
Download as PDF, PPTX

![The case of Business Process Management
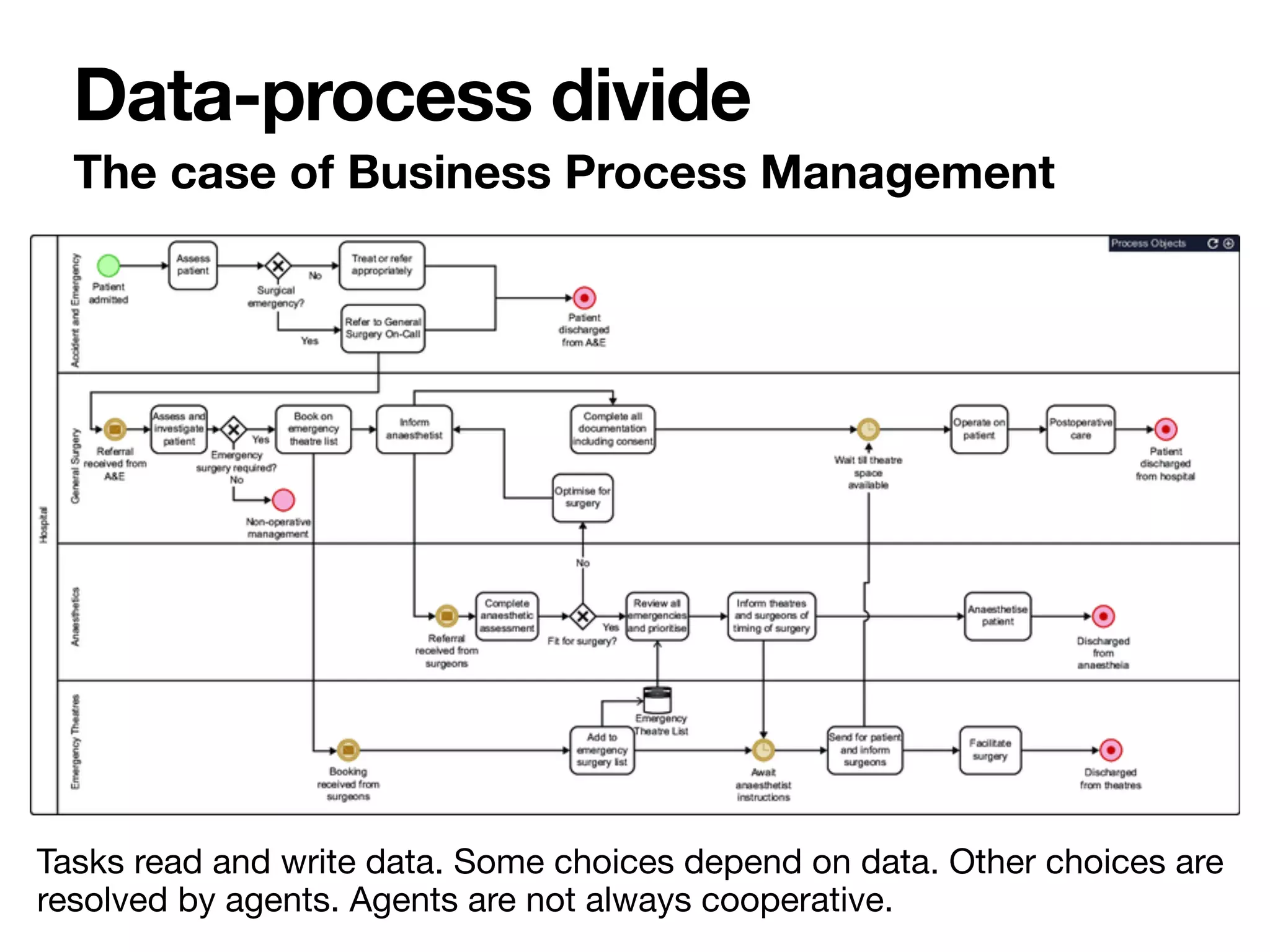
Data-process divide
Cer. Exp.
