

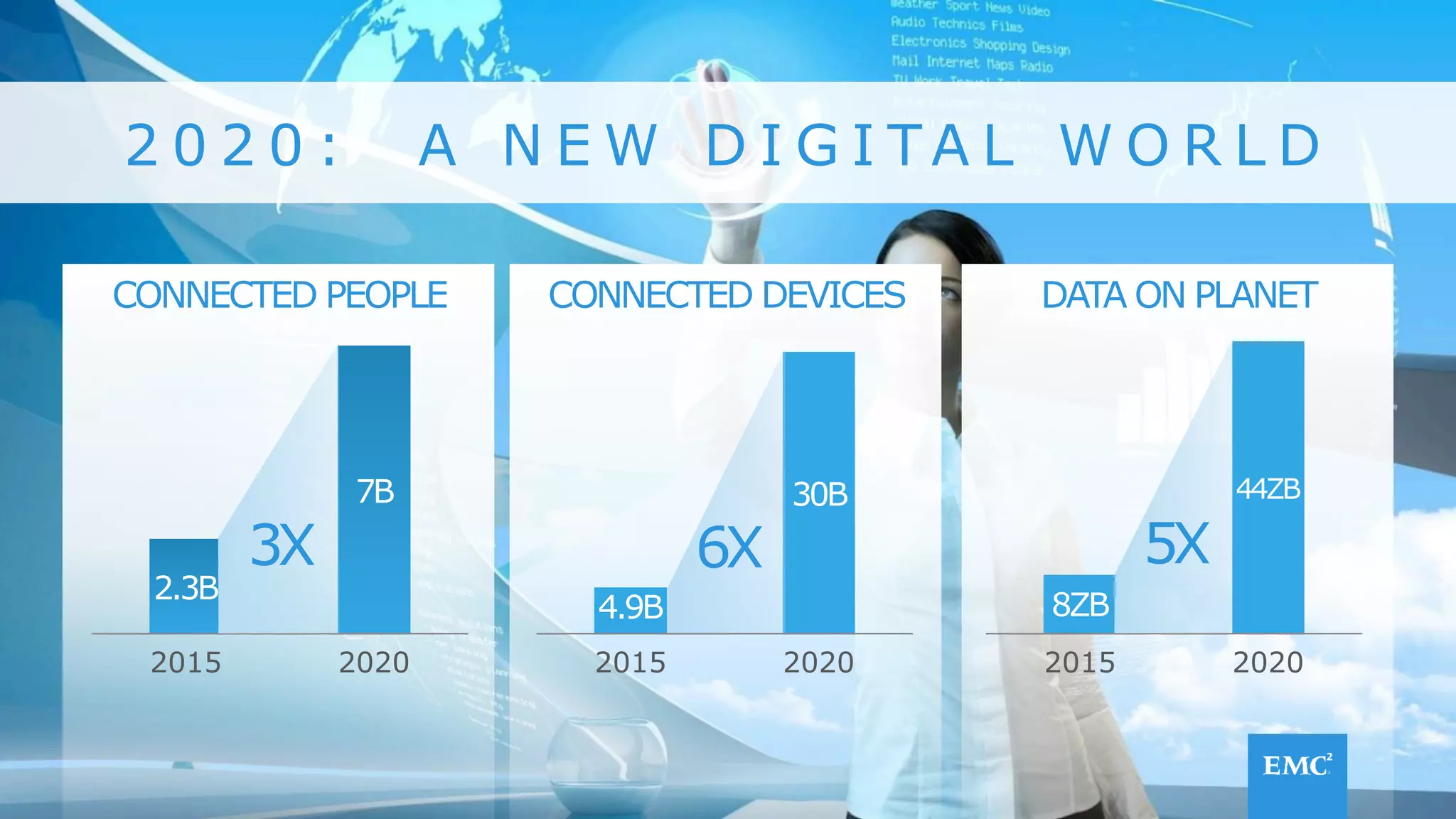


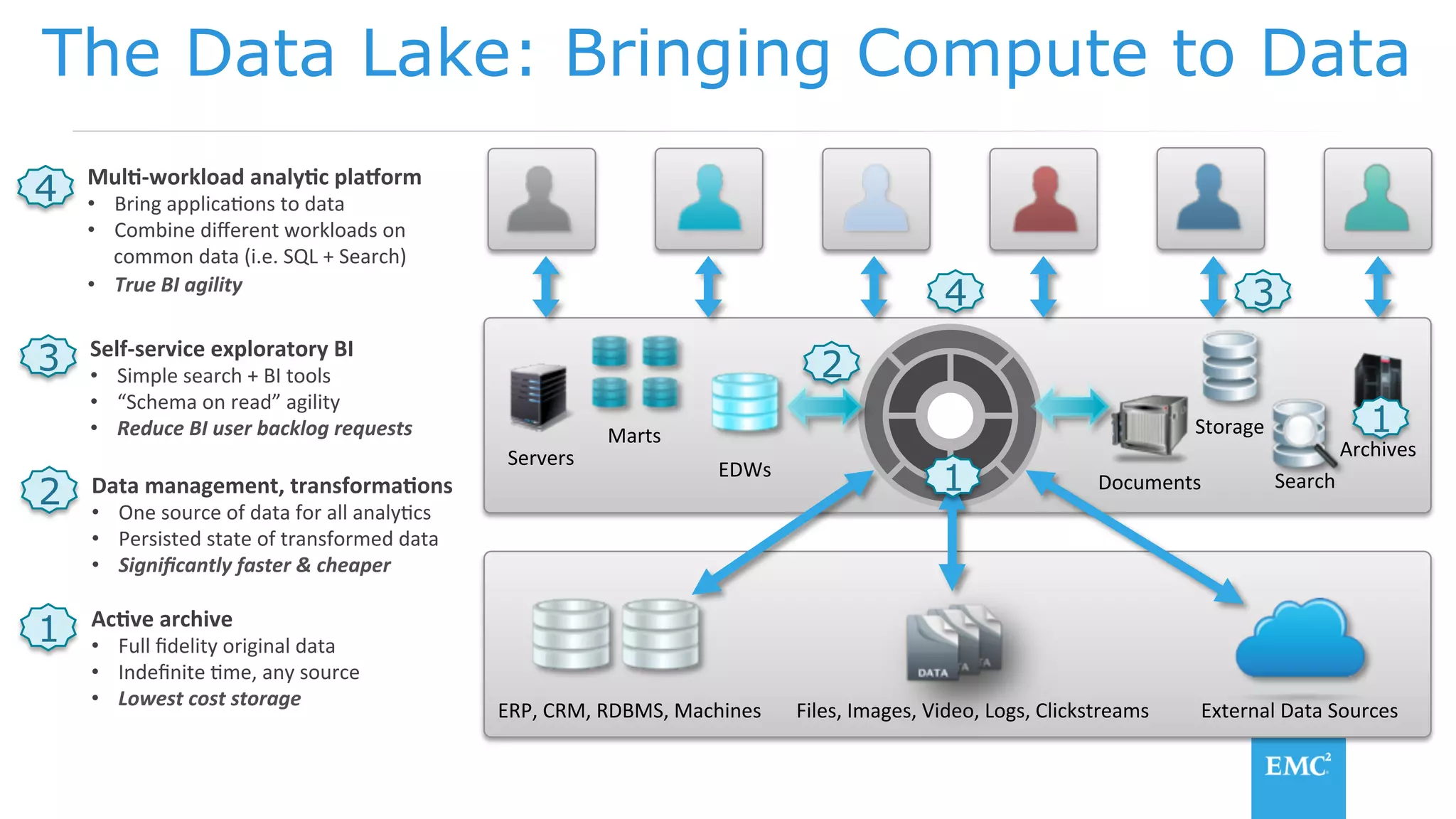


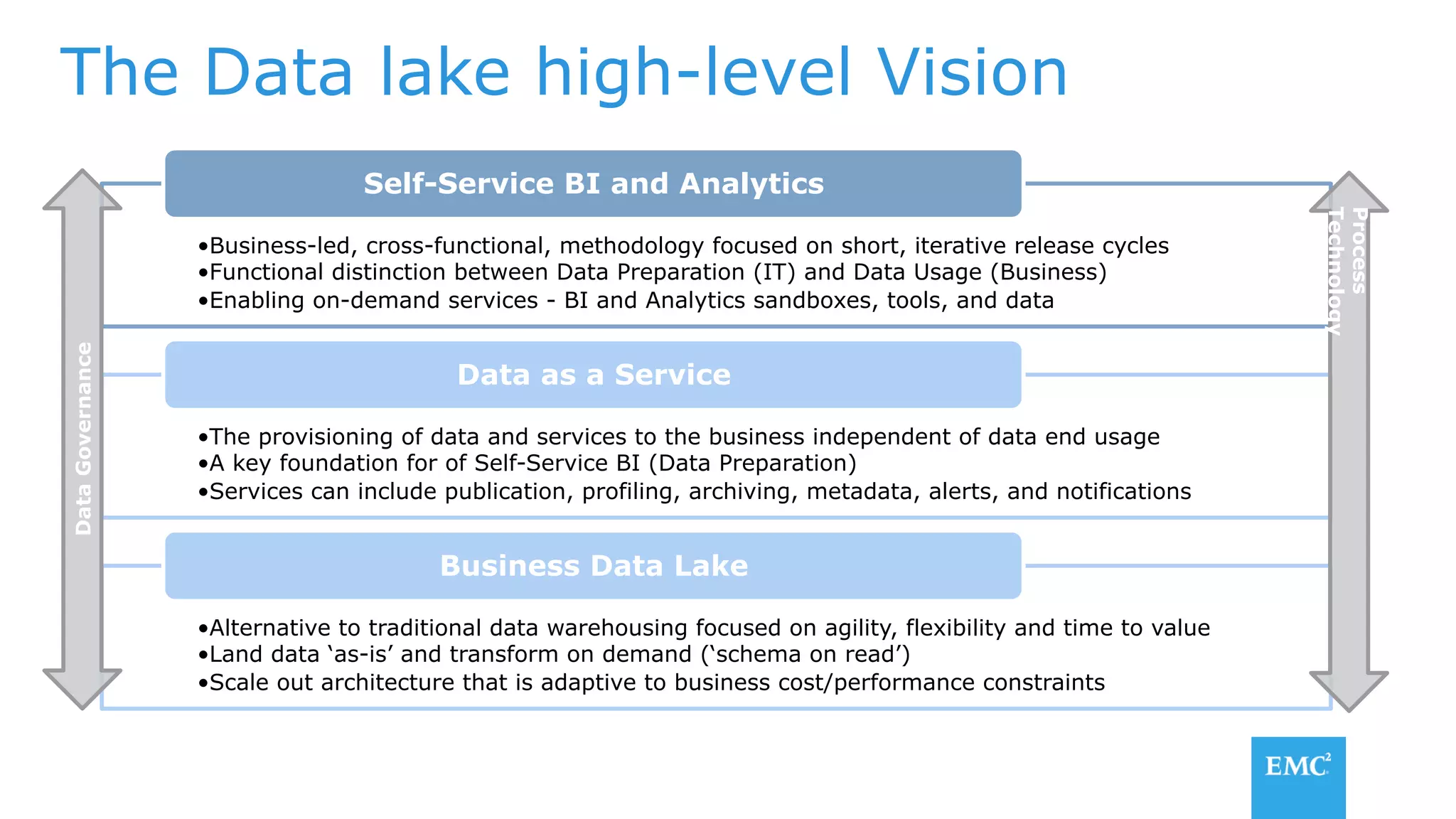
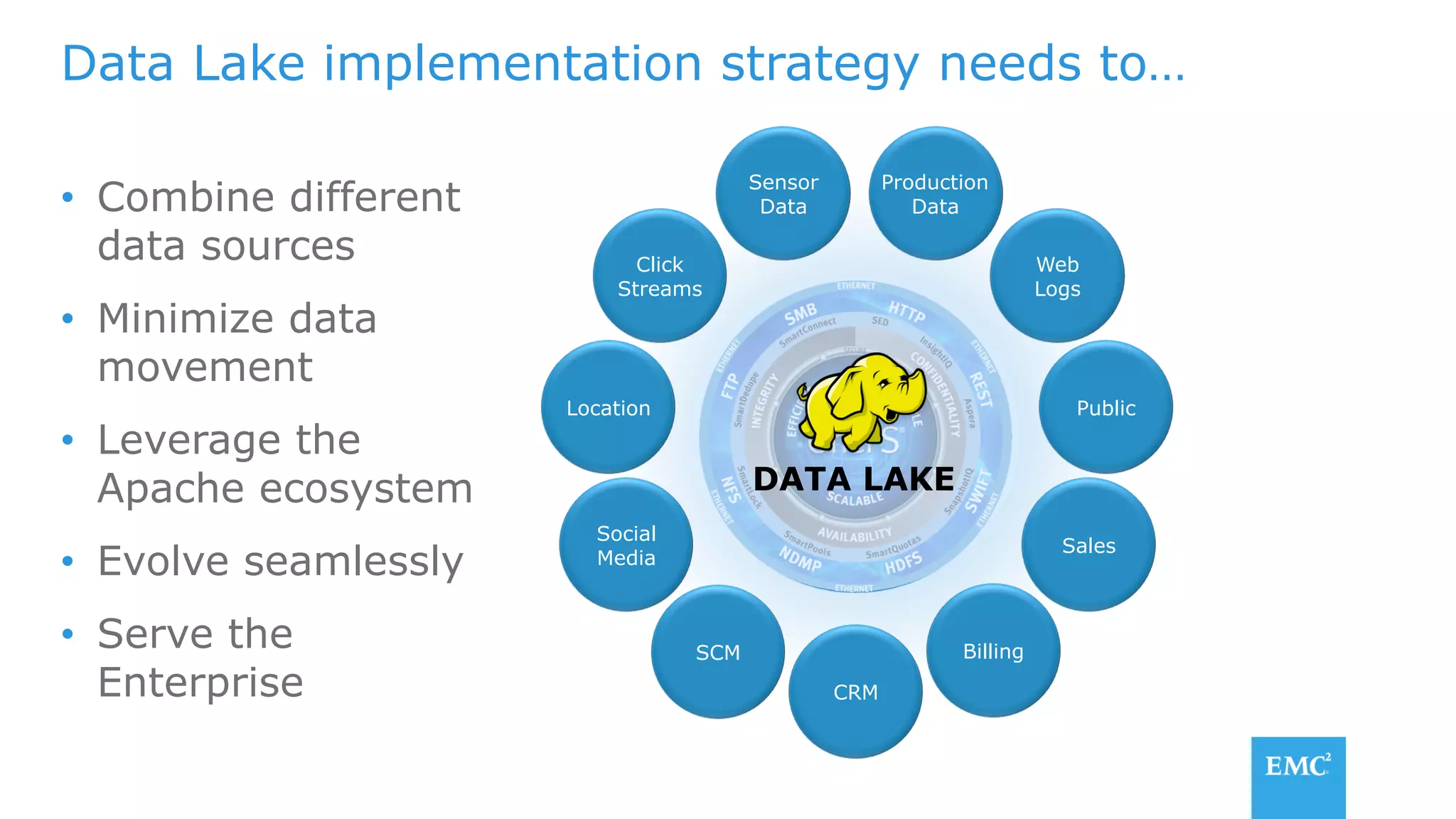
