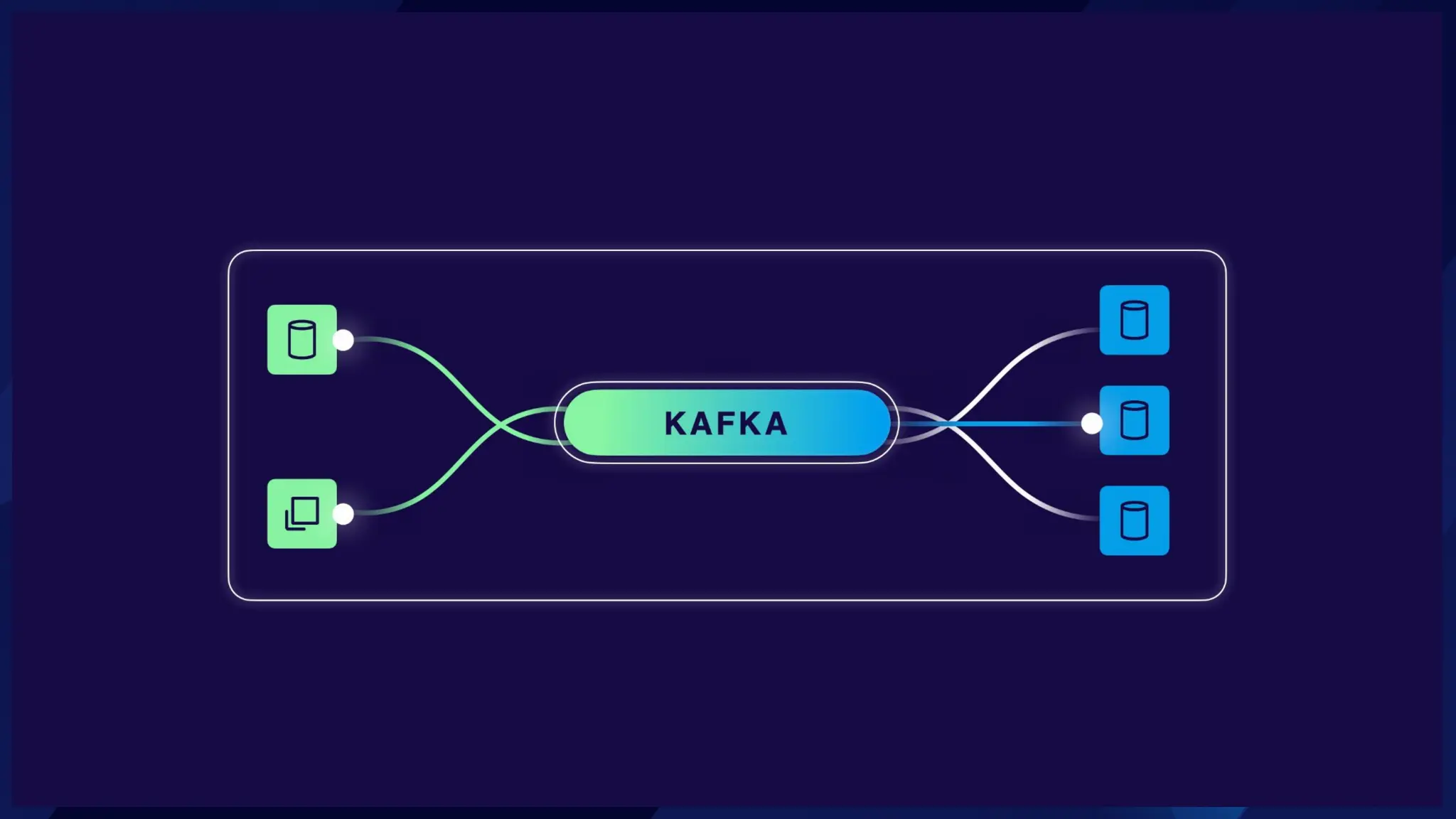
7
최저 0달러부터
확장 시작하기
대부분의
애플리케이션에맞게
운영 환경에
적용하기
프라이빗
네트워킹으로
보안 강화
BASIC STANDARD ENTERPRISE
최대 수십 GBps
규모까지 모든
애플리케이션에 맞게
사용자 지정 가능
DEDICATED
조직 전체에서 모든 클러스터 유형을 자유롭게 조합하여 사용 가능
즉각적인 자동 확장 클러스터 사전 프로비저닝된 클러스터
요구 사항과 사용 사례에 맞는 비용 효율적인 클러스터 유형
8.
