Download to read offline

















![Research for MBA - Gideon S. du Toit - MBA P/T 2003/6 - Page 10 of 51
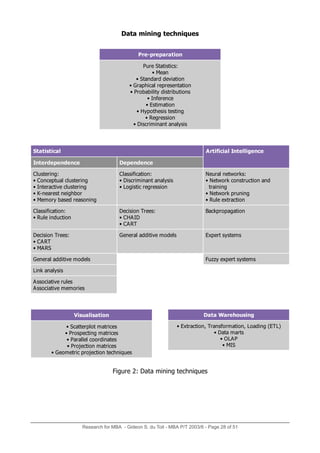
• Network construction and training: in this phase, a layered neural network based on
the number of attributes, number of classes, and chosen input coding method are
trained and constructed.
• Network pruning: in this phase, redundant links and units are removed without in-
creasing the classification error rate of the network.
• Rule extraction: classification rules are extracted in this phase (Lee & Siau, 2001)
Backpropagation systems
These techniques are highly supervised. The backprop neural network model is ideal for
prediction and classification in situations where there is a good deal of historic data available
for training. This tool uses output variables generated by the neural network that are cor-
rected by adjusting the weights of the hidden layer variables until the output variables match
those in the training dataset (Gargano & Raggad, 1999; Chidley, 2002).
Expert systems
Expert systems are made up of a knowledge base of rules (extracted from experts), facts (or
data), and a logic based inference engine (or control) that creates new rules and facts based
on previously accumulated knowledge and facts. Expert systems attempt to mimic, with
some success, the reasoning of human experts whose knowledge of a specific and narrow
domain is deep, thus permitting human experts and expert systems to arrive at similar
conclusions, thus serving to justify the system's existence by improving the expert decision
maker's own productivity. The expert system thus operates using queries formulated by
human experts and incorporated into the system. Expert systems do not rely on algorithmic
or statistical methods and cannot solve problems that have not been defined during the
programming of the model (Jackson, 1990; Gargano & Raggad, 1999; Chidley, 2002).
Jackson (1990:4) listed the following characteristics for expert systems:
• They simulate human reasoning,
• They perform reasoning "over representations of human knowledge",
• Heuristic or approximate methods are used to solve problems (which does not guar-
antee success as would have been the case had algorithmic techniques or solutions
been used).
Fuzzy expert systems
Fuzzy expert systems employ fuzzy logic concepts and were developed in an attempt to try
and solve the brittleness problem inherent in expert systems. The truth or falsity of a fact
can be measured in a fuzzy way using values from the real number interval zero to one
inclusive (i.e. [0, 1]). In expert systems, information is either totally false (i.e. zero) or
totally true (i.e. one), but in fuzzy expert systems, true values can lie anywhere on the zero
to one interval of real numbers. Some facts are close to being true or close to being false
(having low entropy), while other facts lie close to the middle between being true or false
(having high entropy). Using fuzzy operators, such as AND, OR, NOT, VERY, and SOME-
WHAT, the system can make fuzzy implications. Fuzzy systems can easily handle illogical
complexities, poor clarity (in the facts and/or rules), or internal inconsistencies (Gargano &
Raggad, 1999).](https://image.slidesharecdn.com/8a927f33-5541-45aa-aa57-1ad0bd9c0d47-150209030654-conversion-gate02/85/GSduToit_MBA_Research_Report_2006-17-320.jpg)






























