Download as PDF, PPTX


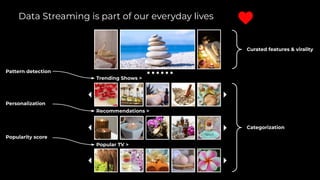
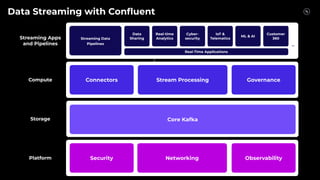
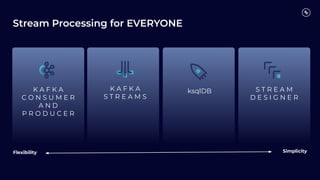

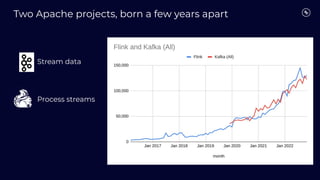



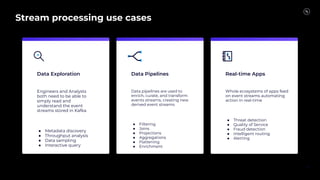
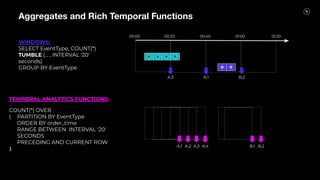
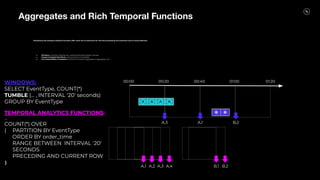
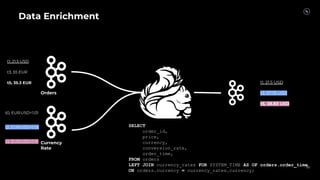
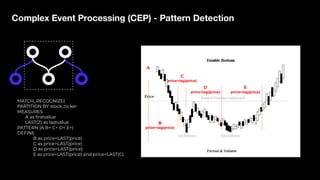

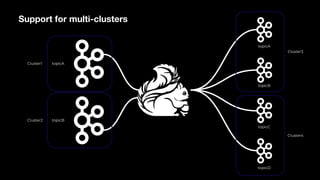
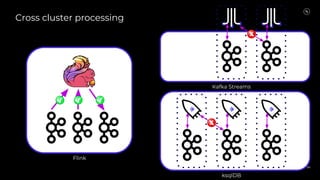

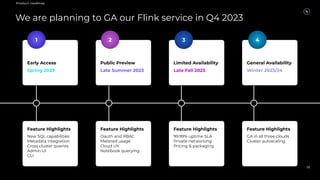
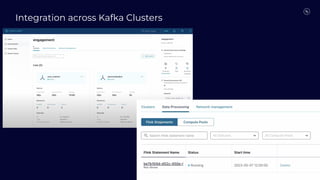
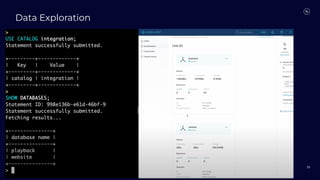
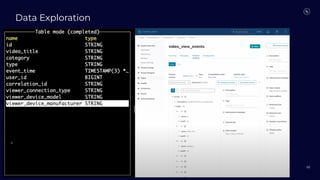
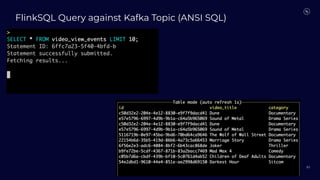
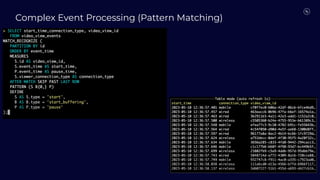


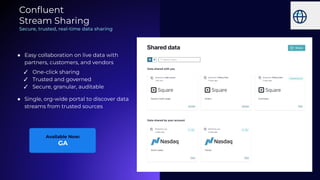
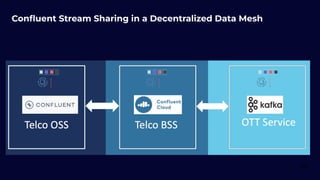




Stream Processing with Apache Flink in the Cloud and Stream Sharing Kai Waehner discusses stream processing use cases with Apache Flink and introduces Confluent's plans to offer a serverless Apache Flink service in Confluent Cloud. He also discusses Confluent Stream Sharing, which allows for easy and secure sharing of Kafka topics across organizations in real-time.























































































