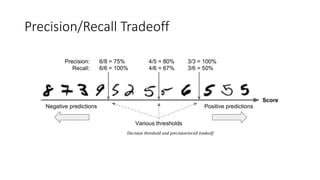
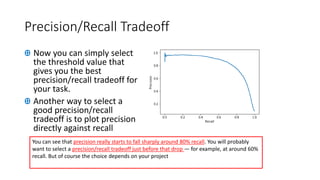
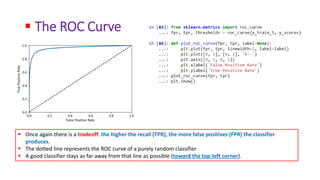
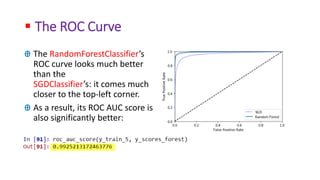
The document discusses classifying handwritten digits from the MNIST dataset using various machine learning classifiers and evaluation metrics. It begins with binary classification of the digit 5 using SGDClassifier, evaluating accuracy which is misleading due to class imbalance. The document then introduces confusion matrices and precision/recall metrics to better evaluate performance. It demonstrates how precision and recall can be traded off by varying the decision threshold, and introduces ROC curves to visualize this tradeoff. Finally, it compares SGDClassifier and RandomForestClassifier on this binary classification task.











![Performance Measures
Ꚛ Evaluating a classifier is often significantly trickier than evaluating a
regressor
Ꚛ Let’s use the cross_val_score() function to evaluate your SGDClassifier
model using K-fold crossvalidation, with three folds.
Ꚛ Remember that K-fold cross-validation means splitting the training set
into K-folds (in this case, three), then making predictions and evaluating
them on each fold using a model trained on the remaining folds
▪ from sklearn.model_selection import cross_val_score
▪ cross_val_score(sgd_clf, X_train, y_train_5, cv=3, scoring="accuracy")
▪ Out[24]: array([0.94555, 0.9012 , 0.9625 ])
Ꚛ Wow! Around 95% accuracy (ratio of correct predictions) on all cross-
validation folds? This looks amazing, doesn’t it?](https://image.slidesharecdn.com/hwknmajmrfk2q6n51lrk-signature-8de60c98476d684bd50cee58acbea27ff40abfe38959d4d51c6e1d5d4629c2e1-poli-200307202646/85/Lecture-12-binary-classifier-confusion-matrix-11-320.jpg)



























































![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt2931-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt3441-thumbnail.jpg?width=640&height=640&fit=bounds)