まとめ・今後の展望
• 古典的Visual Localizationへの3Dマップの導入
•InLoc [Taira et al., 2018]: 3つのステップで段階的に3Dマップを活用
• 3Dマップを利用した仮想視点生成等で頑健な自己位置・姿勢推定を実現
• 深層学習モデル学習時の3Dマップ活用
• End-to-endでのブラックボックス化: [Kendall et al., 2015]
• 追加情報活用による精度向上 [Brahmbhatt et al., 2018]
• 姿勢初期値としての応用?
• 単一ステップのCNNモデル構成: コンパクトな問題設定で高精度な推定を実現
• 古典的姿勢推定手法との結合 [Brachmann et al., 2017]
• 局所3Dマップと姿勢の同時推定・整合性評価 [Ummenhofer et al., 2017]
• 未学習シーンへの一般化、大規模シーンへの対応、頑健性向上 etc.
31
32.
References
[1] Taira, Hajime,et al. "InLoc: Indoor visual localization with dense matching and view synthesis." Proceedings
of the IEEE Conference on Computer Vision and Pattern Recognition. 2018.
[2] 田平創, 荻野凌, 岩田健太郎, Torsten Sattler, Josef Sivic, Tomas Pajdla, 鳥居秋彦, 奥富正敏. 大規模visual
localization の実用化に向けた評価用データセットの作成. 第24回画像センシングシンポジウム, 2018.
[3] 田平創, Torsten Sattler, Josef Sivic, Tomas Pajdla, 鳥居秋彦, 奥富正敏. 大規模屋内環境における3Dマップを用い
た自己位置推定. 第25回画像センシングシンポジウム, 2019.
[4] Kendall, Alex, Matthew Grimes, and Roberto Cipolla. "Posenet: A convolutional network for real-time 6-dof
camera relocalization." Proceedings of the IEEE international conference on computer vision. 2015.
[5] Kendall, Alex, and Roberto Cipolla. "Geometric loss functions for camera pose regression with deep
learning." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017.
[6] Brachmann, Eric, et al. "Dsac-differentiable ransac for camera localization." Proceedings of the IEEE
Conference on Computer Vision and Pattern Recognition. 2017.
[7] Brachmann, Eric, and Carsten Rother. "Learning less is more-6d camera localization via 3d surface
regression." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018.
[8] Brahmbhatt, Samarth, et al. "Geometry-aware learning of maps for camera localization." Proceedings of the
IEEE Conference on Computer Vision and Pattern Recognition. 2018.
[9] Ummenhofer, Benjamin, et al. "Demon: Depth and motion network for learning monocular
stereo." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017.
32


![3Dセンシングによるマップ構築
高精細3Dマップの構築:
4
+
カラー (RGB) 画像 深度 (Depth) 画像 局所的な3Dマップ
- LIDAR等により得られるRGBD画像をDBとして収集
- 屋内環境で特に有効
[https://www.google.com/maps, https://velodynelidar.com, https://www.faro.com/]](https://image.slidesharecdn.com/tairaos2020share-200609083514/85/3D-Visual-Localization-4-320.jpg)
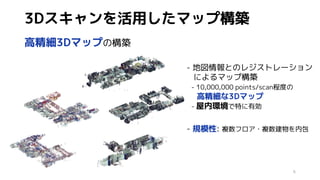
![- 地図情報とのレジストレーション
によるマップ構築
- 10,000,000 points/scan程度の
高精細な3Dマップ
- 屋内環境で特に有効
3Dスキャンを活用したマップ構築
5フロアマップ
高精細3Dマップの構築
[E. Wijman and Y. Furukawa, 2017]](https://image.slidesharecdn.com/tairaos2020share-200609083514/85/3D-Visual-Localization-5-320.jpg)