8
최저 0달러부터
확장 시작하기
대부분의
애플리케이션에
맞게
운영환경에
적용하기
프라이빗
네트워킹으로
보안 강화
BASIC STANDARD ENTERPRISE
최대 수십 GBps
규모까지 모든
애플리케이션에
맞게 사용자 지정
가능
DEDICATED
지연 시간에 민감하지 않은
워크로드를 위한 저비용
대용량 클러스터
FREIGHT
즉각적인 자동 확장 클러스터 사전 프로비저닝된
클러스터
조직 전체에서 모든 클러스터 유형을 자유롭게 조합하여 사용 가능
요구 사항과 사용 사례에 맞는 비용 효율적인 클러스터 유형
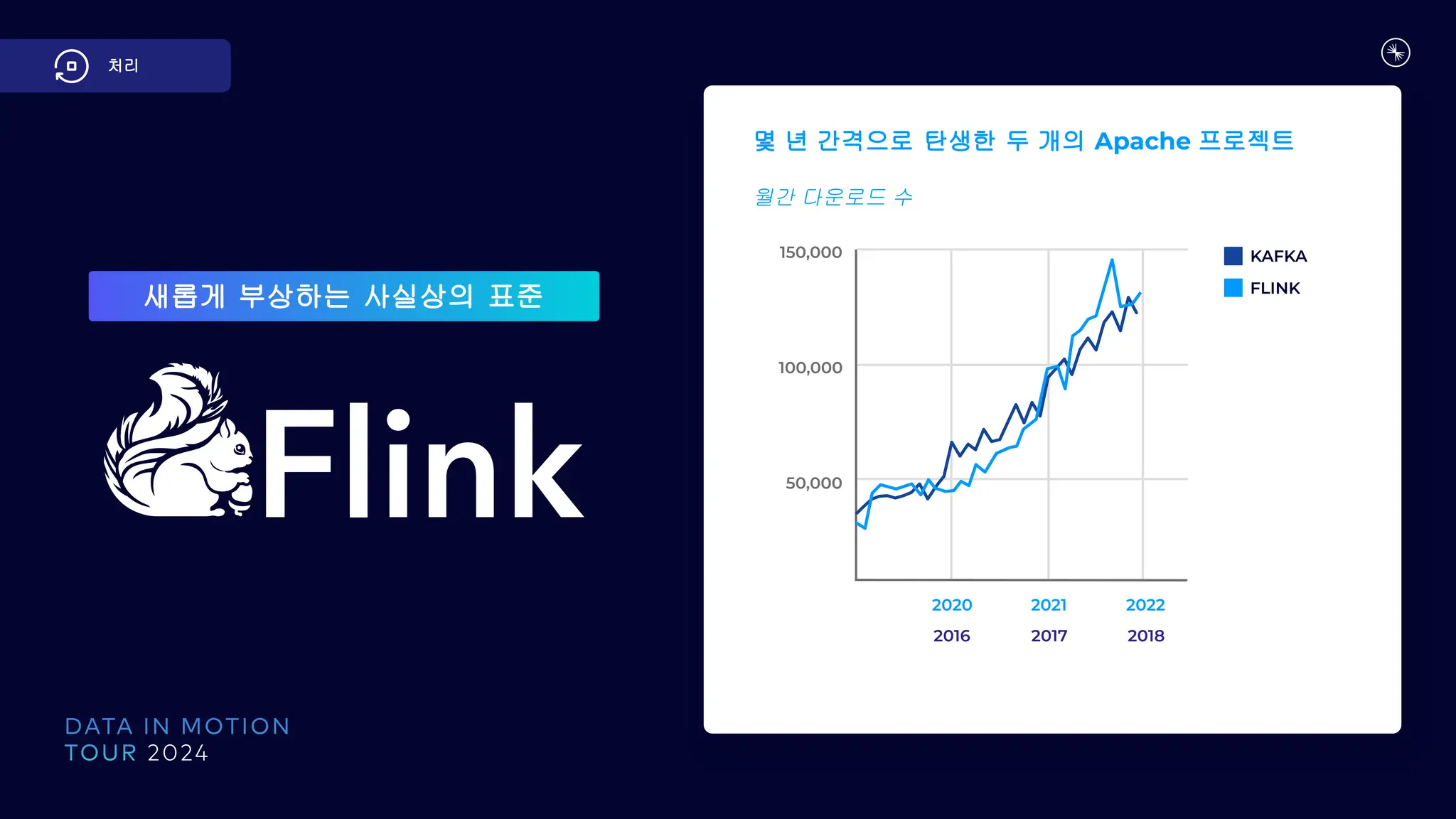
