Download as PDF, PPTX




















![Kafka Streams DSL
25
public static void main(String[] args) {
// specify the processing topology by first reading in a stream from a topic
KStream<String, String> words = builder.stream(”topic1”);
// count the words in this stream as an aggregated table
KTable<String, Long> counts = words.countByKey(”Counts”);
// write the result table to a new topic
counts.to(”topic2”);
// create a stream processing instance and start running it
KafkaStreams streams = new KafkaStreams(builder, config);
streams.start();
}](https://image.slidesharecdn.com/june28500confluentwang-160711180519/85/Stream-Processing-made-simple-with-Kafka-25-320.jpg)
![Kafka Streams DSL
26
public static void main(String[] args) {
// specify the processing topology by first reading in a stream from a topic
KStream<String, String> words = builder.stream(”topic1”);
// count the words in this stream as an aggregated table
KTable<String, Long> counts = words.countByKey(”Counts”);
// write the result table to a new topic
counts.to(”topic2”);
// create a stream processing instance and start running it
KafkaStreams streams = new KafkaStreams(builder, config);
streams.start();
}](https://image.slidesharecdn.com/june28500confluentwang-160711180519/85/Stream-Processing-made-simple-with-Kafka-26-320.jpg)
![Kafka Streams DSL
27
public static void main(String[] args) {
// specify the processing topology by first reading in a stream from a topic
KStream<String, String> words = builder.stream(”topic1”);
// count the words in this stream as an aggregated table
KTable<String, Long> counts = words.countByKey(”Counts”);
// write the result table to a new topic
counts.to(”topic2”);
// create a stream processing instance and start running it
KafkaStreams streams = new KafkaStreams(builder, config);
streams.start();
}](https://image.slidesharecdn.com/june28500confluentwang-160711180519/85/Stream-Processing-made-simple-with-Kafka-27-320.jpg)
![Kafka Streams DSL
28
public static void main(String[] args) {
// specify the processing topology by first reading in a stream from a topic
KStream<String, String> words = builder.stream(”topic1”);
// count the words in this stream as an aggregated table
KTable<String, Long> counts = words.countByKey(”Counts”);
// write the result table to a new topic
counts.to(”topic2”);
// create a stream processing instance and start running it
KafkaStreams streams = new KafkaStreams(builder, config);
streams.start();
}](https://image.slidesharecdn.com/june28500confluentwang-160711180519/85/Stream-Processing-made-simple-with-Kafka-28-320.jpg)
![Kafka Streams DSL
29
public static void main(String[] args) {
// specify the processing topology by first reading in a stream from a topic
KStream<String, String> words = builder.stream(”topic1”);
// count the words in this stream as an aggregated table
KTable<String, Long> counts = words.countByKey(”Counts”);
// write the result table to a new topic
counts.to(”topic2”);
// create a stream processing instance and start running it
KafkaStreams streams = new KafkaStreams(builder, config);
streams.start();
}](https://image.slidesharecdn.com/june28500confluentwang-160711180519/85/Stream-Processing-made-simple-with-Kafka-29-320.jpg)
![Kafka Streams DSL
30
public static void main(String[] args) {
// specify the processing topology by first reading in a stream from a topic
KStream<String, String> words = builder.stream(”topic1”);
// count the words in this stream as an aggregated table
KTable<String, Long> counts = words.countByKey(”Counts”);
// write the result table to a new topic
counts.to(”topic2”);
// create a stream processing instance and start running it
KafkaStreams streams = new KafkaStreams(builder, config);
streams.start();
}](https://image.slidesharecdn.com/june28500confluentwang-160711180519/85/Stream-Processing-made-simple-with-Kafka-30-320.jpg)





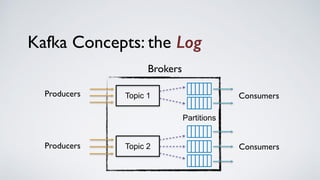

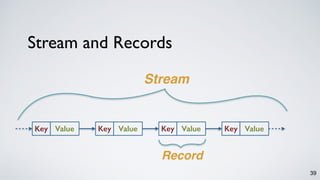
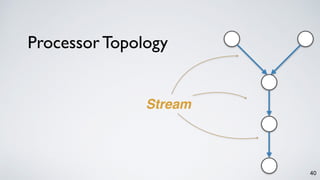
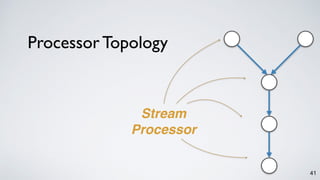





