



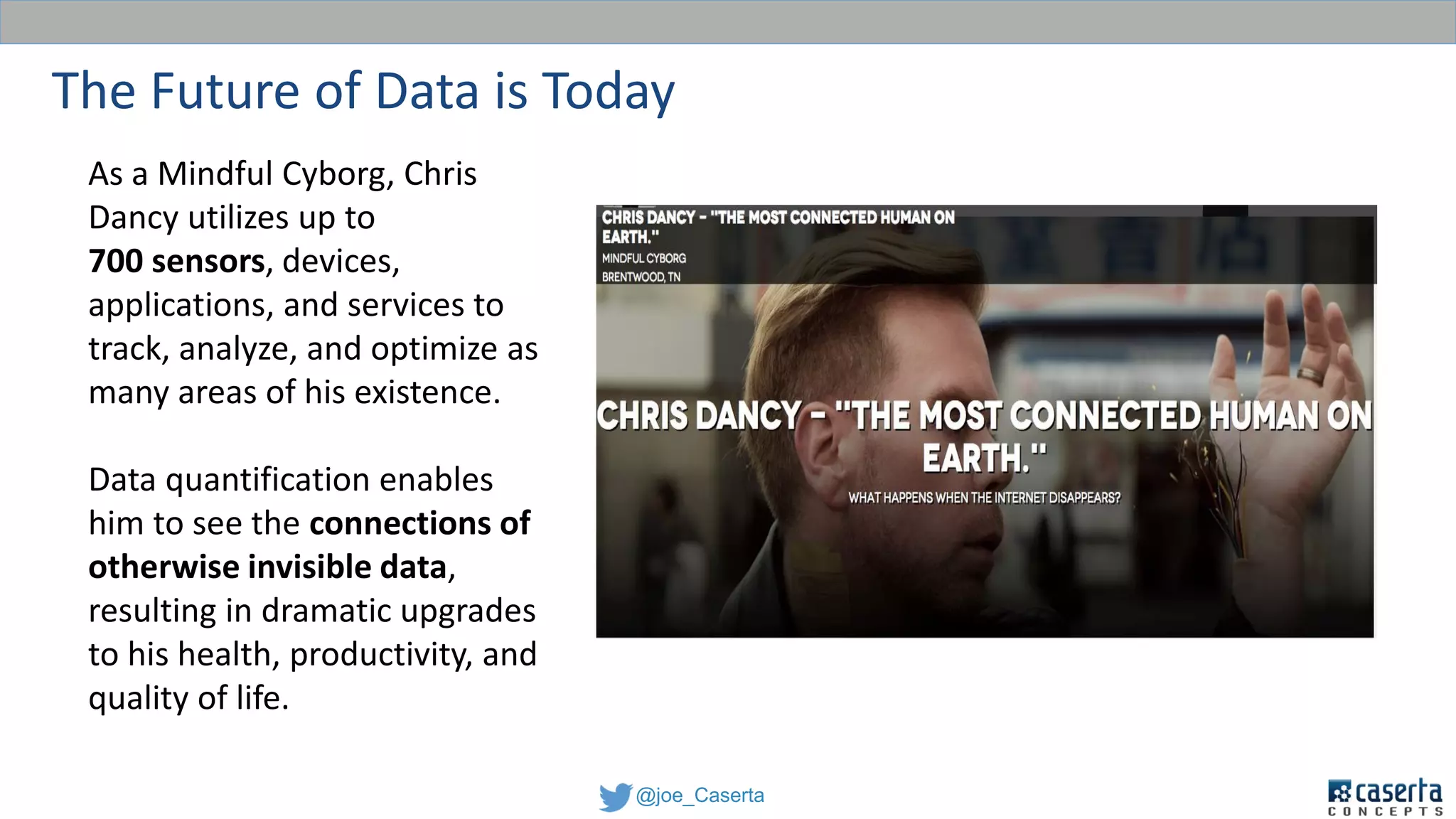
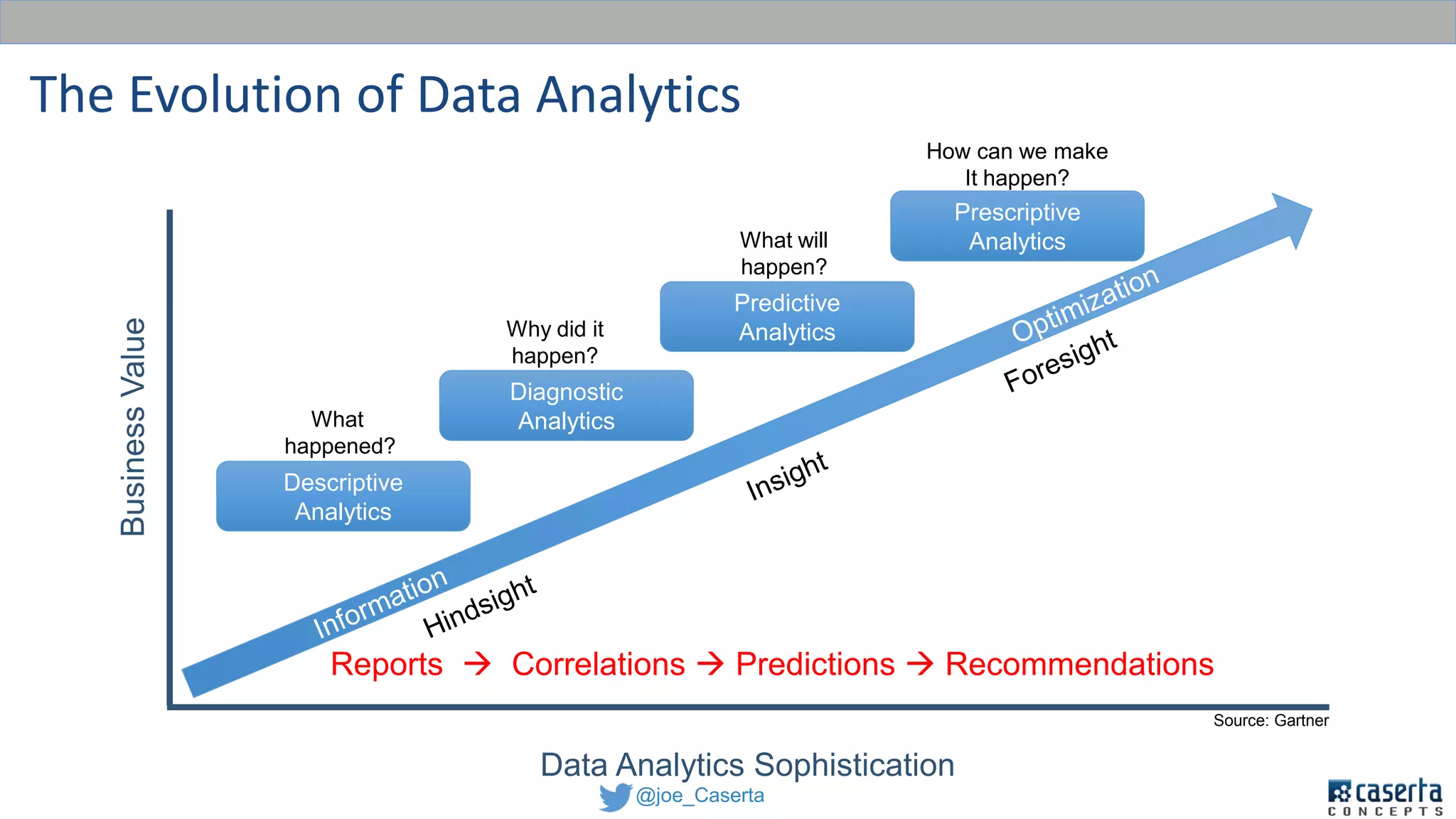
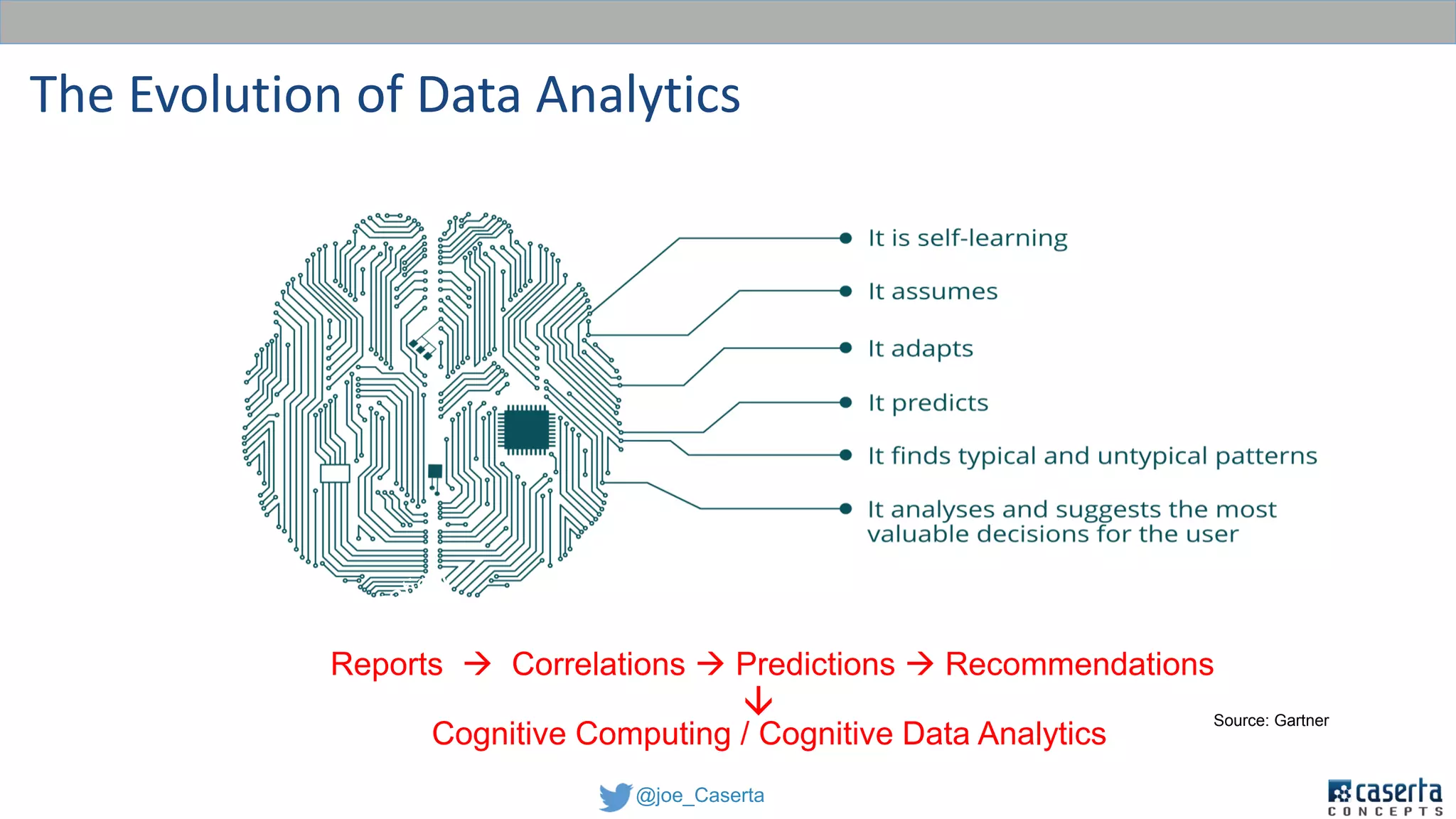