새로운 패러다임:
데이터 스트리밍플랫폼 및 범용 데이터 제품
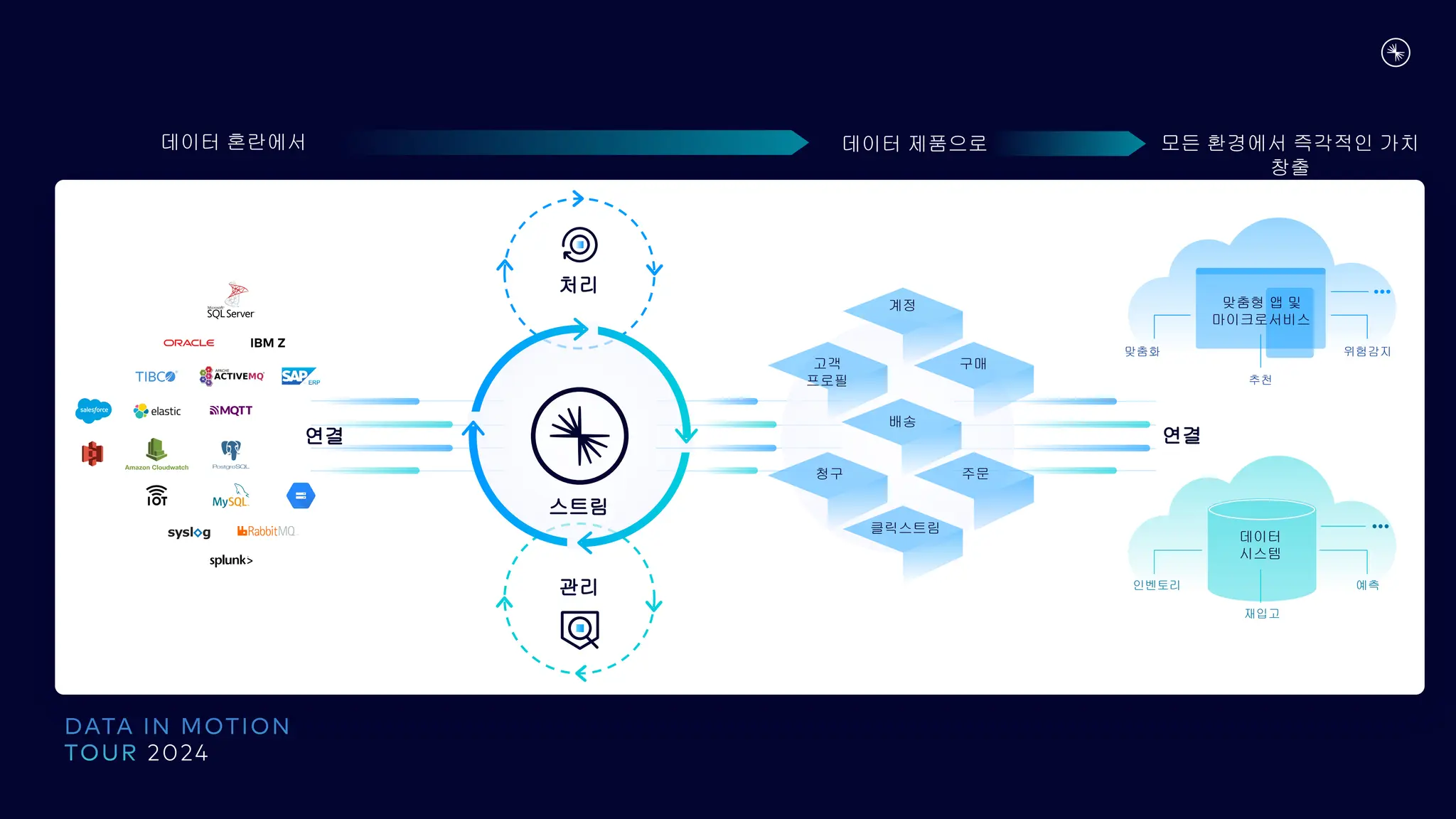
데이터 혼란에서 데이터 제품으로 모든 환경에서 즉각적인 가치
창출
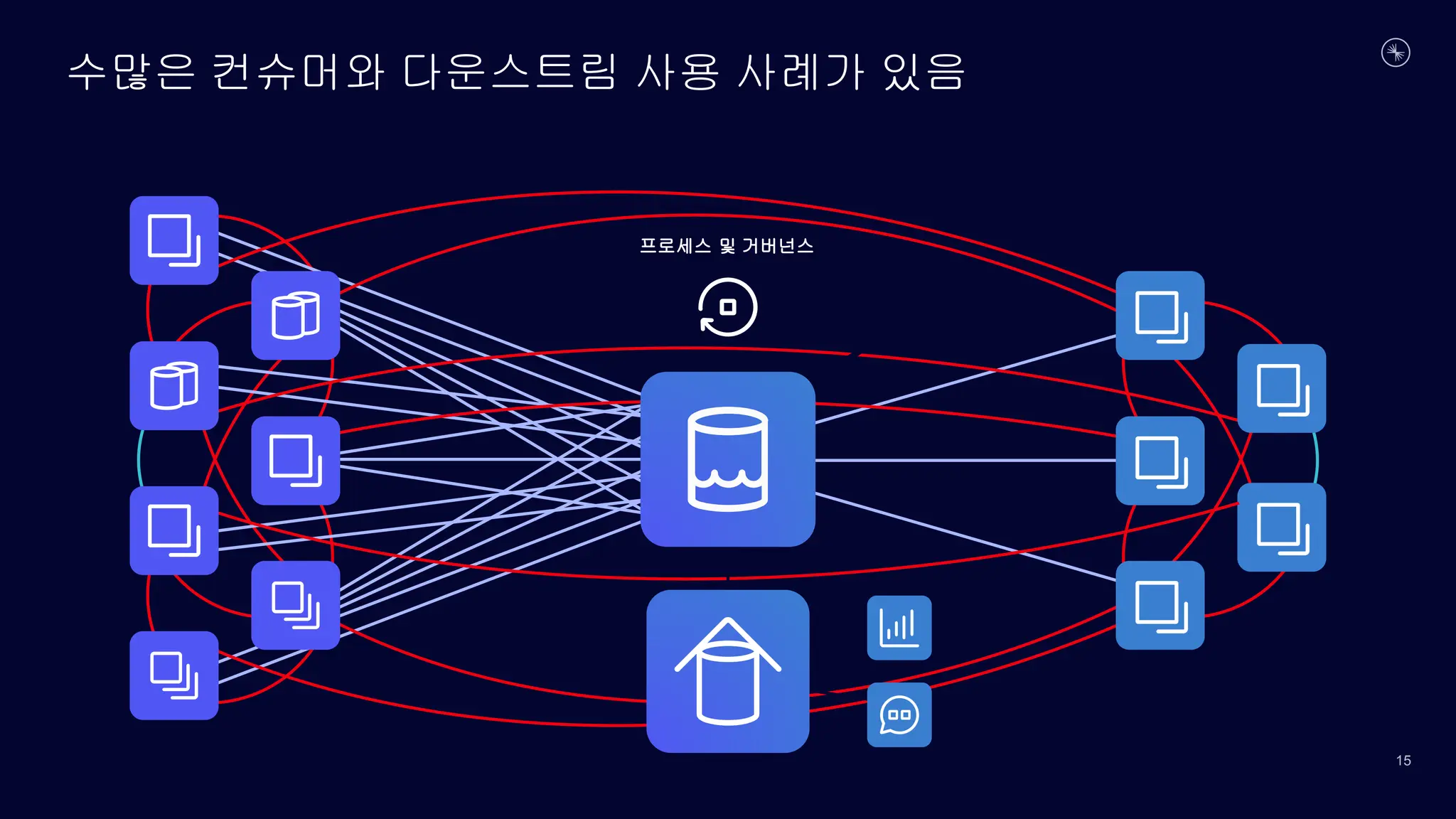
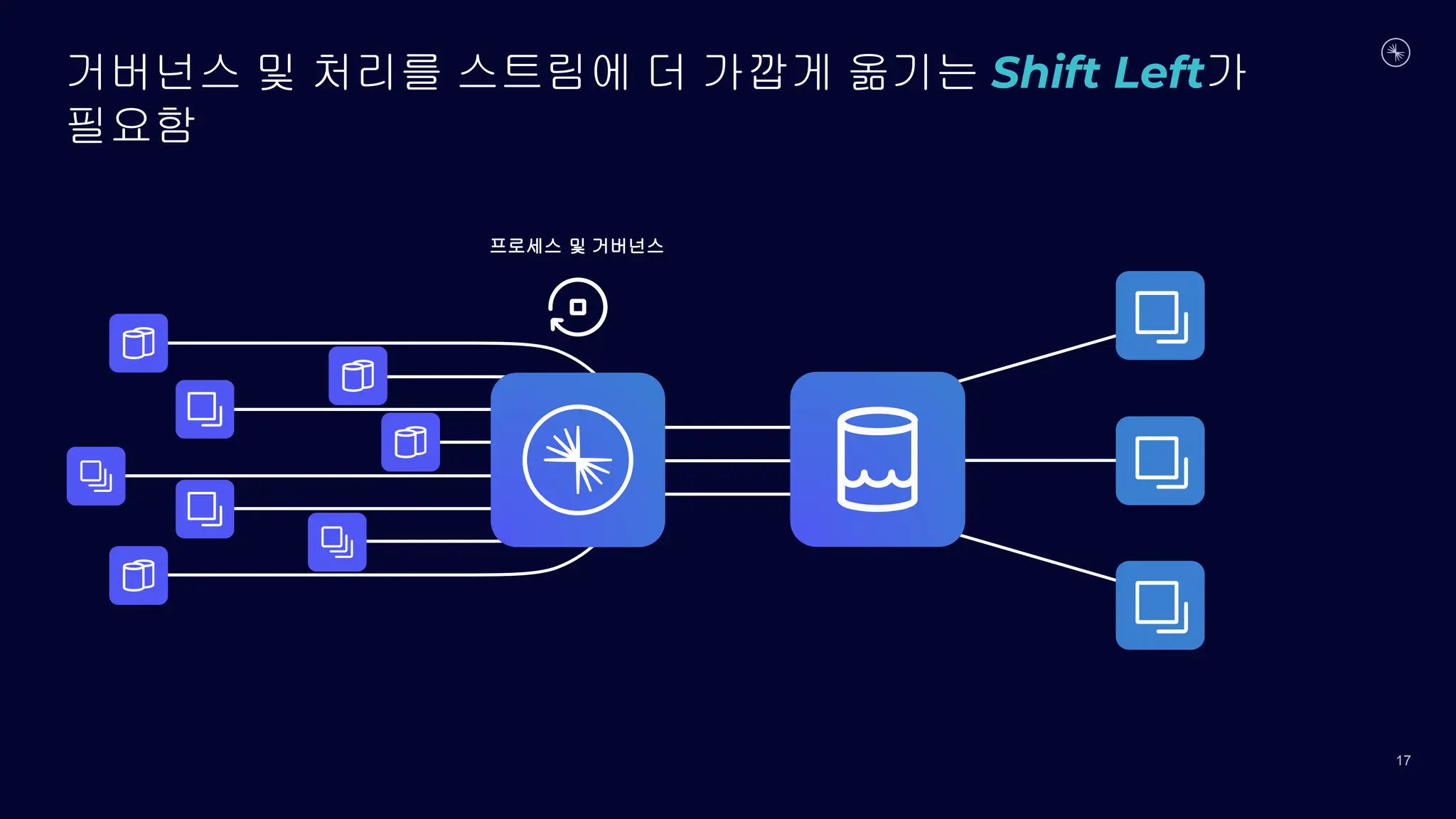
연결
처리
관리
스트림
계정
고객
프로필
구매
배송
청구 주문
클릭스트림
연결
데이터
시스템
인벤토리
재입고
예측
…
맞춤형 앱 및
마이크로서비스
맞춤화
추천
위험감지
…
21.
악순환 대신 선순환...
온라인구매
매장 구매