![Koh, H.C. Low, C.K. (2004): Going concern prediction using data mining techniques,
Managerial Auditing, 19(3):462-476.
Lee, S.J. Siau, K. (2001): A review of data mining techniques, Industrial Management
and Data Systems, 101(1):41-46.
Leedy, P.D. Ormrod, J.E. (2001): Practical Research: Planning and Design, New Jer-
sey: Merill Prentice Hall.
Lewis-Beck M.S., Berry, W.D., Feldman, S., Fox, J. Hardy, M.A. (1993): Applied Regres-
sion: An introduction, in Regression Analysis, M.S. Lewis-Beck, (Ed.), second edition,
Iowa: Sage Publications, 1-18.
Marshall, C. Rossman, G.B., (1989): Designing Qualitative Research, London : Sage
Publications.
Mitchell, T.M. (1999): Machine Learning and Data Mining, Communications of the ACM,
42(11):30-36.
Mitchell, T.M. (2005): Machine Learning. Draft of chapter 1 for inclusion into the new
edition of the book Machine Learning, [http://www.cs.cmu.edu/~tom/mlbook.html] (Ac-
cessed 26th
February 2005).
Nemati H.R. Barko C.D. (2003): Key factors for achieving organizational data-mining
success, Journal of Industrial Management and Data Systems, 103(4):282-292.
Parr Rud, O. (2001): Introduction in Data Mining Cookbook, R.M. Elliott, E. Herman, J.
Atkins B. Snapp (Eds.), Canada: Wiley and Sons, Inc.
Pirow, P.C. (1990): How To Do Business Research, Johannesburg: Juta Publishers.
Rencher, A.C. (1995): Methods of Multivariate Analysis, New York: Wiley and Sons, Inc.
Sung, T.K., Chang, N. Lee, G. (1999): Dynamics of modeling in data mining: Interpre-
tive approach to bankruptcy prediction, Management Information Systems, 16(1):63-86.
Vickery, B. (1997): Knowledge Discovery from Databases : An Introductory Review, The
Journal of Documentation, 53(2):107–122.
Walker, R. (1985): Applied Qualitative Research, Aldershot: Gower Publishing Company
Limited.
Zwick, M. (2004): An overview of reconstructability analysis, Kybernetes, 33(5):877-
882.
Research for MBA - Gideon S. du Toit - MBA P/T 2003/6 - Page 44 of 51](https://image.slidesharecdn.com/8a927f33-5541-45aa-aa57-1ad0bd9c0d47-150209030654-conversion-gate02/85/GSduToit_MBA_Research_Report_2006-51-320.jpg)


![Research for MBA - Gideon S. du Toit - MBA P/T 2003/6 - Page 47 of 51
APPENDIX B
Telephone Protocol
The purpose of the call: to set up an in-depth interview with the respondent.
Speaking to the Referred Expert Respondent
Hello Mr/ Ms ....................................., my name is Gideon du Toit. I am a MBA student at
Wits Business School and I am currently conducting research on data mining in the credit
and data bureaus in South Africa.
Mr/Ms ..................................... at/ in ..................................... suggested that I speak to
you about the possibility of you contributing to the research given your expertise in the area.
The research I am conducting explores the different techniques used in data mining and the
uses of these techniques to the bureaus and their clients. The research is based on in-depth
interviews with key players and experts in this field.
I would really like to discuss this area with you. The discussion should take about an hour of
your time. If you wish your contributions were anonymous and neither your name nor
company were linked to any statements or comments made.
A very exciting aspect of the research is the fact that no academic research currently exists
on data mining by the bureaus in the local market and I believe the results have a very
valuable contribution to make. For assisting with this research, you will receive a copy of the
research findings and I would also be glad to make a presentation of the findings at a
suitable forum, if you should wish.
Based on this, would you be interested in participating? [If yes, schedule date, time, place of
interview, and parking. If no, explore reasons for objections and if necessary, request refer-
ral.]](https://image.slidesharecdn.com/8a927f33-5541-45aa-aa57-1ad0bd9c0d47-150209030654-conversion-gate02/85/GSduToit_MBA_Research_Report_2006-54-320.jpg)





This document discusses a research report on evaluating data mining techniques in the credit and data bureau sector. It investigated common data mining techniques and algorithms, their uses, and potential future directions. The researcher conducted interviews with an expert panel from the sector to understand the current applications of techniques, benefits, and possibilities. Thirty-five techniques across descriptive statistics, inferential statistics, data reduction, and other categories were identified. Eighteen current uses were also uncovered. The research found that while many techniques were not yet widely used, especially among smaller bureaus, the future benefits of data mining could lead to broader adoption.



