(date)
Length
(m)
Draft
(m)
Capacity
(TEU)
Cargo
(mg/cm2)
0 0 0 0 0
Enter
y, n
U
Ship Clearance
today
> today < 260 < 10 < 1000
> today < 260 < 10 1000
> today < 260 [10,12] < 4000 0.75
> today < 260 [10,12] < 4000 > 0.75
> today [260,320) (10,13] < 6000 0.5
> today [260,320) (10,13] < 6000 > 0.5
> today [320,400) 13 > 4000 0.25
> today [320,400) 13 > 4000 > 0.25
n
y
n
y
n
y
n
y
n
1
2
3
4
5
6
7
8
9
Table 1: DMN representation of the ship clearance decision of Figure 1b
Enter Length
(m)
Cargo
(mg/cm2)
y,n 0 0
Refuel Area
none, indoor, outdoor
U
Refuel area determination
n
y 350
y > 350 0.3
y > 350 > 0.3
none
indoor
indoor
outdoor
1
2
3
4
Table 2: DMN representation of the refuel area determination decision of Figure 1b
er their corresponding datatypes. In Table 1, the input attributes are: (i) the certificate expira-
on date, (ii) the length, (iii) the size, (iv) the capacity, and (v) the amount of cargo residuals of
ship. Such attributes are nonnegative real numbers; this is captured by typing them as reals,
ding restriction “ 0” as facet. The rightmost, red cell represents the output attribute. In both
ses, there is only one output attribute, of type string. The cell below enumerates the possible
tput values produced by the decision table, in descending priority order. If a default output is
fined, it is underlined. This is the case for the none string in Table 2.