고객 세부 정보
구매
클릭스트림
Customer 360 분석 보고서
생성형 AI
온라인 앱
데이터 스트리밍 업계선두 주자
Forrester Wave(™): 2023년 4분기 스트리밍 데이터 플랫폼 부문 Forrester Wave(™): 2023년 4분기 클라우드 데이터 파이프라인 부문
34.
60%
TCO 절감
250% 이상
3년ROI
Confluent 사용의 종합적인 경제적 효과 • Forrester, 2022년 3월
"Confluent Cloud 덕분에 제한된 리소스로 빠듯한 출시 일정을 맞출 수 있었습니다 . 관리형 서비스로 제공되는 이벤트 스트리밍을 통해
비용이 많이 드는 인력 채용 없이 클러스터를 유지 관리할 수 있었고 24시간 연중무휴 안정성에 대해 걱정할 필요가 없었습니다 ."
고객의 비용 절감 및 ROI 향상













































![[Confluent] 실시간 하이브리드, 멀티 클라우드 데이터 아키텍처로 빠르게 혀...](https://cdn.slidesharecdn.com/ss_thumbnails/confluent-220504043130-thumbnail.jpg?width=640&height=640&fit=bounds)









![[Main Session] 카프카, 데이터 플랫폼의 최강자](https://cdn.slidesharecdn.com/ss_thumbnails/180519-kafka-oraclefin-180521125323-thumbnail.jpg?width=640&height=640&fit=bounds)

![[ 2021 AI + X 여름 캠프 ] 2. 장비 상호 연결 kafka를 이용한 매체 전송](https://cdn.slidesharecdn.com/ss_thumbnails/2-210731153335-thumbnail.jpg?width=640&height=640&fit=bounds)





