![InLoc [H. Taira et al., CVPR2018]
9
大規模屋内環境における自己位置・姿勢推定
Given: RGBD画像群
Input: RGB画像](https://image.slidesharecdn.com/tairaos2020share-200609083514/85/3D-Visual-Localization-9-320.jpg)
![位置候補選択
InLoc [H. Taira et al., 2018]
Approach: 古典的手法への高精細な3Dマップの導入
10
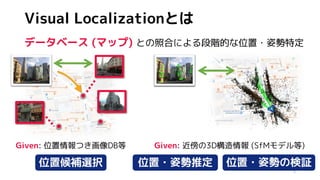
Given: 位置情報つき画像DB等 Given: 近傍の3D構造情報 (SfMモデル等)
位置・姿勢推定 位置・姿勢の検証](https://image.slidesharecdn.com/tairaos2020share-200609083514/85/3D-Visual-Localization-10-320.jpg)
![位置候補選択
InLoc [H. Taira et al., 2018]
Approach: 古典的手法への高精細な3Dマップの導入
11
Given: 高精細3Dマップ
- RGBD画像群で構成
- 高粒度の3D構造情報
位置・姿勢推定 位置・姿勢の検証](https://image.slidesharecdn.com/tairaos2020share-200609083514/85/3D-Visual-Localization-11-320.jpg)

![InLoc pipeline
NetVLAD (画像検索)
[Arandjelović CVPR 2016]
Image retrieval
…
Top 100 retrieved database images
13
RGBD image database](https://image.slidesharecdn.com/tairaos2020share-200609083514/85/3D-Visual-Localization-13-320.jpg)







![Evaluation Pose verification
(高精細3Dマップ)
画像検索 (RGB画像)
姿勢推定 (RGBD画像)
Sparse feature baseline
[Arandjelović, ACCV2014]
InLoc (ours)
21
Validation:
累積誤差分布 @InLoc dataset
[田平ら、SSII2018]
3Dマップを段階的に導入して効果を確認:
- 画像検索を用いた位置特定
- 密な特徴マッチングによる3Dマップの効率的な活用
- 高精細な3Dマップを活用した姿勢検証](https://image.slidesharecdn.com/tairaos2020share-200609083514/85/3D-Visual-Localization-21-320.jpg)