Every other row models a rule. The intuitive interpretation of such rules relies on the usual
f . ..then ...” pattern. For example, the first rule of Table 1 states that, if the certificate of the
ip is expired, then the ship cannot enter the port, that is, the enter output attribute is set to n
egardless of the other input attributes). The second rule, instead, states that, if the ship has a
lid certificate, a length shorter than 260 m, a draft smaller than 10 m, and a capacity smaller
an 1000 TEU, then the ship is allowed to enter the port (regardless of the cargo residuals it
rries). Other rules are interpreted similarly.
Ship
id-code
name
Certi
fi
cate
exp-date
Harbor
location
Attempt
when
outcome
tried entering into
owns
1
0..1
* *
receive
entrance request
record
ship info
inspect ship
ship id
acquire
certificate
record
cargo
residuals
record
exp. date
cargo residuals
certificate exp. date
decice
clearance
enter
refuel area
enter?
send
refusal
send
fuel area info
open
dock
N
Y
ship type (short name)](https://image.slidesharecdn.com/kr2020-dds-synthesis-final-220819224639-0691cdfb/75/Strategy-Synthesis-for-Data-Aware-Dynamic-Systems-with-Multiple-Actors-4-2048.jpg)

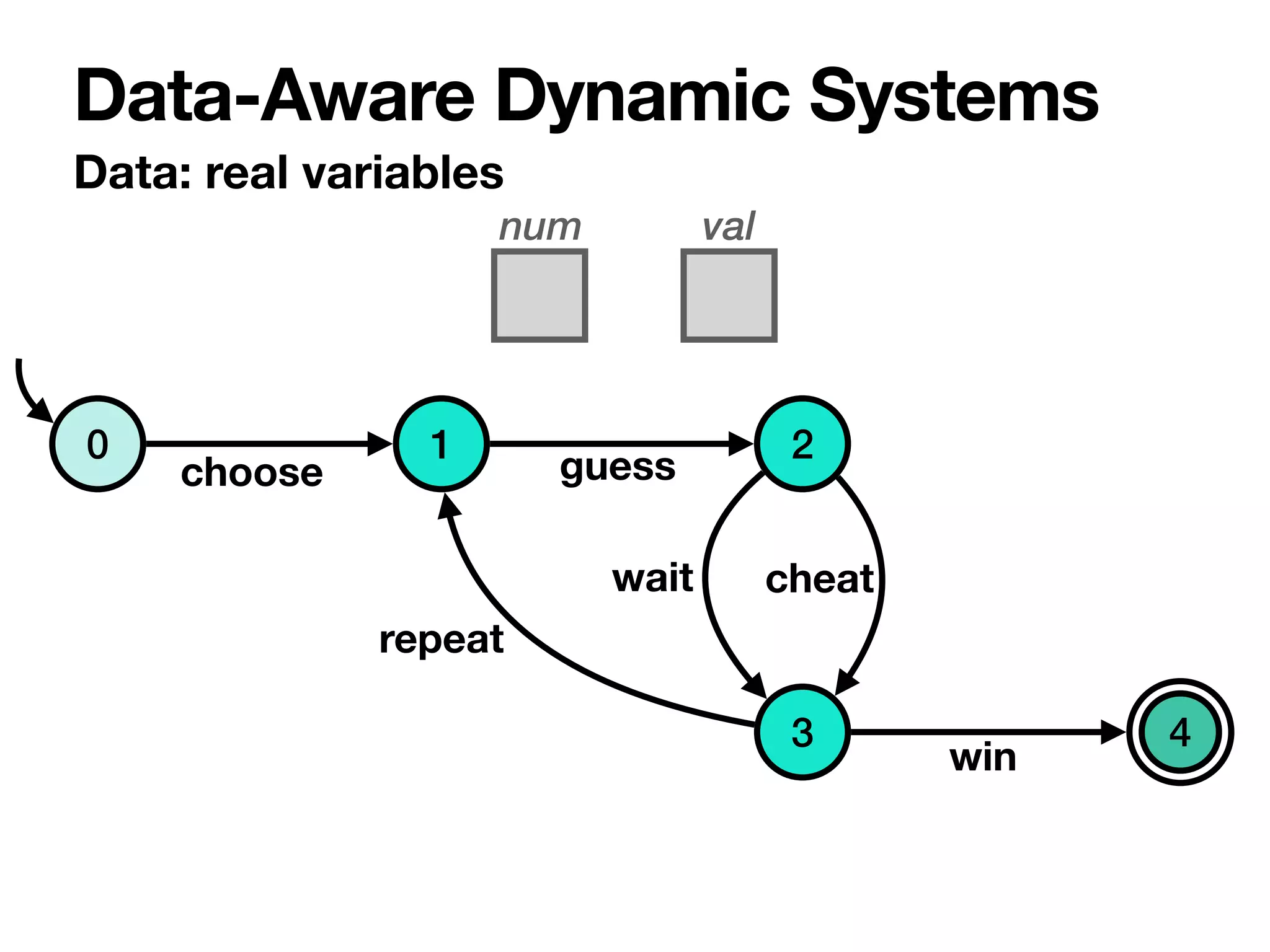
![Glue: read/write guards
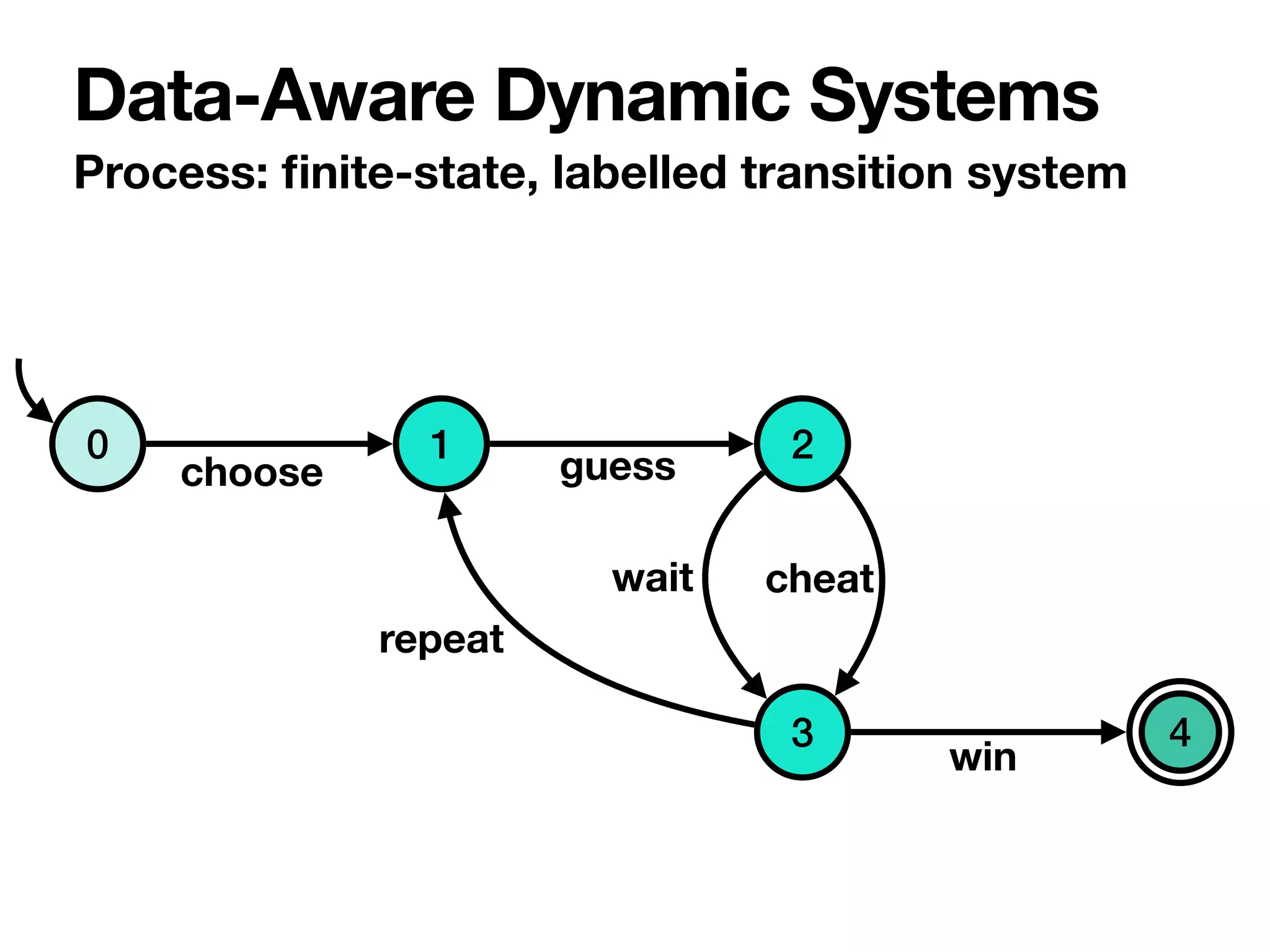
Data-Aware Dynamic Systems
0 1 2
1
4
3
choose
repeat
guess
