Download to read offline



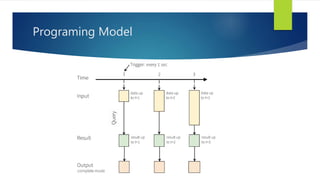

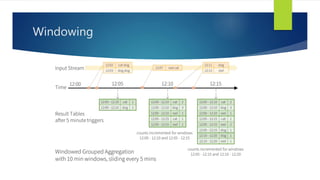


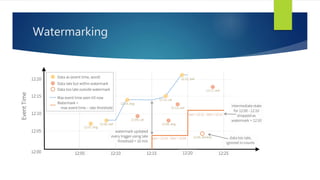
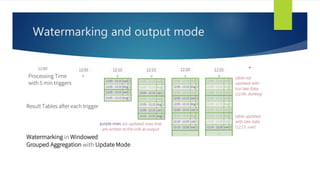
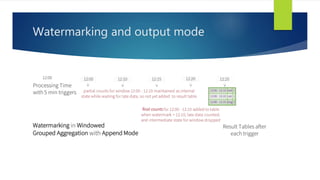

Structured Streaming is a scalable and fault-tolerant stream processing engine in Spark SQL that allows expressing streaming computations like batch computations. It includes three output modes: append, complete, and update, allowing different ways of handling results as new data arrives. The implementation is still in alpha stage in Spark 2.1, with experimental APIs for streaming aggregation and event-time windows.
































































