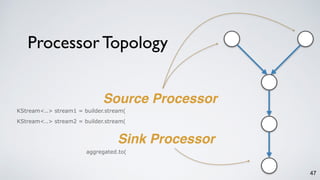
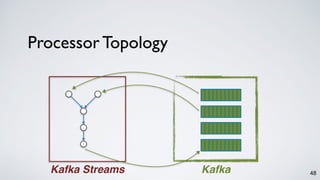
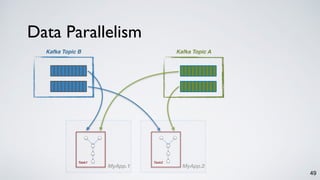
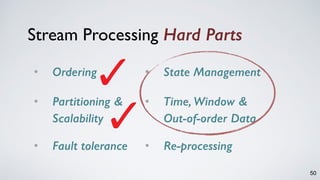
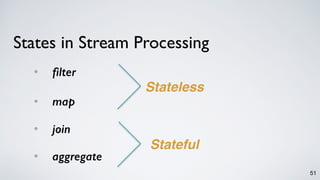
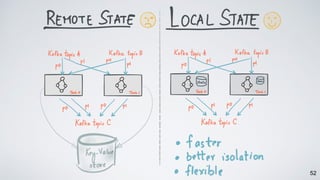

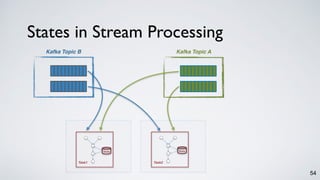






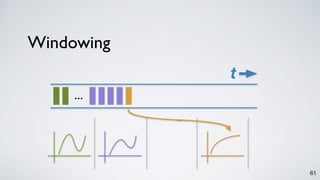
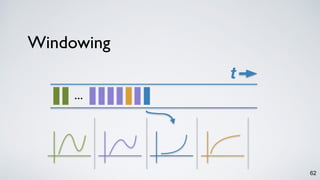
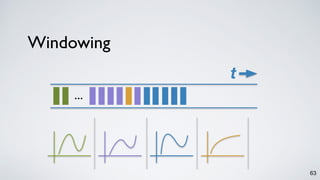
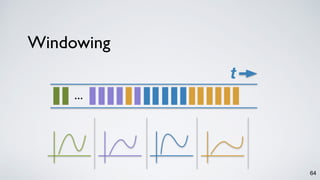
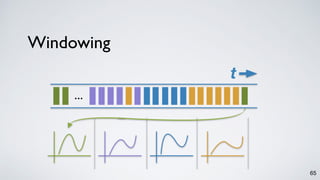
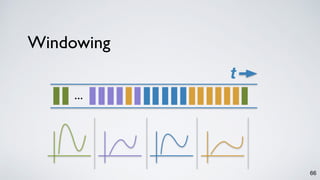





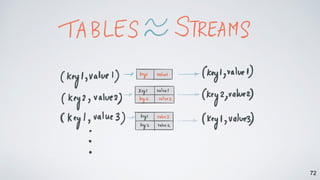


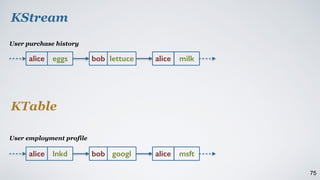
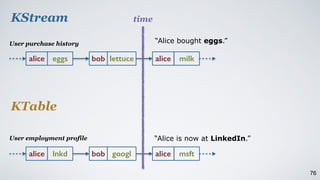
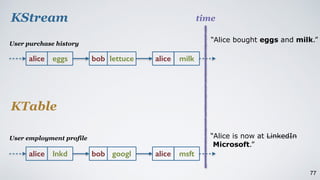
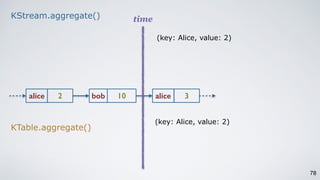
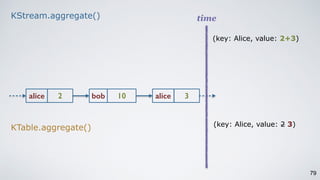
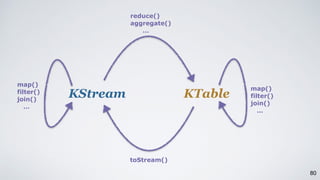
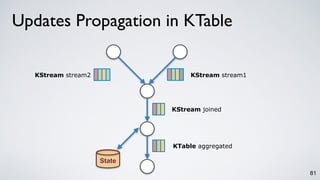
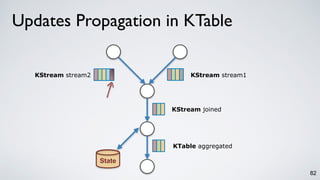
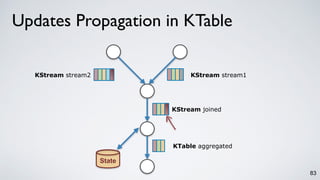
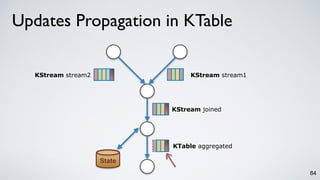

