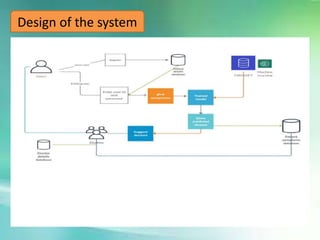
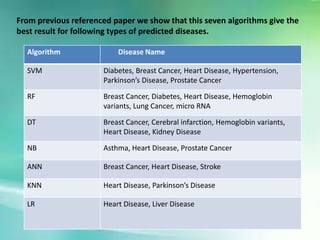
The document summarizes a disease prediction system for rural health services presented by two students. The key points are:
1. The system aims to provide quick medical diagnosis to rural patients using machine learning algorithms like SVM, RF, DT, NB, ANN, KNN, and LR to recognize diseases from symptoms.
2. It seeks to enhance access to medical specialists for rural communities and improve quality of healthcare.
3. The expected outcomes are conducting experiments to evaluate the performance of using 7 machine learning algorithms to predict diseases from symptoms and having doctors select the correct diagnosis from the predictions.