wait cheat
win
num val
[ numw > 0 ] [ valw ≥ valr ]
[ valr ≥ numr ]
[ numw ≥ valr ]](https://image.slidesharecdn.com/kr2020-dds-synthesis-final-220819224639-0691cdfb/75/Strategy-Synthesis-for-Data-Aware-Dynamic-Systems-with-Multiple-Actors-9-2048.jpg)
![Agents: control of actions, choices, variables
Data-Aware Dynamic Systems
0 1 2
1
4
3
choose
repeat
guess
wait cheat
win
num val
[ numw > 0 ] [ valw ≥ valr ]
[ valr ≥ numr ]
[ numw ≥ valr ]](https://image.slidesharecdn.com/kr2020-dds-synthesis-final-220819224639-0691cdfb/75/Strategy-Synthesis-for-Data-Aware-Dynamic-Systems-with-Multiple-Actors-10-2048.jpg)
![Agents: control of actions, choices, variables
Data-Aware Dynamic Systems
0 1 2
1
4
3
choose
repeat
guess
wait cheat
win
num val
[ numw > 0 ] [ valw ≥ valr ]
[ valr ≥ numr ]
[ numw ≥ valr ]](https://image.slidesharecdn.com/kr2020-dds-synthesis-final-220819224639-0691cdfb/75/Strategy-Synthesis-for-Data-Aware-Dynamic-Systems-with-Multiple-Actors-11-2048.jpg)
![Simple and useful
Corresponds to a model of data-aware Petri nets
studied in the literature (bounded, with interleaving
semantics). [Mannhardt, PhD Thesis 2018]
Captures BPMN with case data + DMN: two OMG
standard for process and decision modelling. [_, ER2018]
A fragment can be discovered from event logs using
existing process discovery techniques. [Mannhardt et al,
CAiSE2016]
Why this model?
