This document summarizes research on using data mining techniques to predict heart disease. It discusses previous work using classification, clustering, association rule mining and other techniques on several heart disease datasets. Classification algorithms like naive bayes, decision trees and neural networks have been widely used with naive bayes found to often provide the best performance. Feature selection and attribute reduction are also examined. The document provides an overview of the key steps and techniques in medical data mining and predictive analysis for heart disease.








![Data Mining anD association rules
Carlos Ordonez and et. Al.,[7] used a simple mapping
algorithm.
Treats numerical or categorical attributes as uniform.
Decision tree is incapable – it automatically split
numerical value. (Medical data are in numerical format )
Interpreting experimental result by D.T is difficult
Clustering medical data deserves further research
Justify the use of A.R in Medical data](https://image.slidesharecdn.com/surveyondataminingtechniquesinheartdiseaseprediction-140604222418-phpapp02/85/Survey-on-data-mining-techniques-in-heart-disease-prediction-9-320.jpg)
![contD…Deepika [11] used Pruning Classification Association
Rule (PCAR).
PCAR comes from Apriori algorithm.
Deletes minimum frequency item with minimum
frequency item sets.
Deletes infrequent item from item sets.
Classifies item based on frequency of item sets and
discovers frequent item sets.](https://image.slidesharecdn.com/surveyondataminingtechniquesinheartdiseaseprediction-140604222418-phpapp02/85/Survey-on-data-mining-techniques-in-heart-disease-prediction-10-320.jpg)
![Data Mining anD classification
Usha Rani[38], used ANN in heart disease using feed
forward and back propagation algorithm.
Experiment by single and multi layered neural network
models.
Parallelism is implemented to speed up learning process.
Neural network provides satisfactory results](https://image.slidesharecdn.com/surveyondataminingtechniquesinheartdiseaseprediction-140604222418-phpapp02/85/Survey-on-data-mining-techniques-in-heart-disease-prediction-11-320.jpg)
![contD….
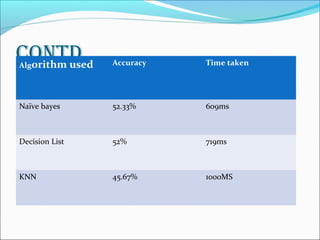
In [3], Classification is based on Supervised machine
learning Algorithm.
Tanagara tool is used to classify data
Evaluation by using 10 fold cross validation.
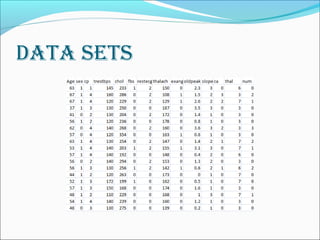
The performance is analysed based on accuracy and time
taken to build the model.
Naïve bayes is the better algorithm
The table below shows the perfomance study of algorithm](https://image.slidesharecdn.com/surveyondataminingtechniquesinheartdiseaseprediction-140604222418-phpapp02/85/Survey-on-data-mining-techniques-in-heart-disease-prediction-12-320.jpg)
![contD..
In [24], novel neuro fuzzy techniques is used.
Preprocess by using Genetic Algorithm(GA).
A four layered fuzzy neural network is used.
Radial Basic Function neural network is constructed with
5 input, training and normalization in hidden layer and
output layer with 1 node.
In [25], Intelligent Heart Disease Prediction System
(IHDPS )is proposed using Decision Tree, NB and Neural
network.
NB is the most effective one.](https://image.slidesharecdn.com/surveyondataminingtechniquesinheartdiseaseprediction-140604222418-phpapp02/85/Survey-on-data-mining-techniques-in-heart-disease-prediction-14-320.jpg)
![Contd..
In [1], GA is used to determine the number of attributes.
NB, D.T., Classification by Clustering are compared.
DT takes more time to build the model.
NB performs consistently before and after reduction
of attributes.
CVC is poor in performance](https://image.slidesharecdn.com/surveyondataminingtechniquesinheartdiseaseprediction-140604222418-phpapp02/85/Survey-on-data-mining-techniques-in-heart-disease-prediction-15-320.jpg)
![Contd..
In [30], k-means clustering algorithm is used.
Maximal Frequent Item Set Algorithm (MAFIA) is used.
Multilayer perception network and back propagation algorithm is used as
training algorithm.
Pseudo code for MAFIA [29]:
MAFIA(C, MFI, Boolean IsHUT) {
name HUT = C.head C.tail;
if HUT is in MFI
stop generation of children and return
Count all children, use PEP to trim the tail, and recorder by increasing support,
For each item i in C, trimmed_tail {
IsHUT = whether i is the first item in the tail
newNode = C I
MAFIA (newNode, MFI, IsHUT)}
if (IsHUT and all extensions are frequent)
Stop search and go back up subtree
If (C is a leaf and C.head is not in MFI)
Add C.head to MFI
}](https://image.slidesharecdn.com/surveyondataminingtechniquesinheartdiseaseprediction-140604222418-phpapp02/85/Survey-on-data-mining-techniques-in-heart-disease-prediction-16-320.jpg)
![Contd…
In [35], Naïve Bayes is used for predicting Decision Support in heart
disease prediction System.
NB is found to be best in heart disease prediction.
It can be used as a tool for training nurses and medical students for
diagnosing.
It provides new ways of understanding and exploring the data.
In [6], NB Classification can be used as a best decision support system.
In [10], hybridization is used to train the neural network using GA. Feed
forward and Back propagation is used as a learning algorithm.
When two more attributes are added with existing attributes, Neural
Network shows better performance in both the cases.](https://image.slidesharecdn.com/surveyondataminingtechniquesinheartdiseaseprediction-140604222418-phpapp02/85/Survey-on-data-mining-techniques-in-heart-disease-prediction-17-320.jpg)
![Contd..
RIPPER, SVM, Decision Tree and ANN are compared
based on Sensitivity, Specificity, Accuracy, Error Rate,
TP AND FP Rate. [20]
SVM predicts with least error rate and higher
accuracy.
DM with Fuzzy Logic reduces the number of attributes
and number of tests for the patients.[21]](https://image.slidesharecdn.com/surveyondataminingtechniquesinheartdiseaseprediction-140604222418-phpapp02/85/Survey-on-data-mining-techniques-in-heart-disease-prediction-18-320.jpg)
![data Mining and
Clustering
K-means clustering algorithm is used for the prediction of the
heart disease[4].
Euclidean distance formula is used
NB is slow and Neural network takes number of iterations.
Performance of clustering and classification algorithm is
compared [28].
NB predicts with highest accuracy than Clustering Algorithm.](https://image.slidesharecdn.com/surveyondataminingtechniquesinheartdiseaseprediction-140604222418-phpapp02/85/Survey-on-data-mining-techniques-in-heart-disease-prediction-19-320.jpg)





























































