![深層学習を導入したVisual Localization
PoseNet [A. Kendall et al., 2015]
3Dマップを学習DBとしてCNN姿勢推定器 (GoogleNet) を学習
26
Given: 学習用データベース
- 画像 + 真値情報 (姿勢情報等)
…
GoogleNet
勾配計算:
姿勢パラメータL2ロス
Input (学習): 単眼画像](https://image.slidesharecdn.com/tairaos2020share-200609083514/85/3D-Visual-Localization-26-320.jpg)
![深層学習を導入したVisual Localization
PoseNet [A. Kendall et al., 2015]
3Dマップを学習DBとしてCNN姿勢推定器 (GoogleNet) を学習
27
姿勢推定器ベンチマーク [A. kendall and R. Cipolla, 2017]
古典的手法](https://image.slidesharecdn.com/tairaos2020share-200609083514/85/3D-Visual-Localization-27-320.jpg)
![深層学習を導入したVisual Localization
DSAC [E. Brachmann et al., 2017]
3Dマップの姿勢情報+局所3Dマップを利用して3Dマップ再現器と姿勢検証器を学習
28
Given: 学習用データベース
- 画像 + 真値情報 (姿勢情報+局所3Dマップ)
① 入力画像に対する3Dマップ再現 ② 姿勢候補の検証
勾配計算 (局所3Dマップ) 勾配計算 (姿勢情報)](https://image.slidesharecdn.com/tairaos2020share-200609083514/85/3D-Visual-Localization-28-320.jpg)
![深層学習を導入したVisual Localization
DSAC [E. Brachmann et al., 2017]
3Dマップの姿勢情報+局所3Dマップを利用して3Dマップ再現器と姿勢検証器を学習
29
姿勢推定器ベンチマーク [E. Brachmann and C. Rother, 2018]
古典的手法
古典的手法に対して精度面でも
同程度の性能を達成](https://image.slidesharecdn.com/tairaos2020share-200609083514/85/3D-Visual-Localization-29-320.jpg)
![深層学習を導入したVisual Localization
InLoc++ [H. Taira et al., 2019]
学習済み深層学習モデルから得られるマルチドメインの情報をPose verificationに活用
30
InLoc: 74.2%@2m
InLoc++: 80.6%@2m
高精細3Dマップ
InLoc: カラー画像 (RGB) との整合性評価
Surface normal
Semantic label](https://image.slidesharecdn.com/tairaos2020share-200609083514/85/3D-Visual-Localization-30-320.jpg)
![まとめ・今後の展望
• 古典的Visual Localizationへの3Dマップの導入
• InLoc [Taira et al., 2018]: 3つのステップで段階的に3Dマップを活用
• 3Dマップを利用した仮想視点生成等で頑健な自己位置・姿勢推定を実現
• 深層学習モデル学習時の3Dマップ活用
• End-to-endでのブラックボックス化: [Kendall et al., 2015]
• 追加情報活用による精度向上 [Brahmbhatt et al., 2018]
• 姿勢初期値としての応用?
• 単一ステップのCNNモデル構成: コンパクトな問題設定で高精度な推定を実現
• 古典的姿勢推定手法との結合 [Brachmann et al., 2017]
• 局所3Dマップと姿勢の同時推定・整合性評価 [Ummenhofer et al., 2017]
• 未学習シーンへの一般化、大規模シーンへの対応、頑健性向上 etc.
31](https://image.slidesharecdn.com/tairaos2020share-200609083514/85/3D-Visual-Localization-31-320.jpg)
![References
[1] Taira, Hajime, et al. "InLoc: Indoor visual localization with dense matching and view synthesis." Proceedings
of the IEEE Conference on Computer Vision and Pattern Recognition. 2018.
[2] 田平創, 荻野凌, 岩田健太郎, Torsten Sattler, Josef Sivic, Tomas Pajdla, 鳥居秋彦, 奥富正敏. 大規模visual
localization の実用化に向けた評価用データセットの作成. 第24回画像センシングシンポジウム, 2018.
[3] 田平創, Torsten Sattler, Josef Sivic, Tomas Pajdla, 鳥居秋彦, 奥富正敏. 大規模屋内環境における3Dマップを用い
た自己位置推定. 第25回画像センシングシンポジウム, 2019.
[4] Kendall, Alex, Matthew Grimes, and Roberto Cipolla. "Posenet: A convolutional network for real-time 6-dof
camera relocalization." Proceedings of the IEEE international conference on computer vision. 2015.
[5] Kendall, Alex, and Roberto Cipolla. "Geometric loss functions for camera pose regression with deep
learning." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017.
[6] Brachmann, Eric, et al. "Dsac-differentiable ransac for camera localization." Proceedings of the IEEE
Conference on Computer Vision and Pattern Recognition. 2017.
[7] Brachmann, Eric, and Carsten Rother. "Learning less is more-6d camera localization via 3d surface
regression." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018.
[8] Brahmbhatt, Samarth, et al. "Geometry-aware learning of maps for camera localization." Proceedings of the
IEEE Conference on Computer Vision and Pattern Recognition. 2018.
[9] Ummenhofer, Benjamin, et al. "Demon: Depth and motion network for learning monocular
stereo." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017.
32](https://image.slidesharecdn.com/tairaos2020share-200609083514/85/3D-Visual-Localization-32-320.jpg)
![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Neural Ordinary Differential Equations](https://cdn.slidesharecdn.com/ss_thumbnails/nnasode1-190111001755-thumbnail.jpg?width=640&height=640&fit=bounds)










![SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...](https://cdn.slidesharecdn.com/ss_thumbnails/ss1-01-210607043349-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metr...](https://cdn.slidesharecdn.com/ss_thumbnails/181214dlpointnet-181214053349-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2021 [TS1] Visual SLAM ~カメラ幾何の基礎から最近の技術動向まで~](https://cdn.slidesharecdn.com/ss_thumbnails/ts1-01-210607042113-thumbnail.jpg?width=640&height=640&fit=bounds)















![[DL輪読会]Differentiable Mapping Networks: Learning Structured Map Representatio...](https://cdn.slidesharecdn.com/ss_thumbnails/differentiablemappingnetworks-200707033539-thumbnail.jpg?width=640&height=640&fit=bounds)