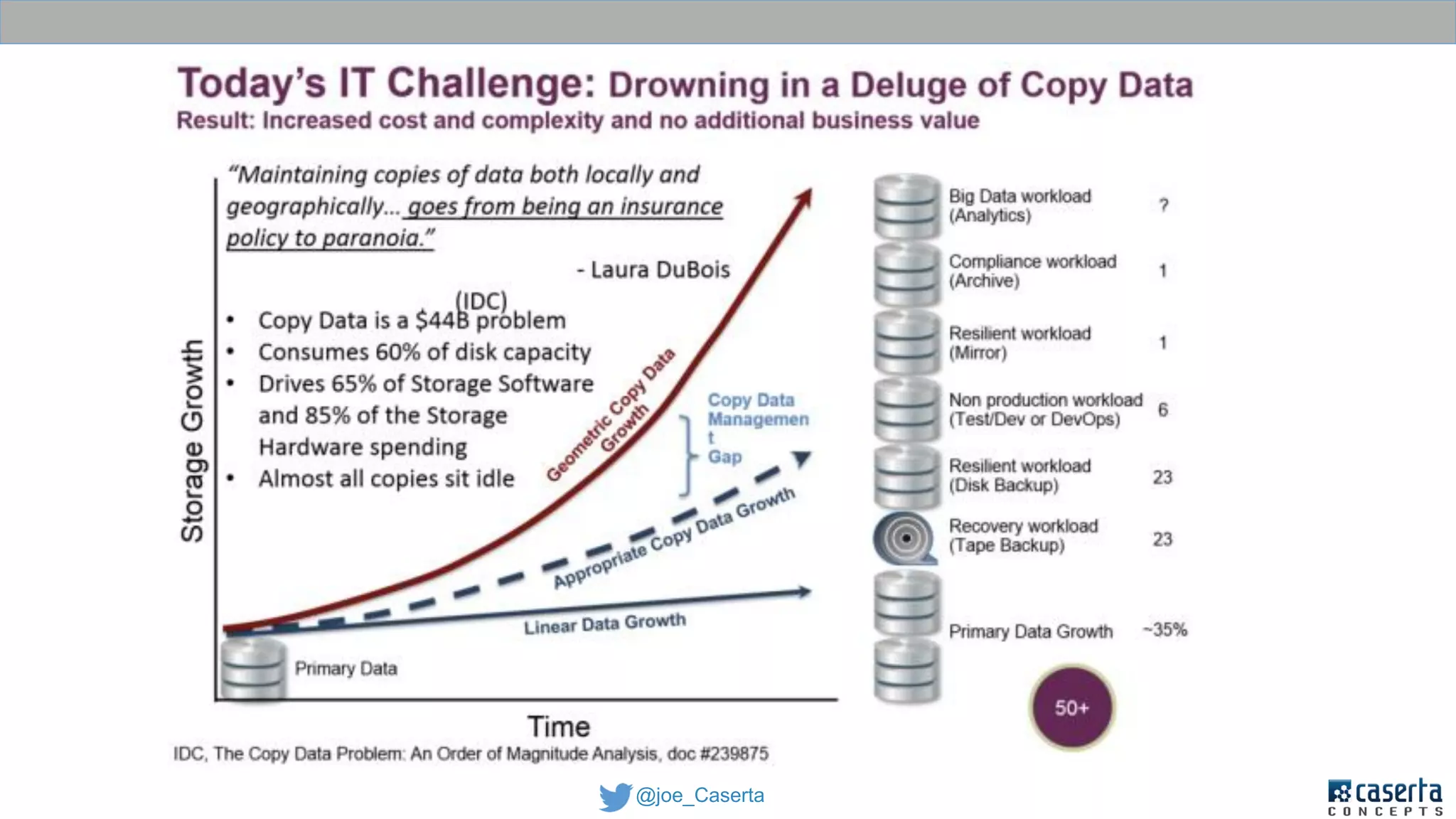


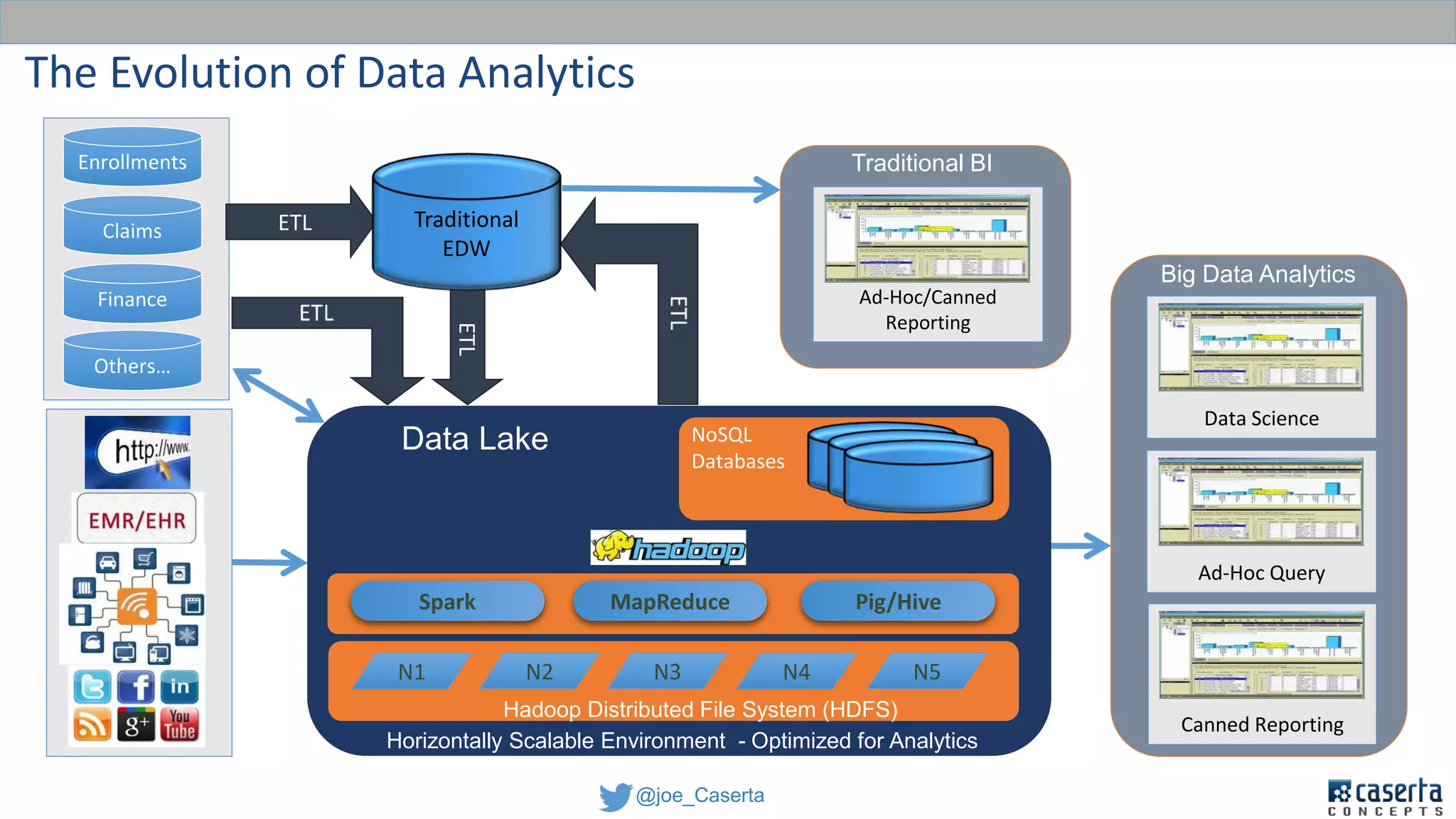




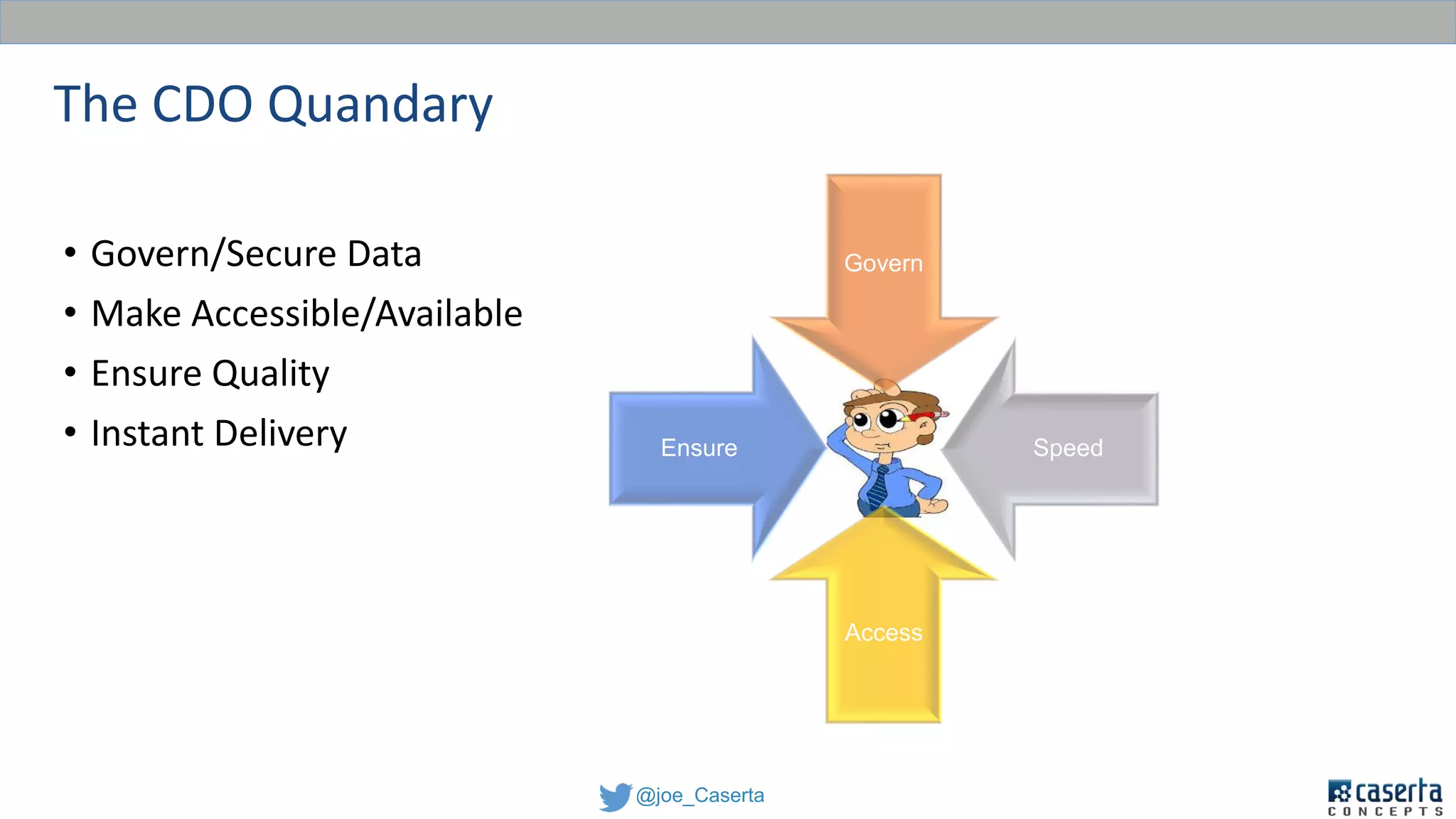
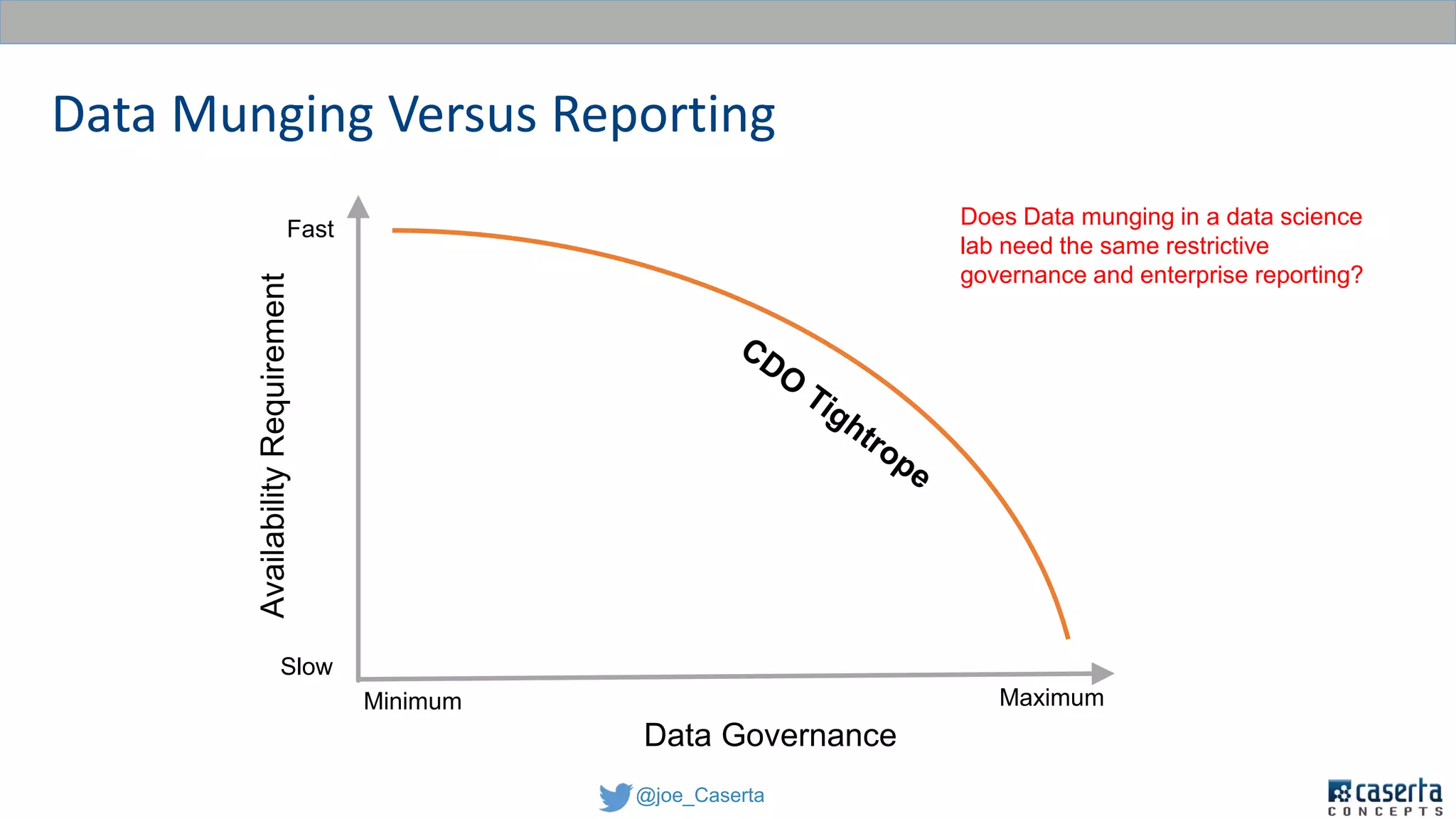