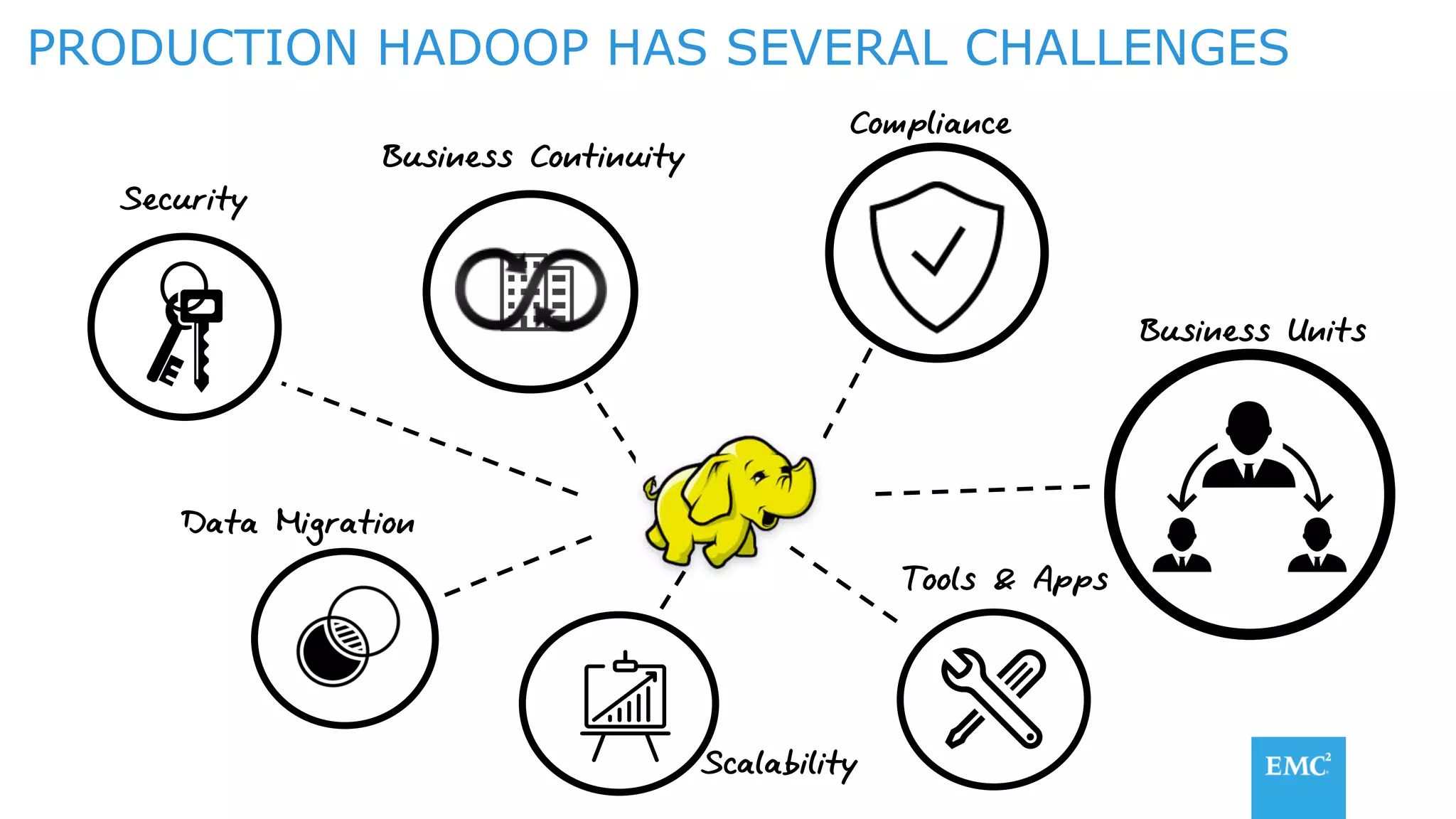


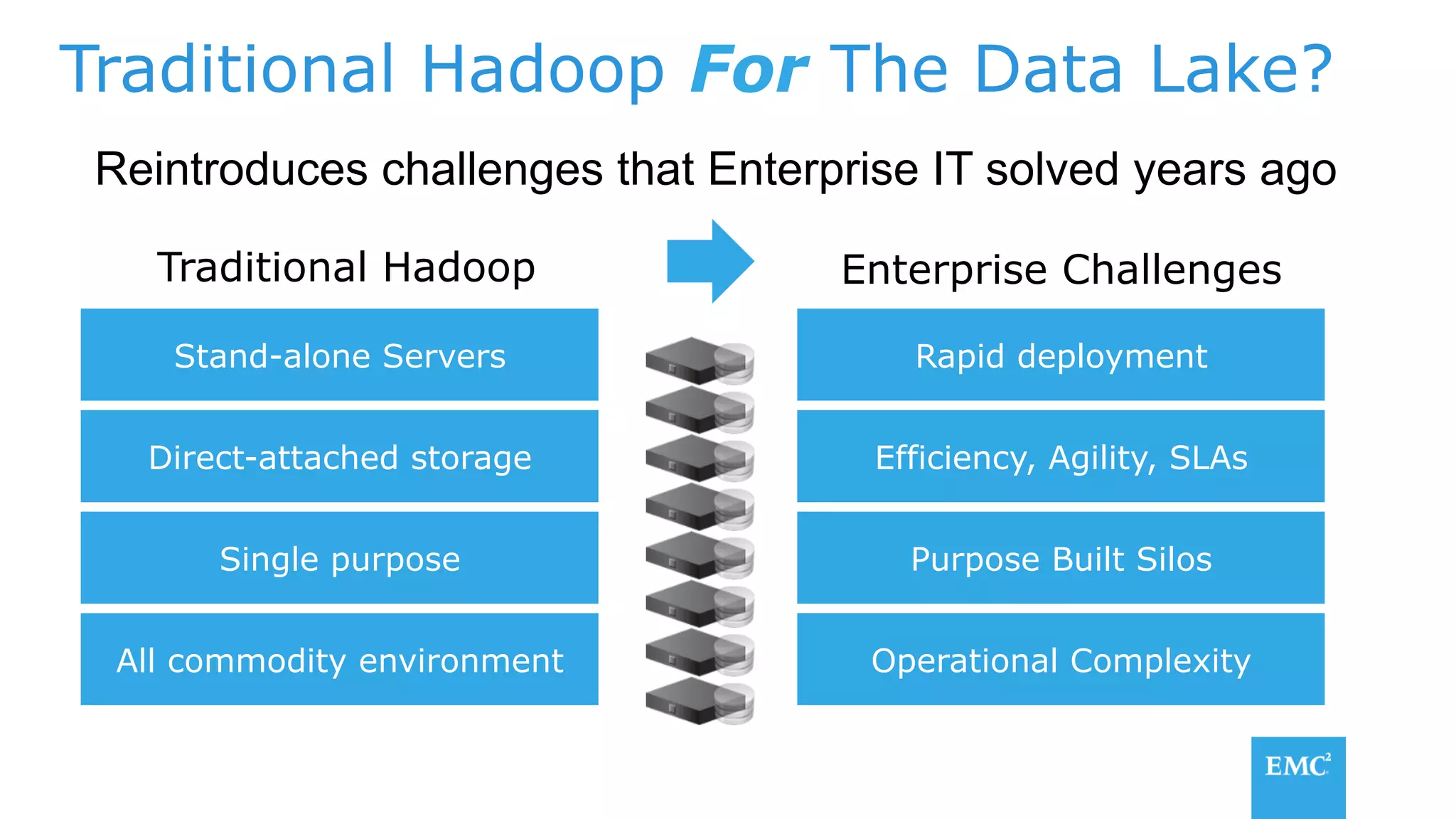
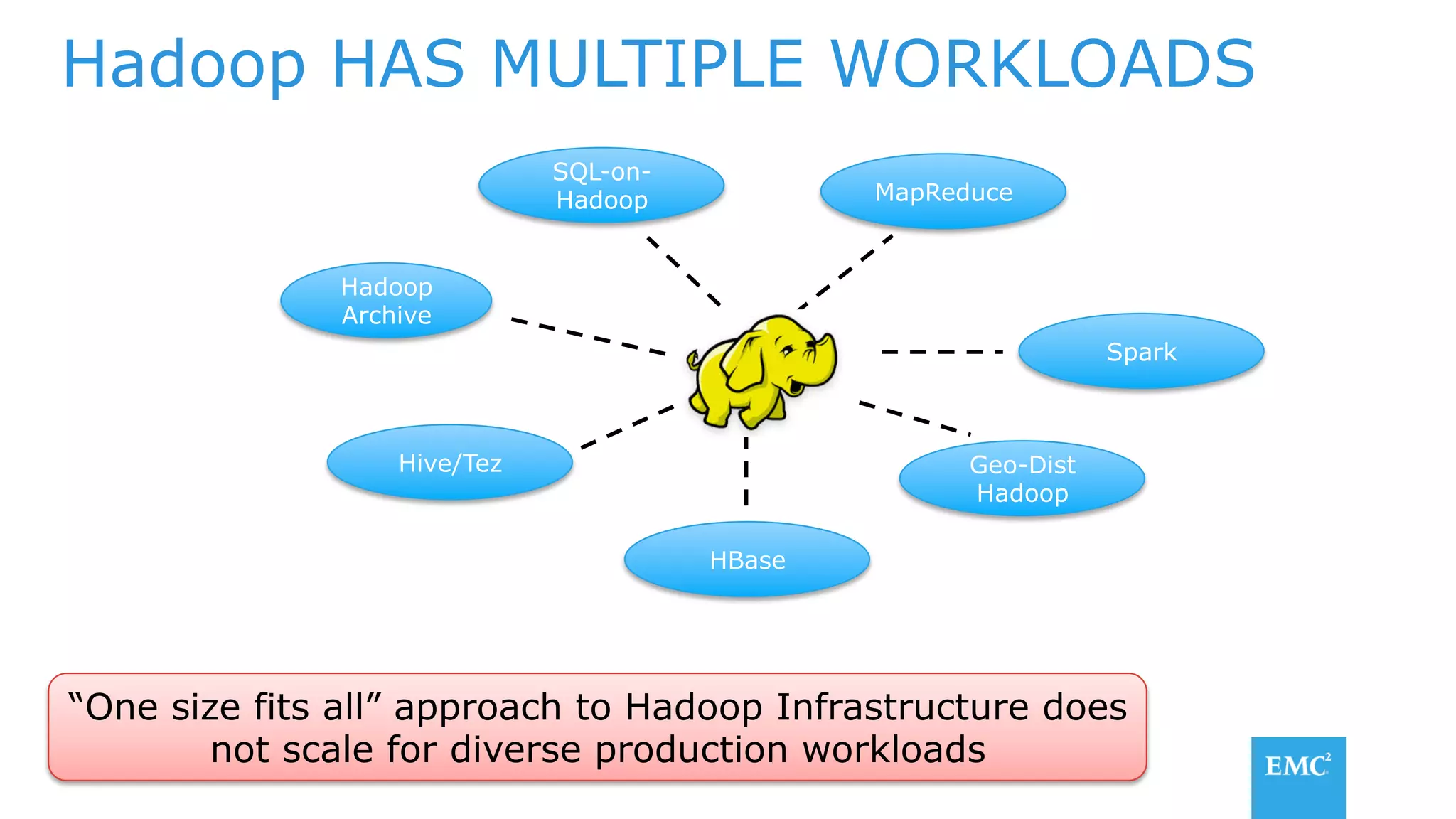
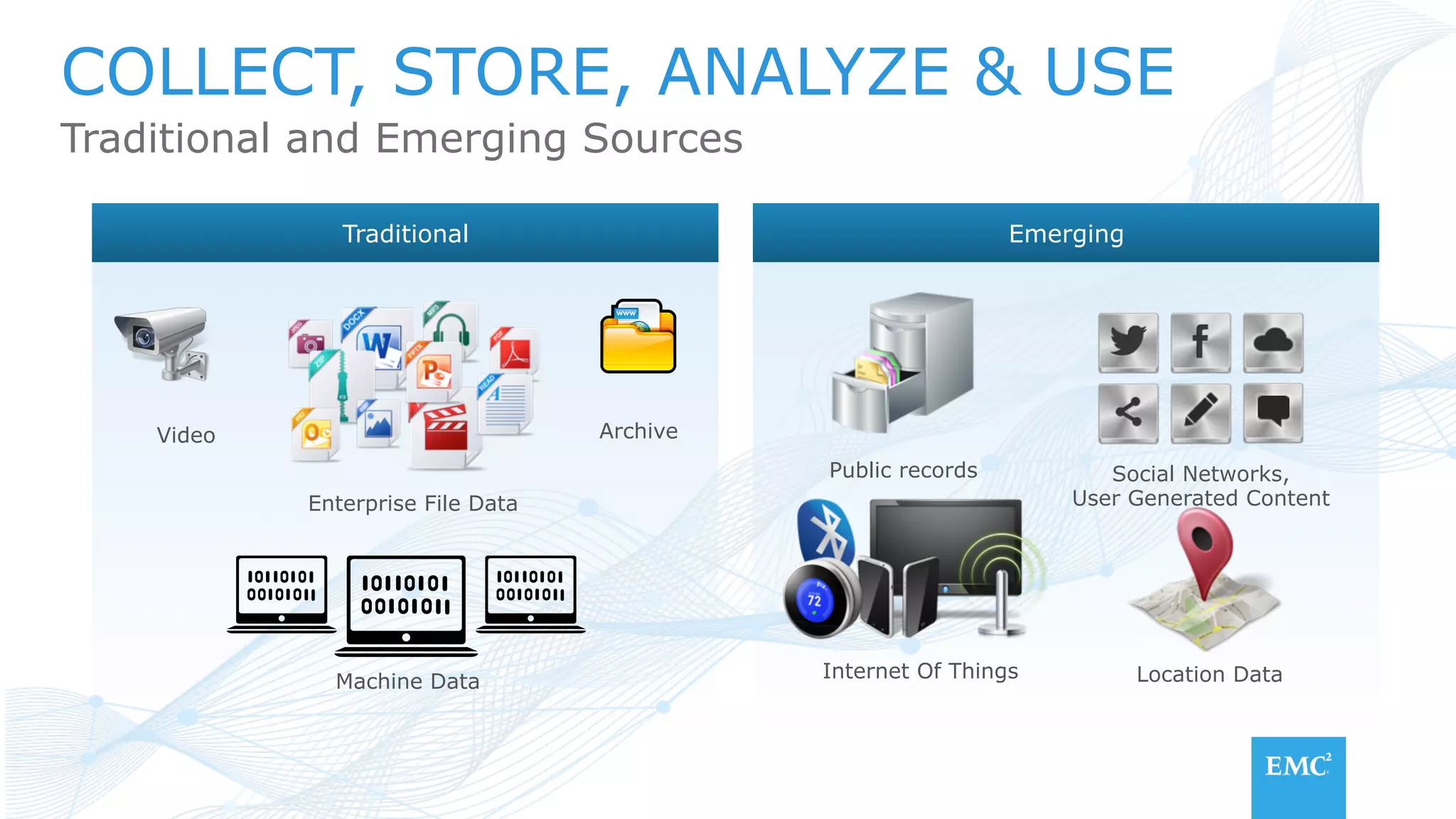


