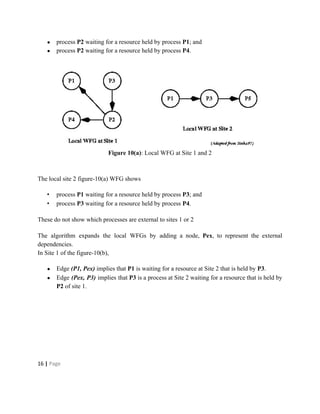
Deadlocks occur when processes are waiting for resources held by other processes, resulting in a circular wait. Four conditions must be met: mutual exclusion, hold and wait, no preemption, and circular wait. Deadlocks can be handled through avoidance, prevention, or detection and recovery. Avoidance algorithms allocate resources only if it ensures the system remains in a safe state where deadlocks cannot occur. Prevention methods make deadlocks impossible by ensuring at least one condition is never satisfied, such as through collective or ordered resource requests. Detection finds existing deadlocks by analyzing resource allocation graphs or wait-for graphs to detect cycles.



![Figure 2: Resource allocation graph with a cycle but no deadlock
Figure 3 - Resource allocation graph with a knot with deadlock
[Knot: subgraph such that starting from any node in the subgraph it is impossible to leave the
knot following the edges of the graph.]
3 | Page](https://image.slidesharecdn.com/deadlock0604-161107052207/85/Deadlock-in-Distributed-Systems-4-320.jpg)