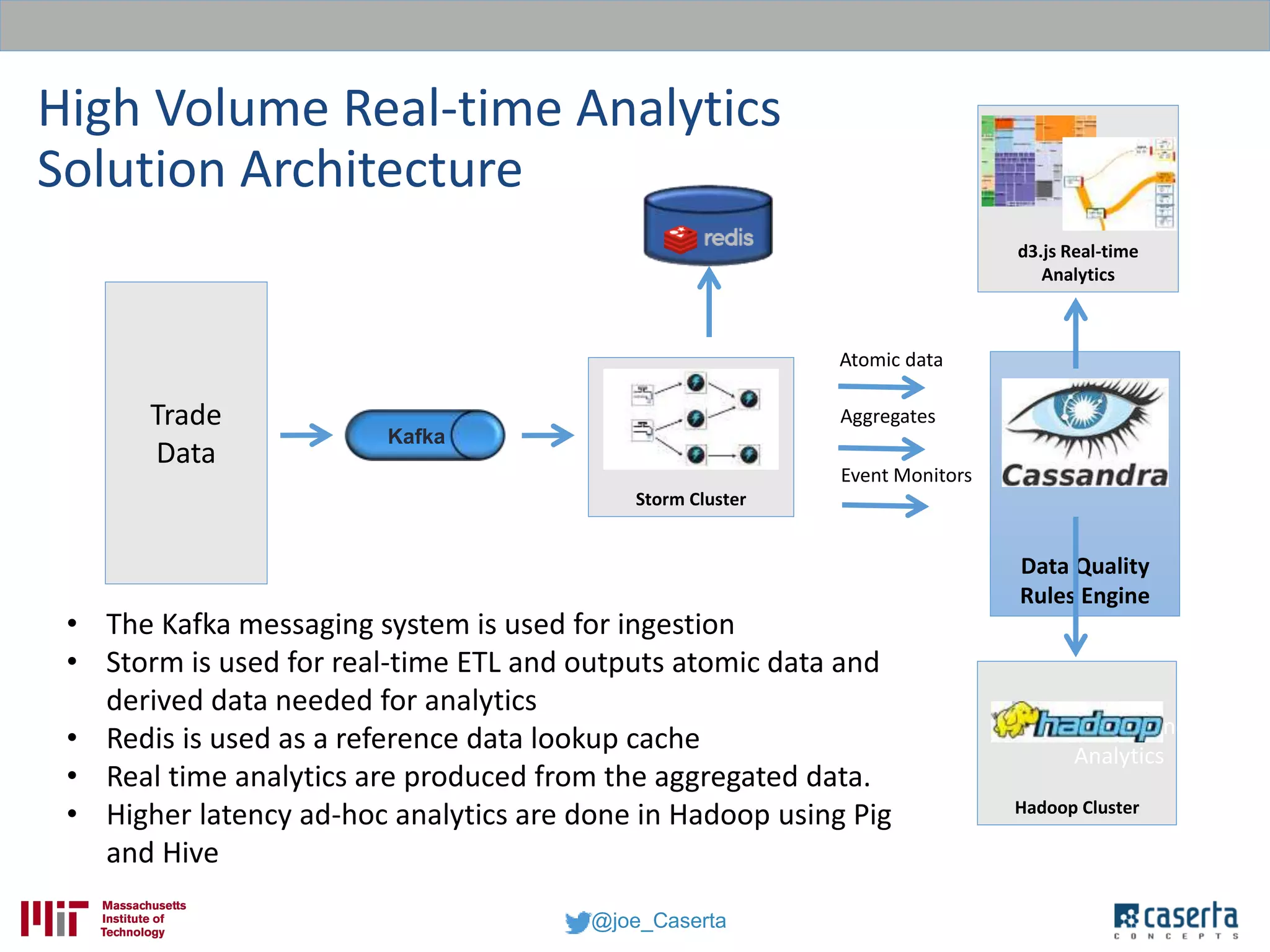
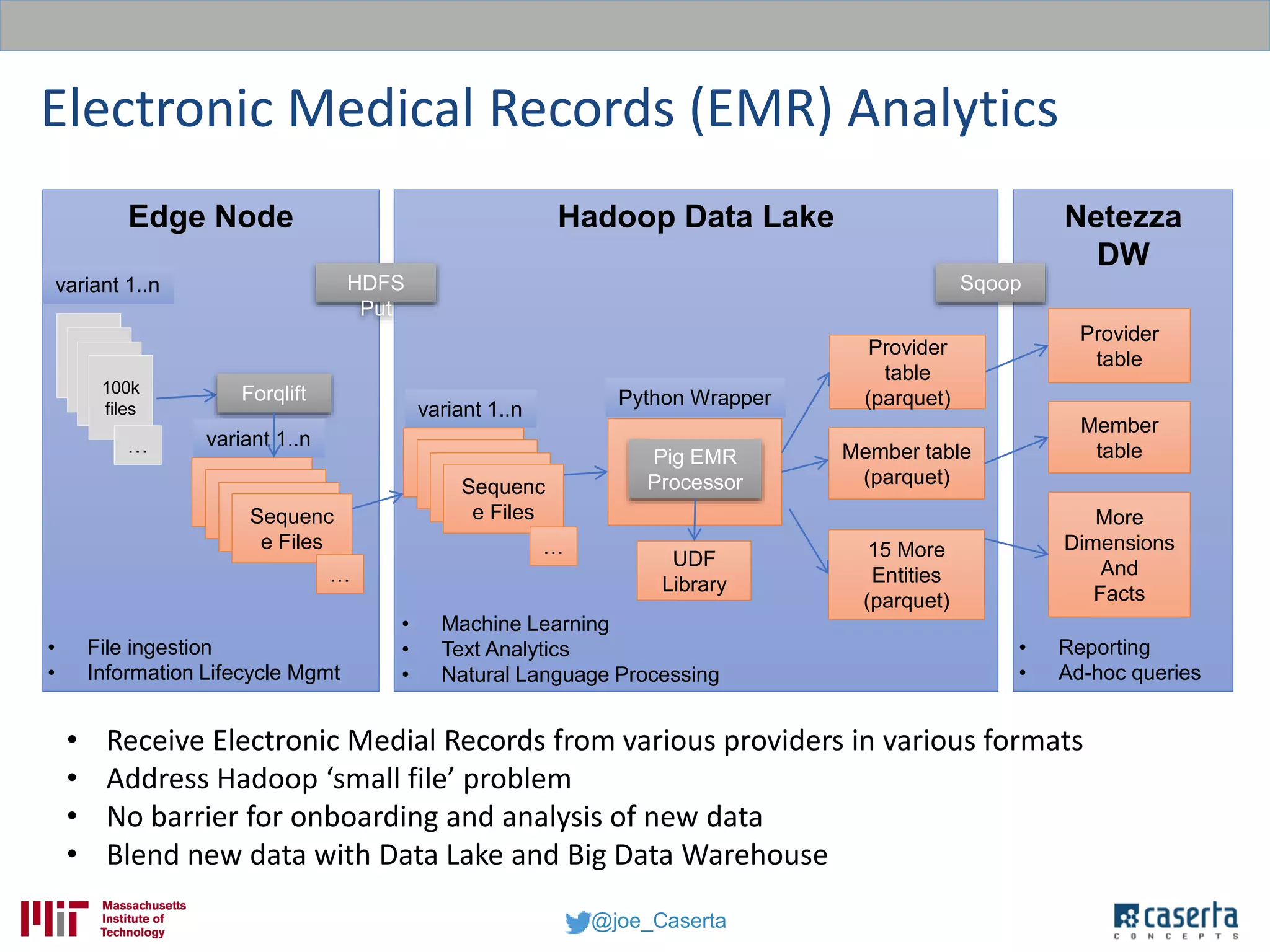





Joe Caserta, founder of Caserta Concepts, specializes in big data solutions, data warehousing, and business intelligence, emphasizing the importance of data governance in modern data practices. The document highlights the evolution of data engineering, the role of data science, and the necessity of maintaining data quality and trustworthiness in big data environments. It also discusses innovation in data analytics and provides examples of successful big data projects in finance and healthcare.
























































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)