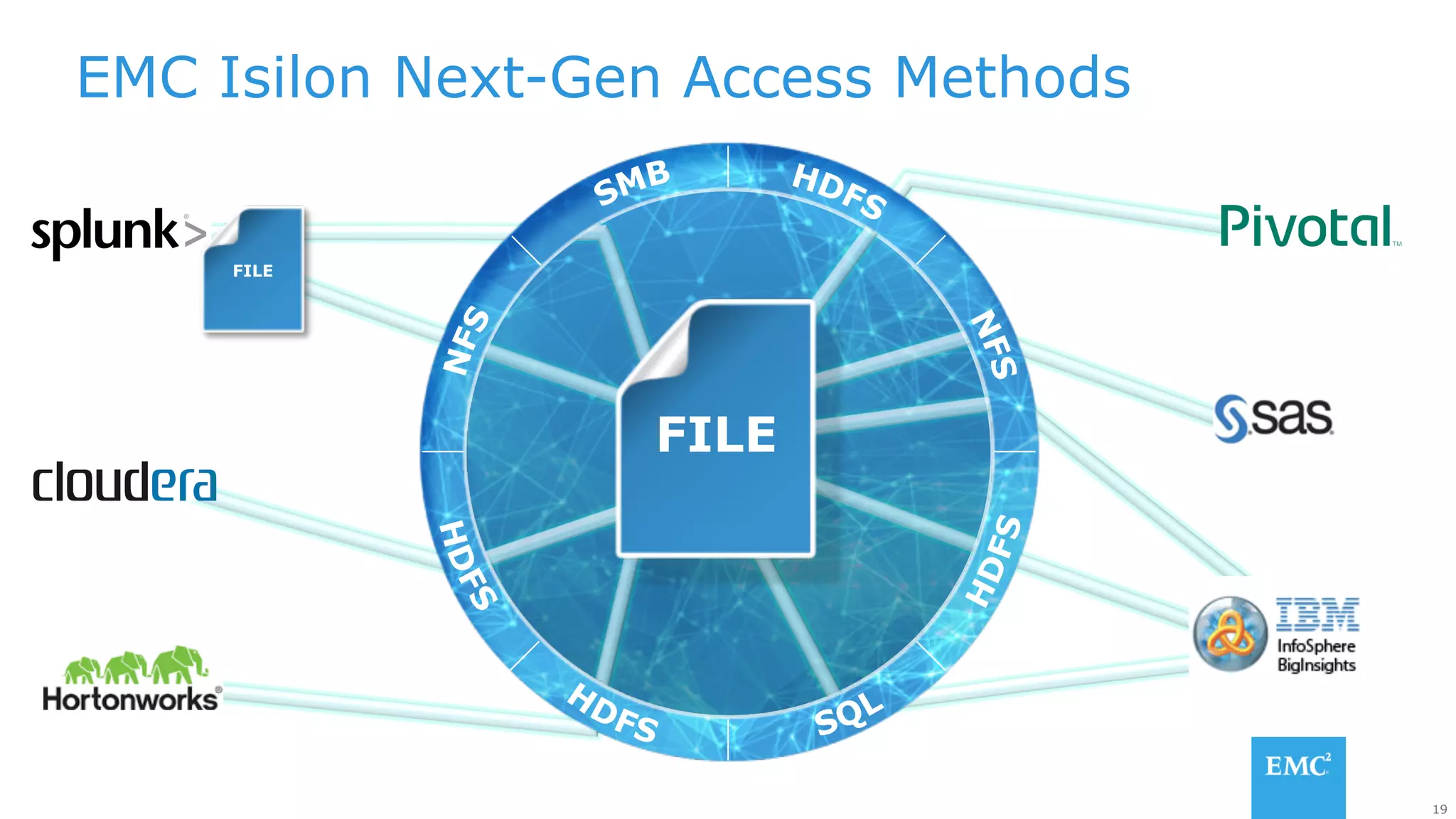

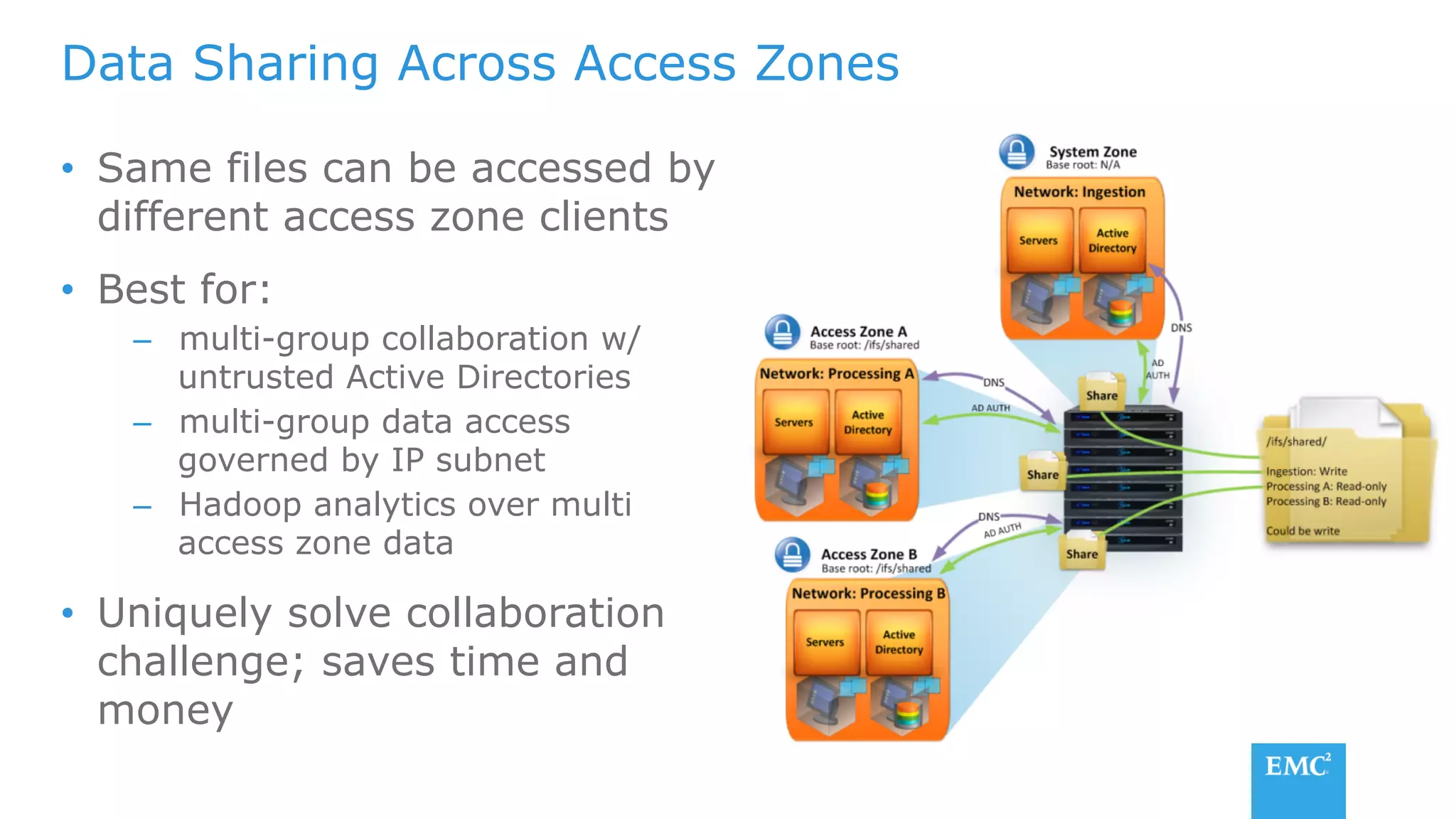
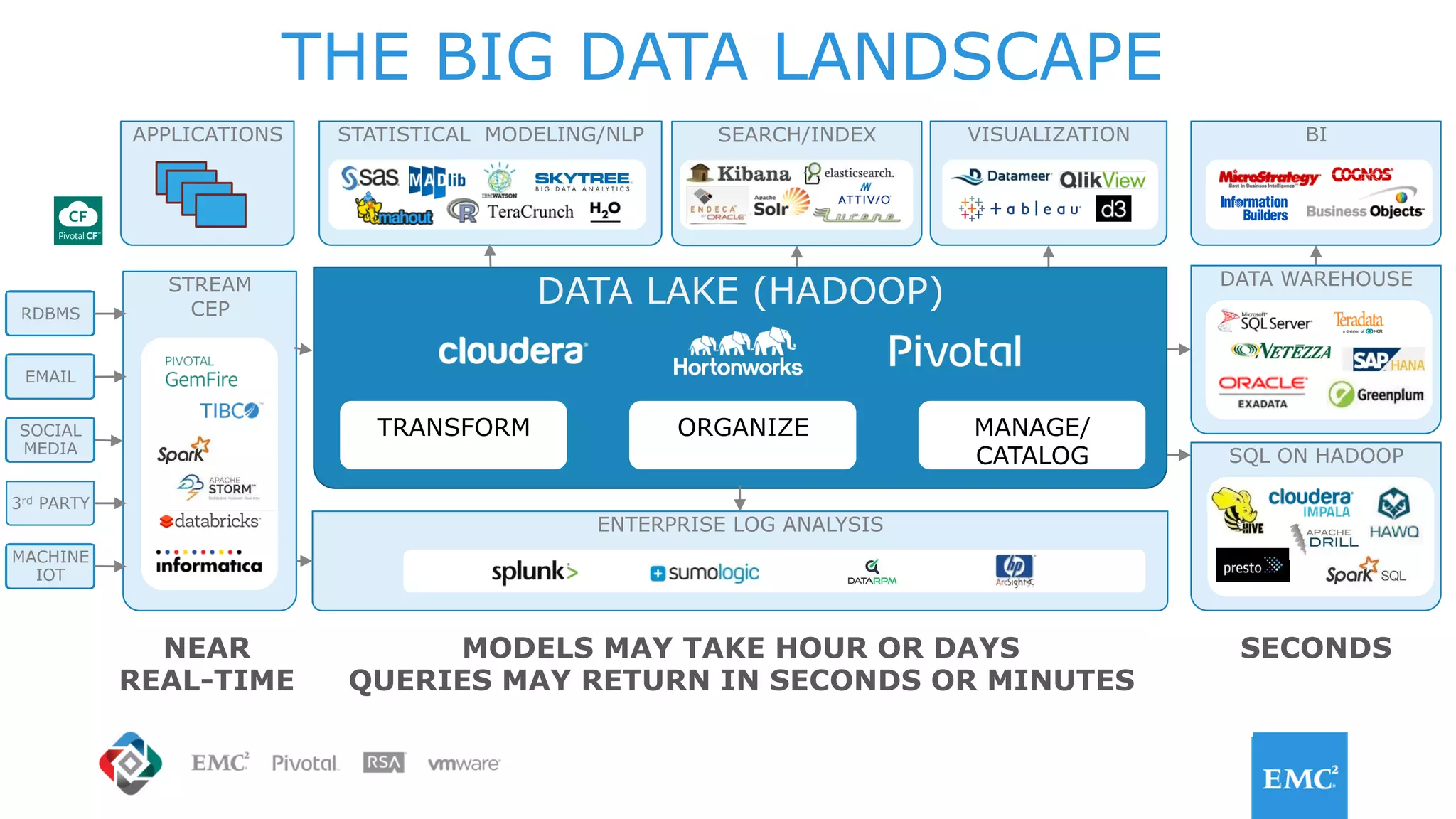
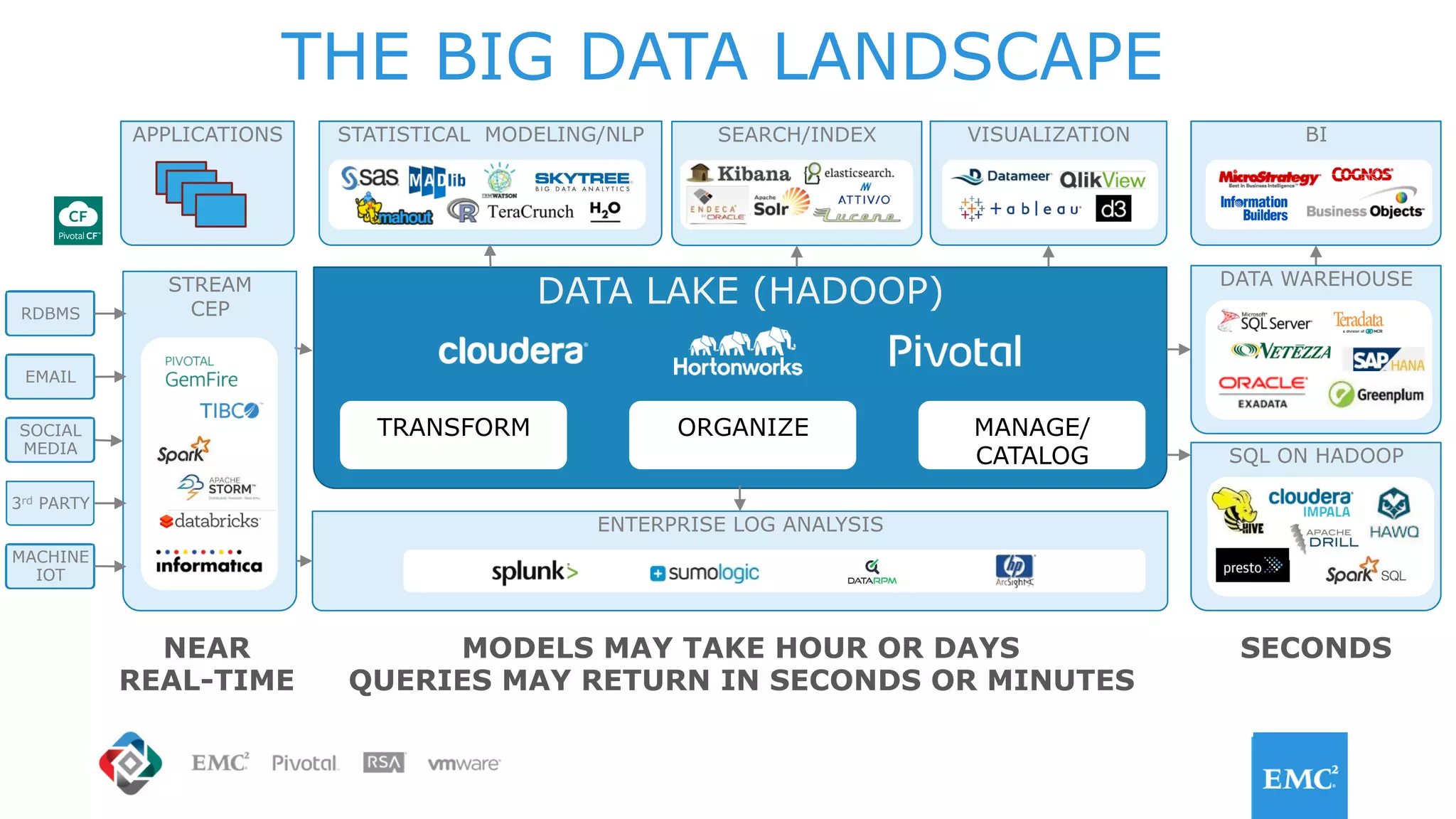