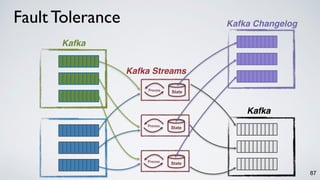
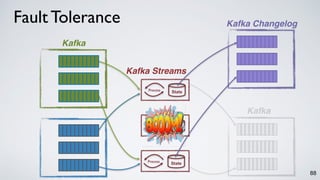
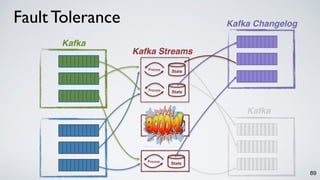
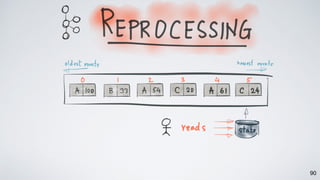
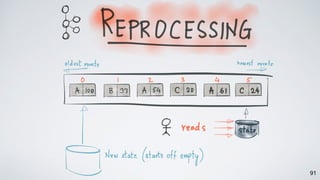
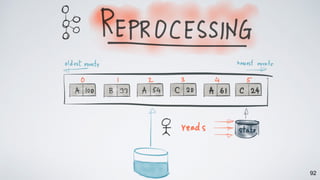
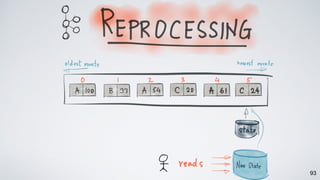



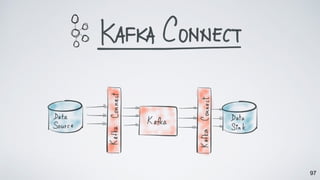
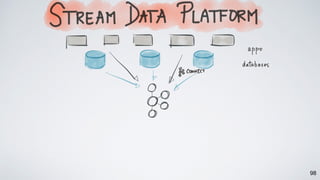
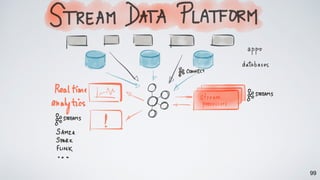
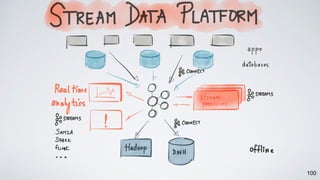





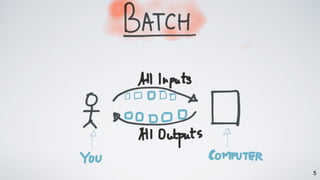
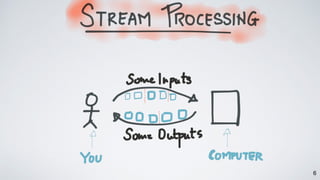
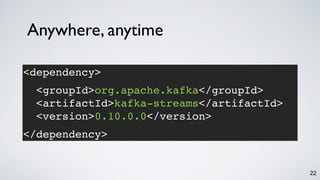
Kafka Streams is a lightweight stream processing library included in Apache Kafka since version 0.10. It provides a simple yet powerful API for building stream processing applications. The API uses a domain-specific language that allows developers to define stream processing topologies where data from Kafka topics acts as input streams and can be transformed before writing the results to output topics. The library handles common stream processing tasks like state management, windowing, and fault tolerance using Kafka's distributed and fault-tolerant architecture.











































































