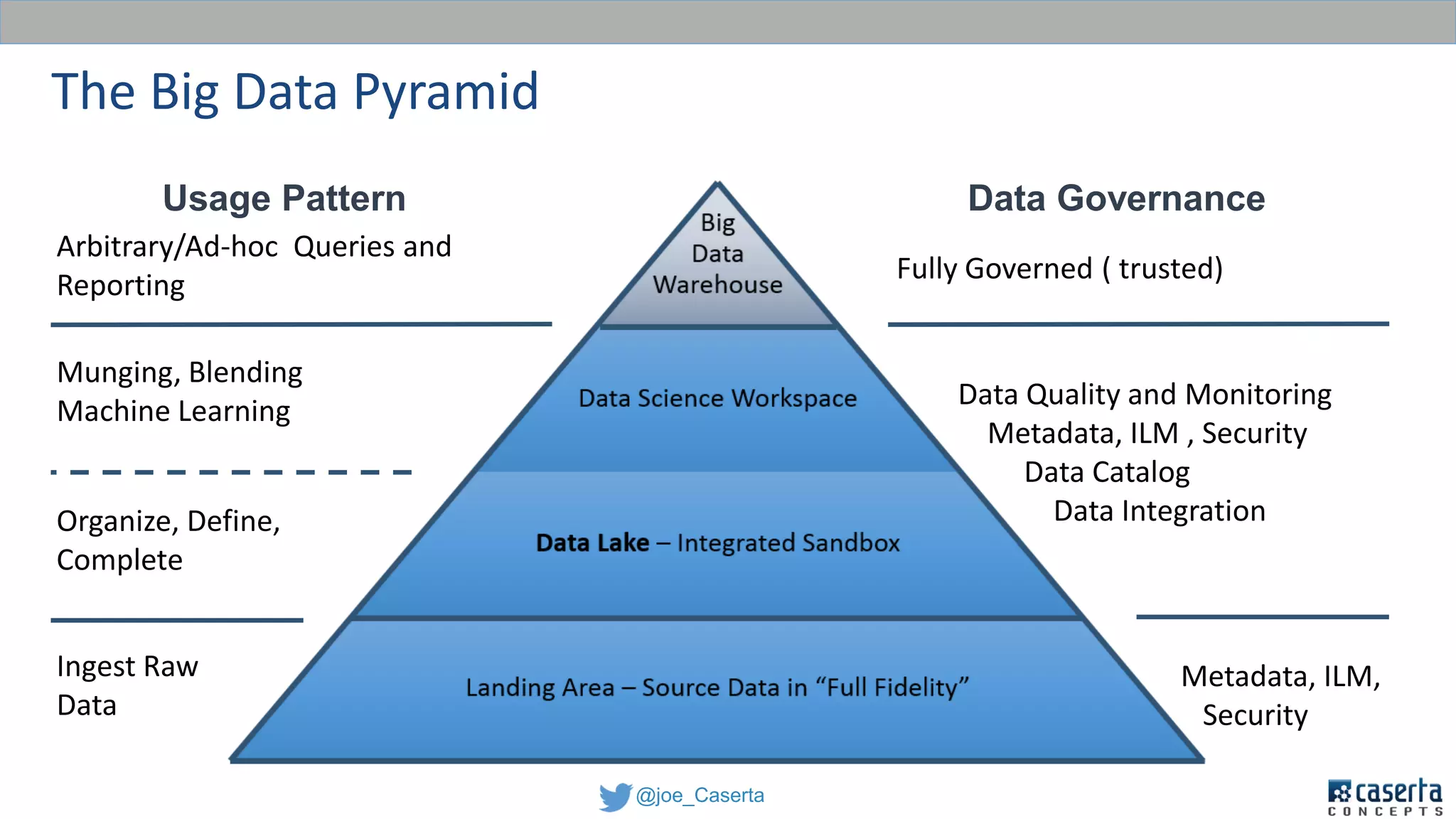
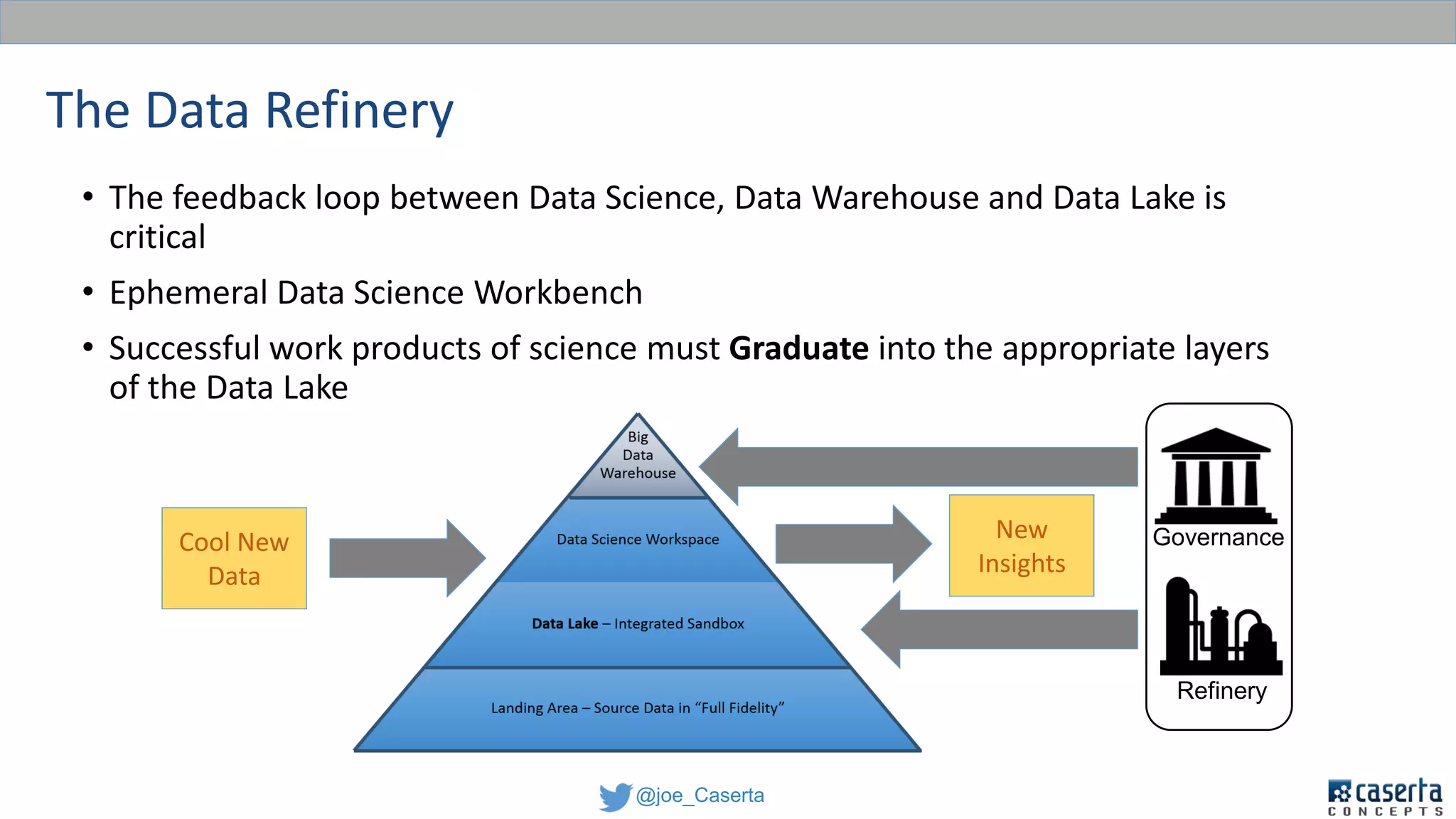




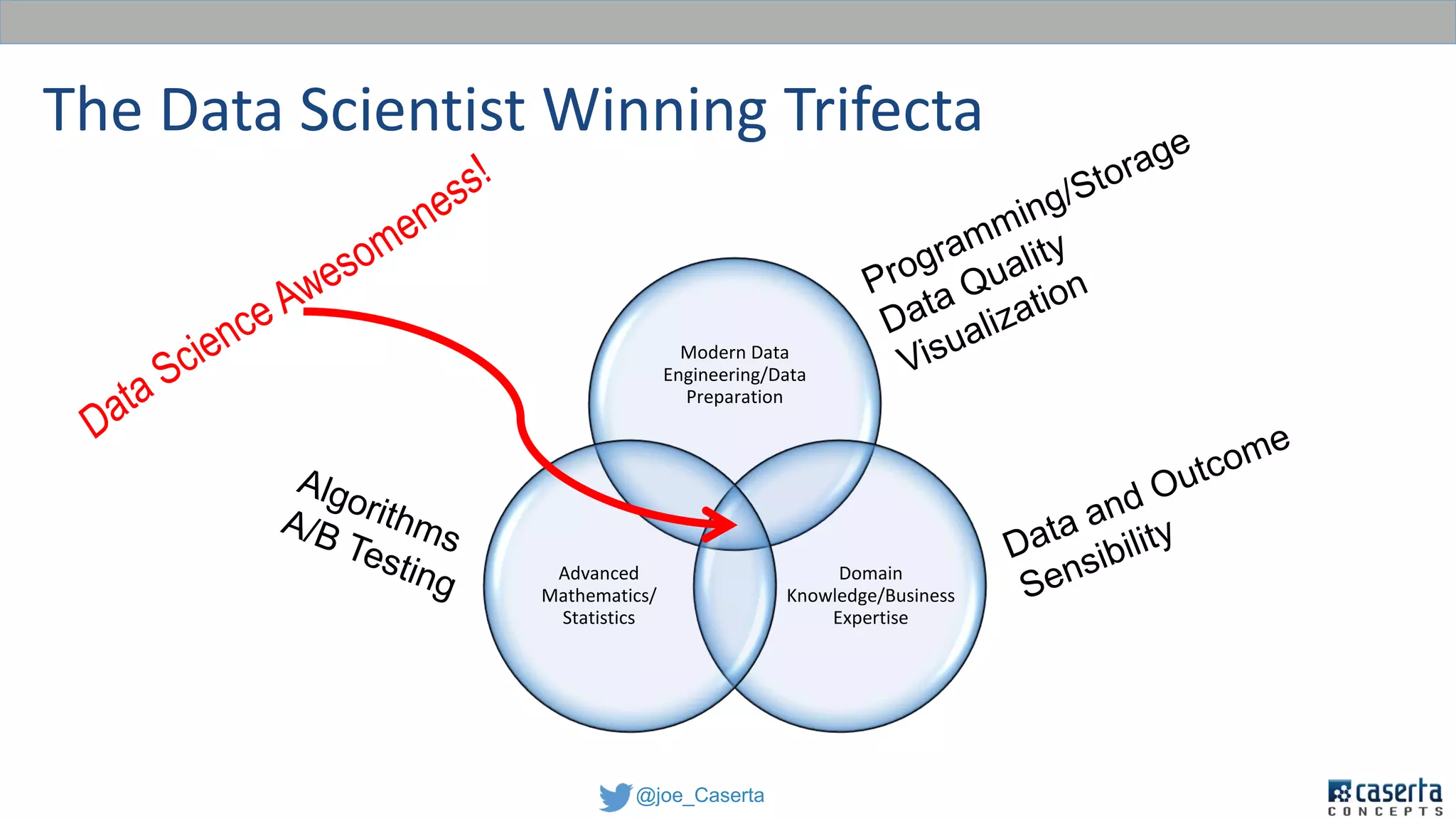
