Download as PDF, PPTX

![Documents and collections
{
"_key": "123456",
"_id": "chars/123456",
"name": "Duck",
"firstname": "Donald",
"dob": "1934-11-13",
"hobbies": ["Golf",
"Singing",
"Running"],
"home":
{"town": "Duck town",
"street": "Lake Road",
"number": 17},
"species": "duck"
}
1](https://image.slidesharecdn.com/techtalkgeekdom-150317174601-conversion-gate01/85/Complex-queries-in-a-distributed-multi-model-database-2-320.jpg)
![Documents and collections
{
"_key": "123456",
"_id": "chars/123456",
"name": "Duck",
"firstname": "Donald",
"dob": "1934-11-13",
"hobbies": ["Golf",
"Singing",
"Running"],
"home":
{"town": "Duck town",
"street": "Lake Road",
"number": 17},
"species": "duck"
}
When I say “document”,
I mean “JSON”.
1](https://image.slidesharecdn.com/techtalkgeekdom-150317174601-conversion-gate01/85/Complex-queries-in-a-distributed-multi-model-database-3-320.jpg)
![Documents and collections
{
"_key": "123456",
"_id": "chars/123456",
"name": "Duck",
"firstname": "Donald",
"dob": "1934-11-13",
"hobbies": ["Golf",
"Singing",
"Running"],
"home":
{"town": "Duck town",
"street": "Lake Road",
"number": 17},
"species": "duck"
}
When I say “document”,
I mean “JSON”.
A “collection” is a set of
documents in a DB.
1](https://image.slidesharecdn.com/techtalkgeekdom-150317174601-conversion-gate01/85/Complex-queries-in-a-distributed-multi-model-database-4-320.jpg)
![Documents and collections
{
"_key": "123456",
"_id": "chars/123456",
"name": "Duck",
"firstname": "Donald",
"dob": "1934-11-13",
"hobbies": ["Golf",
"Singing",
"Running"],
"home":
{"town": "Duck town",
"street": "Lake Road",
"number": 17},
"species": "duck"
}
When I say “document”,
I mean “JSON”.
A “collection” is a set of
documents in a DB.
The DB can inspect the
values, allowing for
secondary indexes.
1](https://image.slidesharecdn.com/techtalkgeekdom-150317174601-conversion-gate01/85/Complex-queries-in-a-distributed-multi-model-database-5-320.jpg)
![Documents and collections
{
"_key": "123456",
"_id": "chars/123456",
"name": "Duck",
"firstname": "Donald",
"dob": "1934-11-13",
"hobbies": ["Golf",
"Singing",
"Running"],
"home":
{"town": "Duck town",
"street": "Lake Road",
"number": 17},
"species": "duck"
}
When I say “document”,
I mean “JSON”.
A “collection” is a set of
documents in a DB.
The DB can inspect the
values, allowing for
secondary indexes.
Or one can just treat the
DB as a key/value store.
1](https://image.slidesharecdn.com/techtalkgeekdom-150317174601-conversion-gate01/85/Complex-queries-in-a-distributed-multi-model-database-6-320.jpg)
![Documents and collections
{
"_key": "123456",
"_id": "chars/123456",
"name": "Duck",
"firstname": "Donald",
"dob": "1934-11-13",
"hobbies": ["Golf",
"Singing",
"Running"],
"home":
{"town": "Duck town",
"street": "Lake Road",
"number": 17},
"species": "duck"
}
When I say “document”,
I mean “JSON”.
A “collection” is a set of
documents in a DB.
The DB can inspect the
values, allowing for
secondary indexes.
Or one can just treat the
DB as a key/value store.
Sharding: the data of a
collection is distributed
between multiple servers.
1](https://image.slidesharecdn.com/techtalkgeekdom-150317174601-conversion-gate01/85/Complex-queries-in-a-distributed-multi-model-database-7-320.jpg)