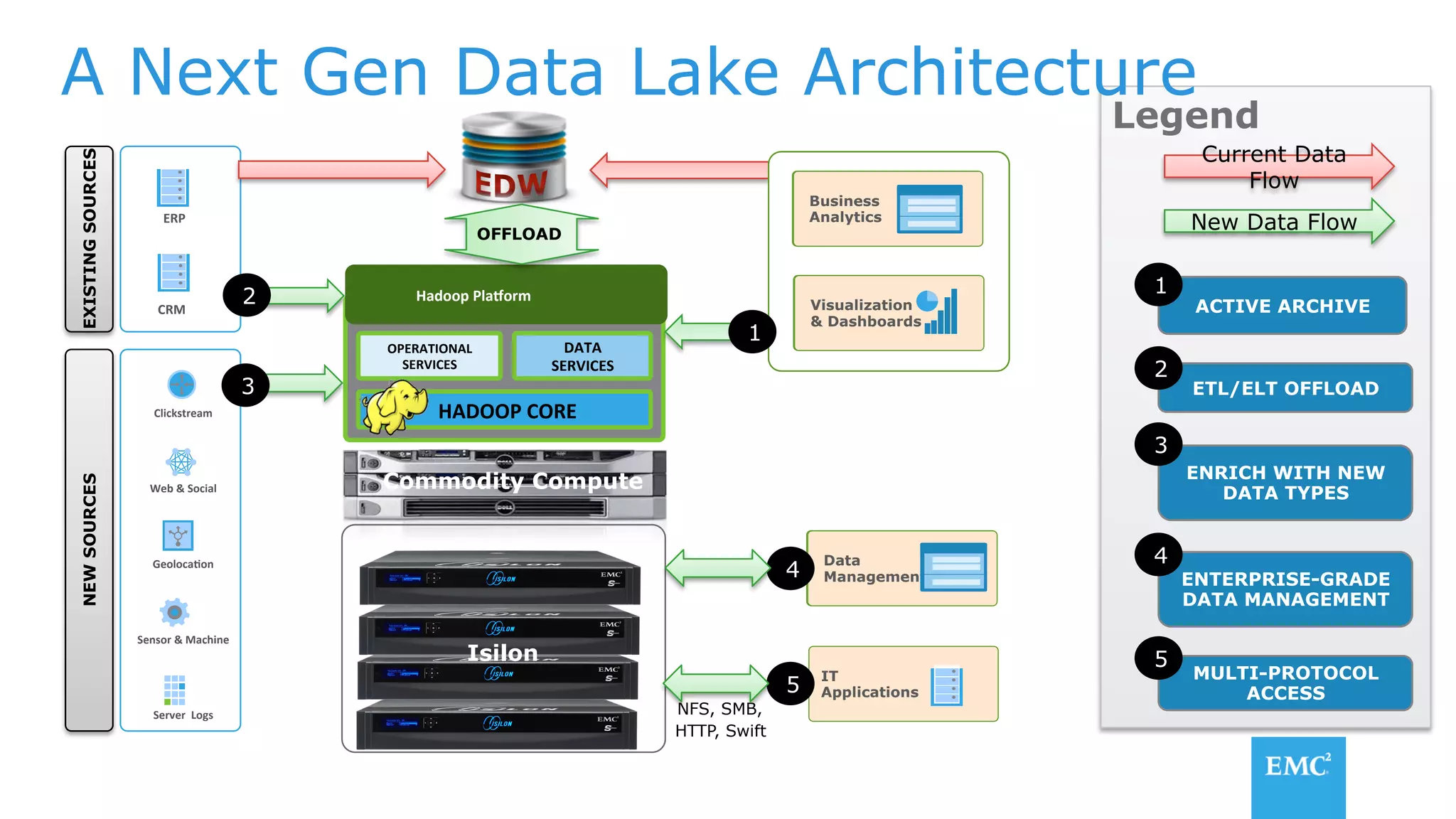
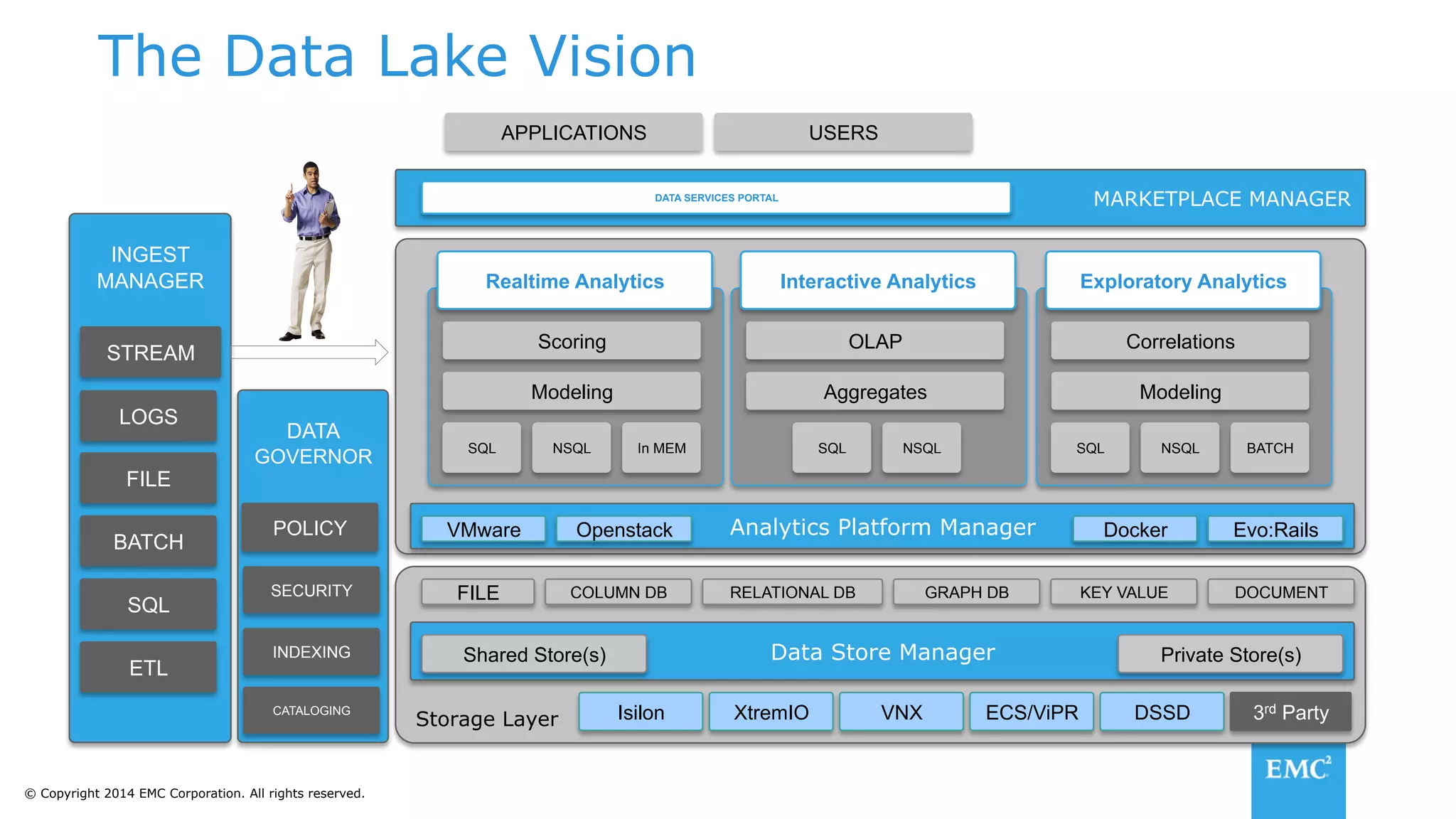
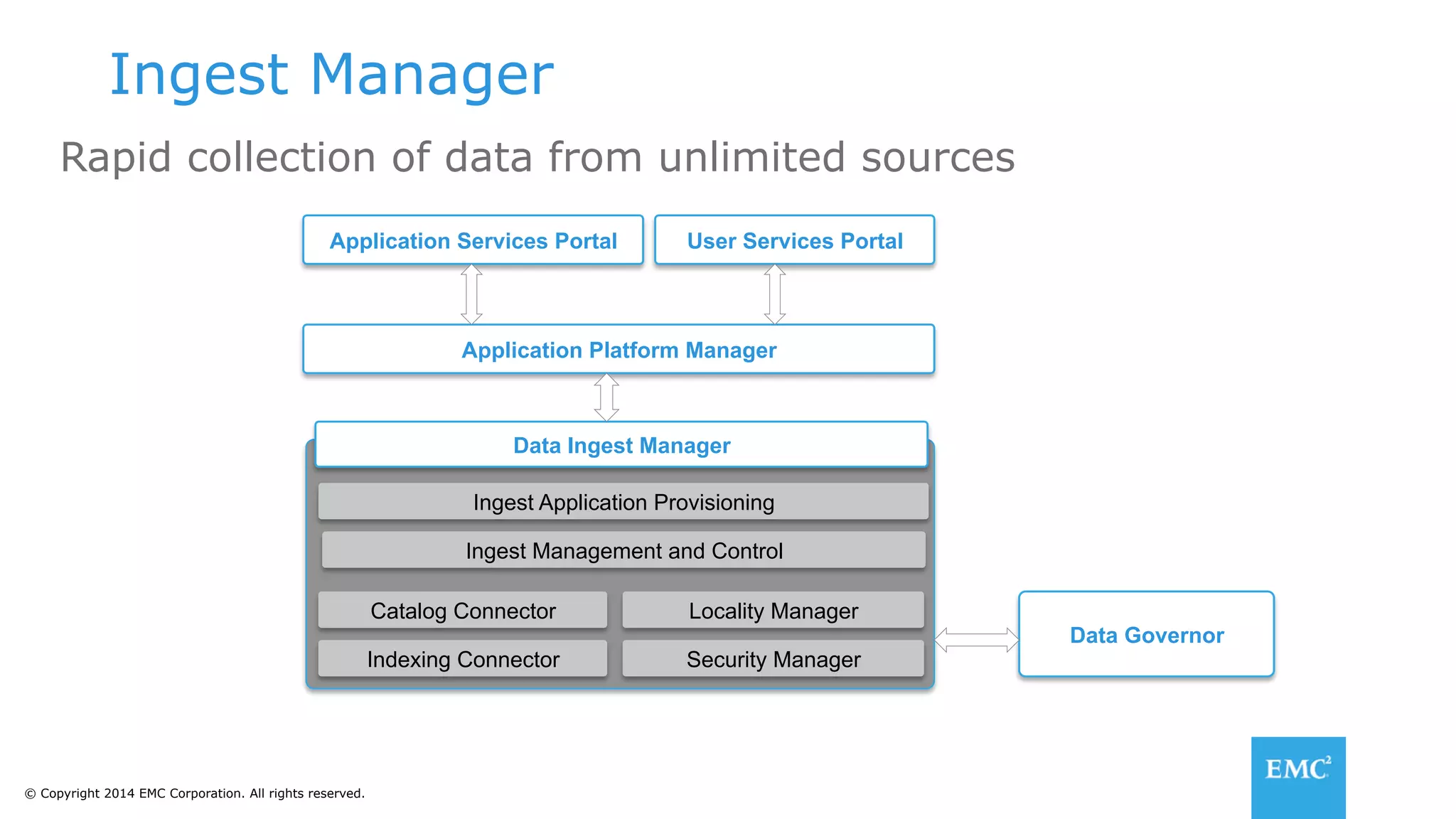
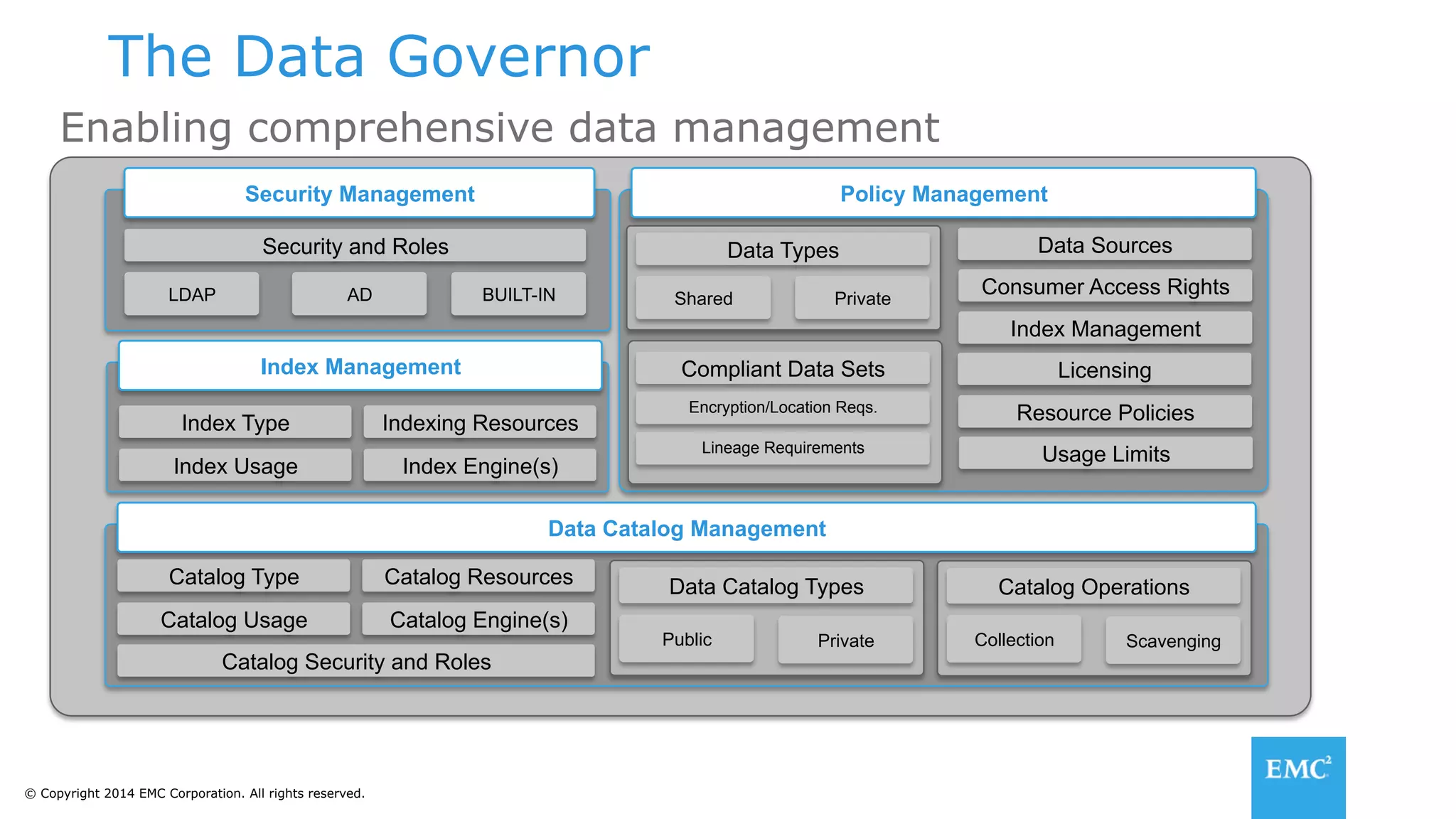

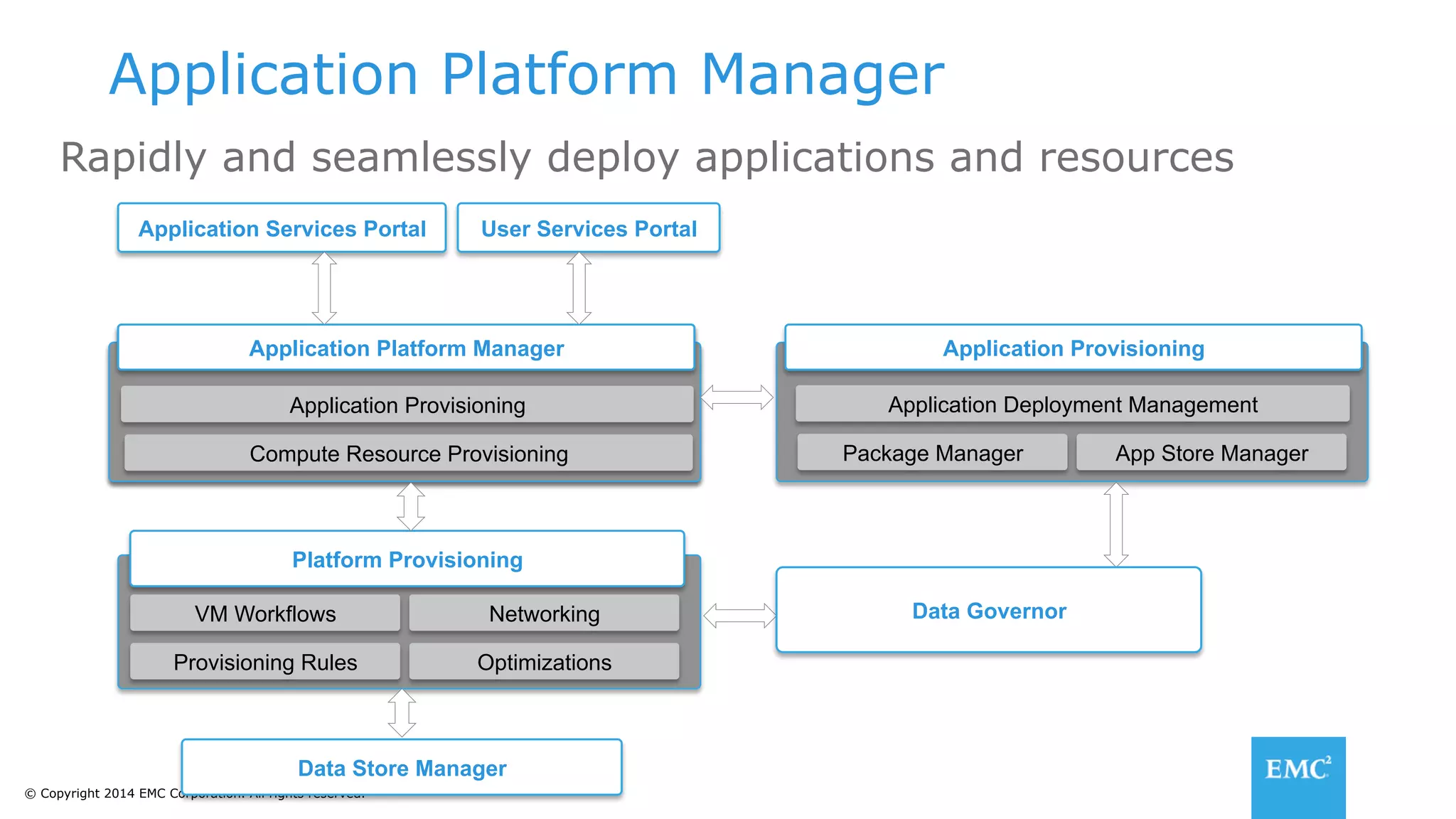
