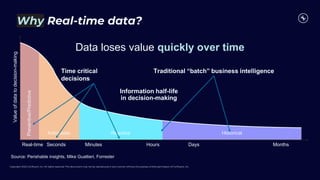
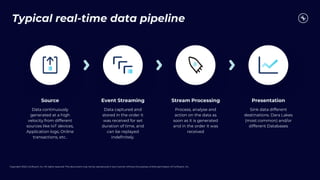
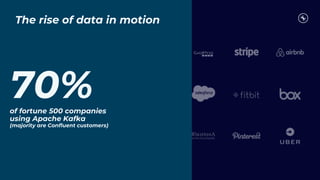
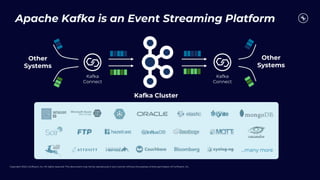
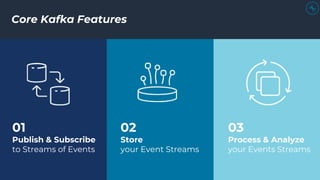
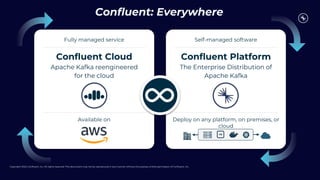
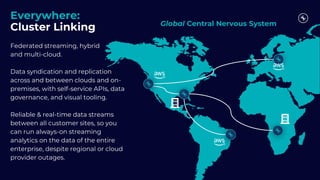
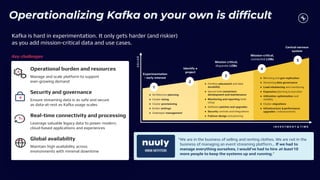
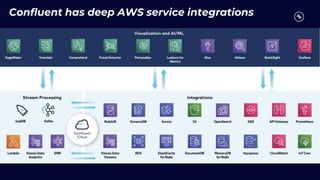
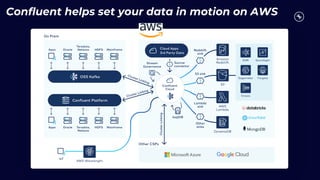
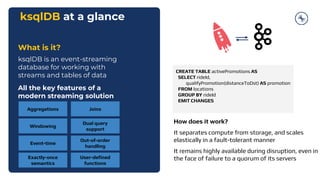
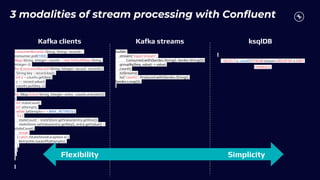
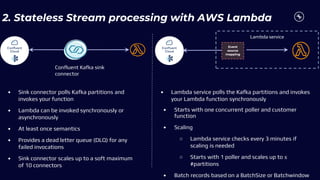
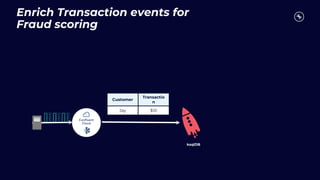
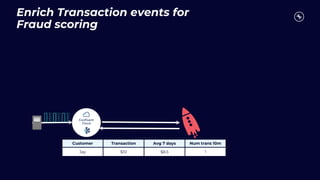
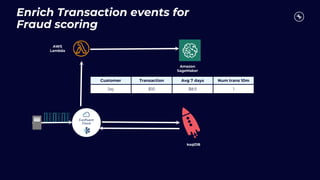
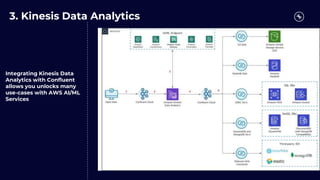
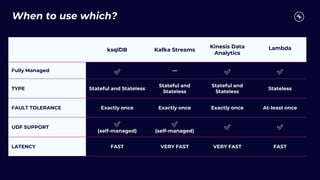
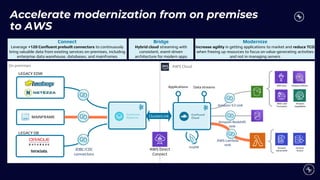
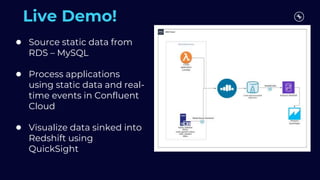
This document discusses building real-time analytics pipelines using Confluent and AWS. It describes how Confluent makes real-time data streams a top priority through features like Apache Kafka. It also explains how to build a typical real-time data pipeline using an event streaming platform to capture, process, and analyze streaming data in real-time. Additionally, it covers how Confluent and AWS can be used together to unlock various use cases across industries through deep integrations and services. Finally, it provides an overview of different stream processing options on AWS including ksqlDB, Kafka Streams, Kinesis Data Analytics, and AWS Lambda.