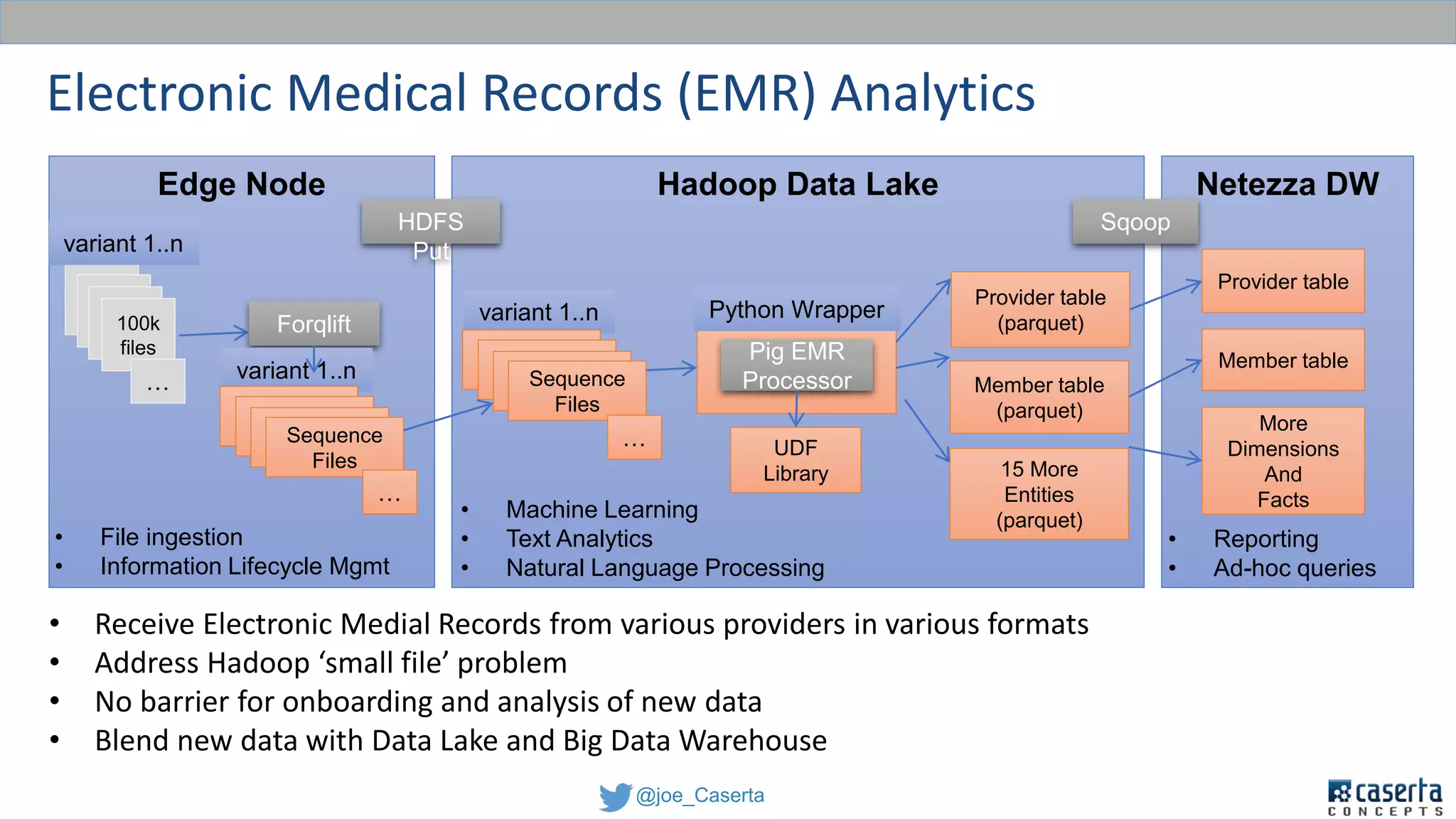

This document discusses balancing data governance and innovation. It describes how traditional data analytics methods can inhibit innovation by requiring lengthy processes to analyze new data. The document advocates adopting a data lake approach using tools like Hadoop and Spark to allow for faster ingestion and analysis of diverse data types. It also discusses challenges around simultaneously enabling innovation through a data lake while still maintaining proper data governance, security, and quality. Achieving this balance is key for organizations to leverage data for competitive advantage.





































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)













