Downloaded 25 times







![Physical Clocks
To adjust for lengthening of mean solar day,
leap seconds are used to translate TAI into
Universal Coordinated Time (UTC).
UTC is broadcast by NIST from Fort Collins,
Colorado over shortwave radio station WWV.
WWV broadcasts a short pulses at the start
of each UTC second. [accuracy 10 msec.]
GEOS (Geostationary Environment
Operational Satellite) also offer UTC service.
[accuracy 0.5 msec.]
Distributed
Computing Systems 7](https://image.slidesharecdn.com/synch-130411082433-phpapp02/85/Synch-7-320.jpg)










![Lamport Timestamps [1978]
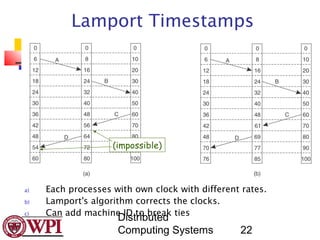
Lamport defined a relation ”happens
before”. a b ‘a happens before b’.
Happens before is observable in two
situations:
1. If a and b are events in the same process,
and a occurs before b, then a b is true.
2. If a is the event of a message being sent
by one process, and b is the event of the
message being received by another
process, then a b is also true.
Distributed
Computing Systems 21](https://image.slidesharecdn.com/synch-130411082433-phpapp02/85/Synch-21-320.jpg)
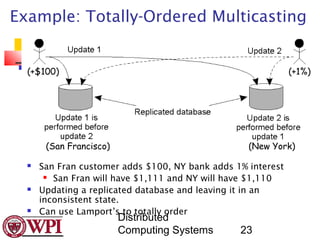



This document provides an overview of clock synchronization in distributed systems. It discusses how physical clocks can differ slightly in frequency and how precise atomic clocks are used to define International Atomic Time (TAI) and Universal Coordinated Time (UTC). It also describes several common clock synchronization algorithms, including Cristian's algorithm, the Berkeley algorithm, and averaging algorithms. Logical clocks are introduced as an alternative to synchronized physical clocks for maintaining consistency in distributed algorithms. Lamport timestamps are presented as a way to totally order events in a distributed system.















































