Downloaded 42 times









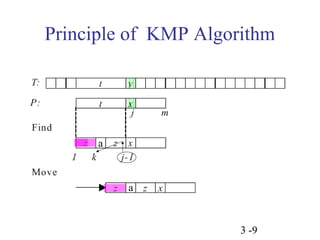





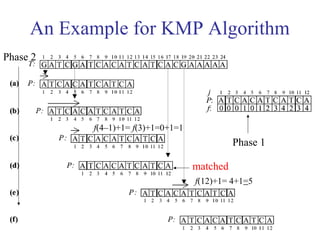


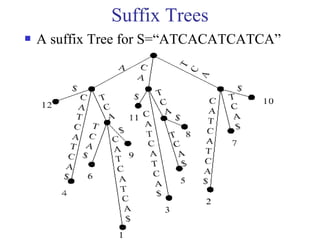



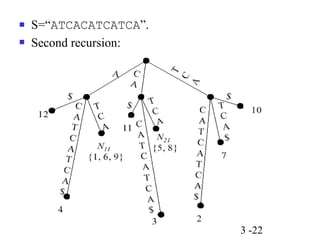










This document discusses string matching algorithms. It begins by defining the string matching problem and providing an example. It then discusses terminologies used in string matching. It provides an overview of the brute force algorithm and two-phase algorithms like KMP and Boyer-Moore. It explains the KMP algorithm in detail, including calculating the prefix function and using it in the matching process. It also discusses suffix trees and suffix arrays, providing algorithms to construct them and use them for string matching. Finally, it covers approximate string matching using dynamic programming and suffix edit distance.



































































