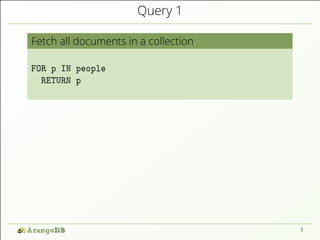
![Query 1
Fetch all documents in a collection
FOR p IN people
RETURN p
[ { "name": "Schmidt", "firstname": "Helmut",
"hobbies": ["Smoking"]},
{ "name": "Neunhöffer", "firstname": "Max",
"hobbies": ["Piano", "Golf"]},
...
]
3](https://image.slidesharecdn.com/techtalkgeekdom-150317174601-conversion-gate01/85/Complex-queries-in-a-distributed-multi-model-database-16-320.jpg)
![Query 1
Fetch all documents in a collection
FOR p IN people
RETURN p
[ { "name": "Schmidt", "firstname": "Helmut",
"hobbies": ["Smoking"]},
{ "name": "Neunhöffer", "firstname": "Max",
"hobbies": ["Piano", "Golf"]},
...
]
(Actually, a cursor is returned.)
3](https://image.slidesharecdn.com/techtalkgeekdom-150317174601-conversion-gate01/85/Complex-queries-in-a-distributed-multi-model-database-17-320.jpg)
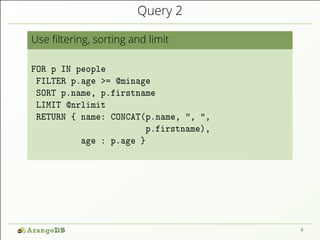
![Query 2
Use filtering, sorting and limit
FOR p IN people
FILTER p.age >= @minage
SORT p.name, p.firstname
LIMIT @nrlimit
RETURN { name: CONCAT(p.name, ", ",
p.firstname),
age : p.age }
[ { "name": "Neunhöffer, Max", "age": 44 },
{ "name": "Schmidt, Helmut", "age": 95 },
...
]
4](https://image.slidesharecdn.com/techtalkgeekdom-150317174601-conversion-gate01/85/Complex-queries-in-a-distributed-multi-model-database-19-320.jpg)

![Query 3
Aggregation and functions
FOR p IN people
COLLECT a = p.age INTO L
FILTER a >= @minage
RETURN { "age": a, "number": LENGTH(L) }
[ { "age": 18, "number": 10 },
{ "age": 19, "number": 17 },
{ "age": 20, "number": 12 },
...
]
5](https://image.slidesharecdn.com/techtalkgeekdom-150317174601-conversion-gate01/85/Complex-queries-in-a-distributed-multi-model-database-21-320.jpg)

![Query 4
Joins
FOR p IN @@peoplecollection
FOR h IN houses
FILTER p._key == h.owner
SORT h.streetname, h.housename
RETURN { housename: h.housename,
streetname: h.streetname,
owner: p.name,
value: h.value }
[ { "housename": "Firlefanz",
"streetname": "Meyer street",
"owner": "Hans Schmidt", "value": 423000
},
...
]
6](https://image.slidesharecdn.com/techtalkgeekdom-150317174601-conversion-gate01/85/Complex-queries-in-a-distributed-multi-model-database-23-320.jpg)
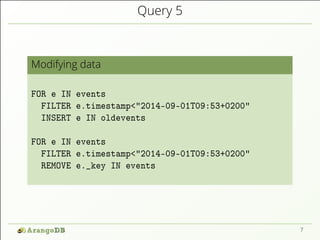

![Query 6
Graph queries
FOR x IN GRAPH_SHORTEST_PATH(
"routeplanner", "germanCity/Cologne",
"frenchCity/Paris", {weight: "distance"} )
RETURN { begin : x.startVertex,
end : x.vertex,
distance : x.distance,
nrPaths : LENGTH(x.paths) }
[ { "begin": "germanCity/Cologne",
"end" : {"_id": "frenchCity/Paris", ... },
"distance": 550,
"nrPaths": 10 },
...
]
8](https://image.slidesharecdn.com/techtalkgeekdom-150317174601-conversion-gate01/85/Complex-queries-in-a-distributed-multi-model-database-26-320.jpg)


















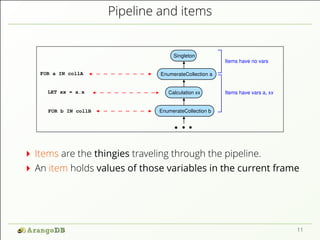
























The document discusses the structure and querying capabilities of a distributed multi-model database, highlighting the use of JSON documents and collections. It covers concepts such as sharding, graph modeling, various query types, and the process of query execution, including parsing, optimization, and execution planning. Additionally, it emphasizes the function of items in execution plans and their transformation through different stages of the processing pipeline.
































































![[Mas 500] Data Basics](https://cdn.slidesharecdn.com/ss_thumbnails/mas-500-4-data-basics-131120205428-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)






