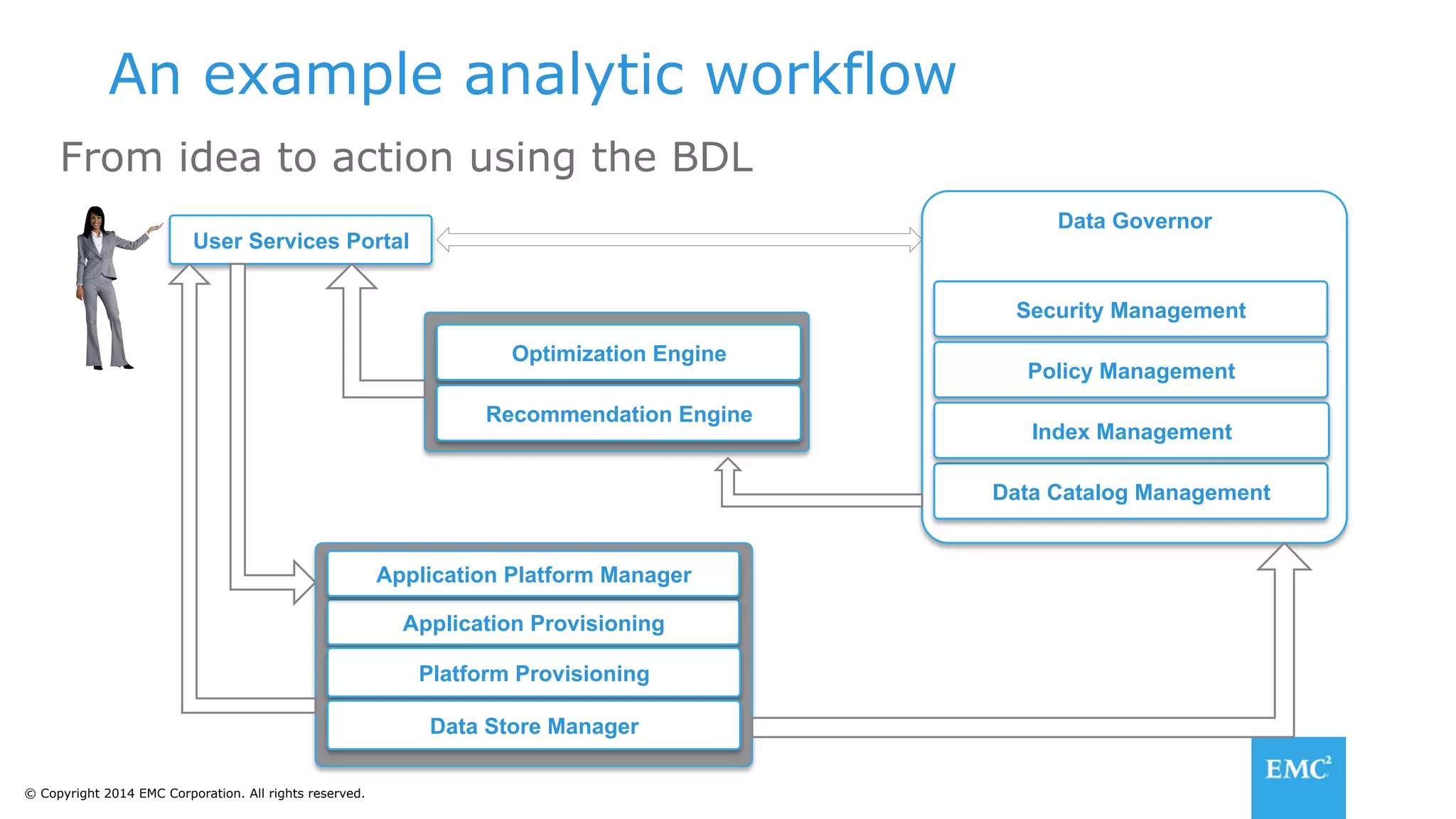



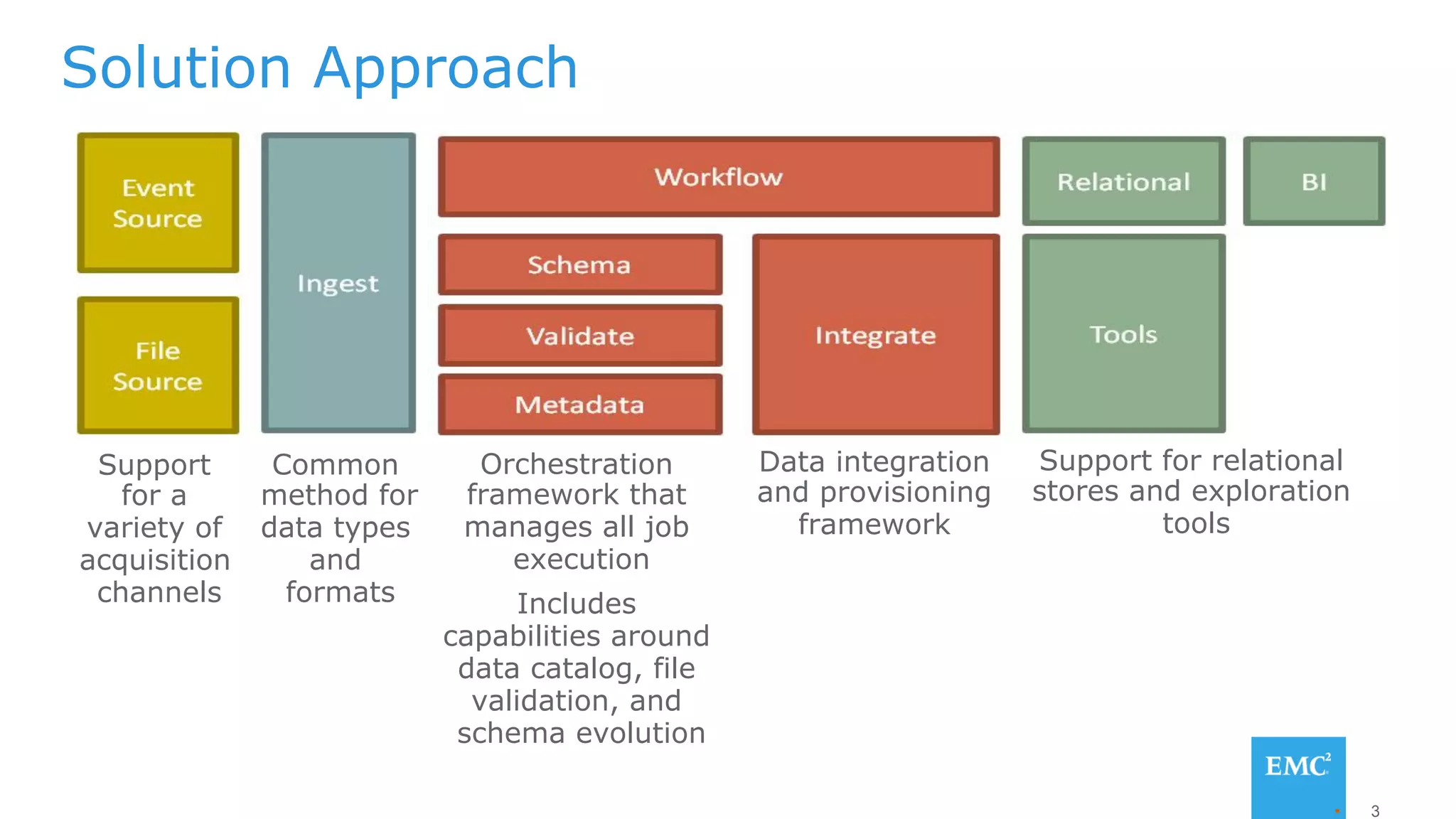






The document discusses using a data lake approach with EMC Isilon storage to address various business use cases. It describes how the solution provides shared storage for multiple workloads through multi-protocol support, enables data protection and isolation of client data, and allows testing applications across Hadoop distributions through a common platform. Examples are given of how this approach supports an enterprise data hub, data warehouse offloading, data integration, and enrichment services.






















































