Interlude](https://image.slidesharecdn.com/kr2020-dds-synthesis-final-220819224639-0691cdfb/75/Strategy-Synthesis-for-Data-Aware-Dynamic-Systems-with-Multiple-Actors-12-2048.jpg)
![Con
fi
guration: state+variable assignment
Executing a DDS
0 1 2
1
4
3
choose
repeat
guess
wait cheat
win
num val
[ numw > 0 ] [ valw ≥ valr ]
[ valr ≥ numr ]
[ numw ≥ valr ]
t
o
k
e
n
o
n
s
t
a
t
e
variable assignment](https://image.slidesharecdn.com/kr2020-dds-synthesis-final-220819224639-0691cdfb/75/Strategy-Synthesis-for-Data-Aware-Dynamic-Systems-with-Multiple-Actors-13-2048.jpg)
![Run: a
fi
nite trace with legal assignments
Executing a DDS
0 1 2
1
4
3
choose
repeat
guess
wait cheat
win
num val
[ numw > 0 ] [ valw ≥ valr ]
[ valr ≥ numr ]
[ numw ≥ valr ]
✓
s1,
⇢
num 50
val 0
◆](https://image.slidesharecdn.com/kr2020-dds-synthesis-final-220819224639-0691cdfb/75/Strategy-Synthesis-for-Data-Aware-Dynamic-Systems-with-Multiple-Actors-14-2048.jpg)

![…
…
…
…
…
…
…
…
…
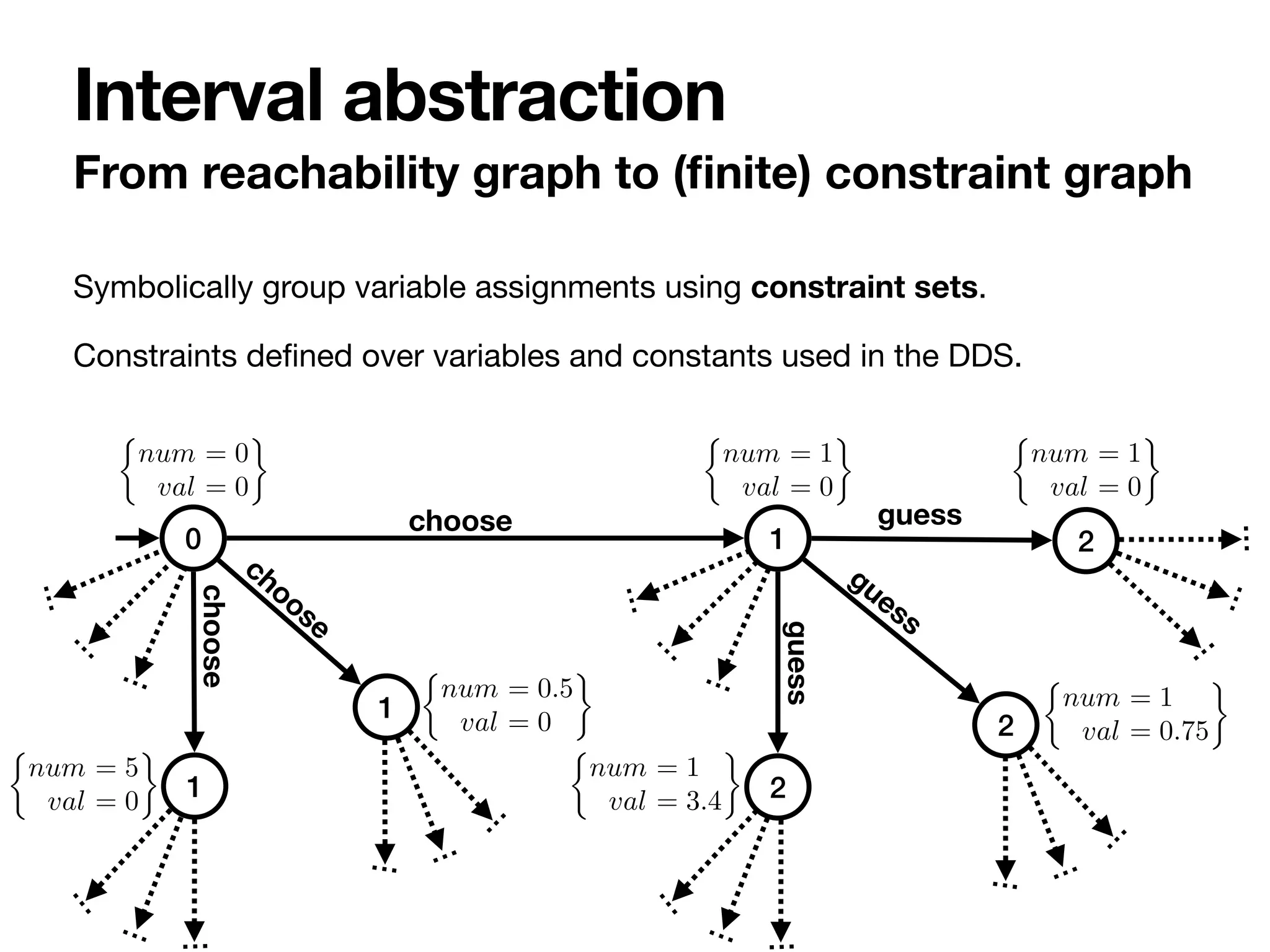
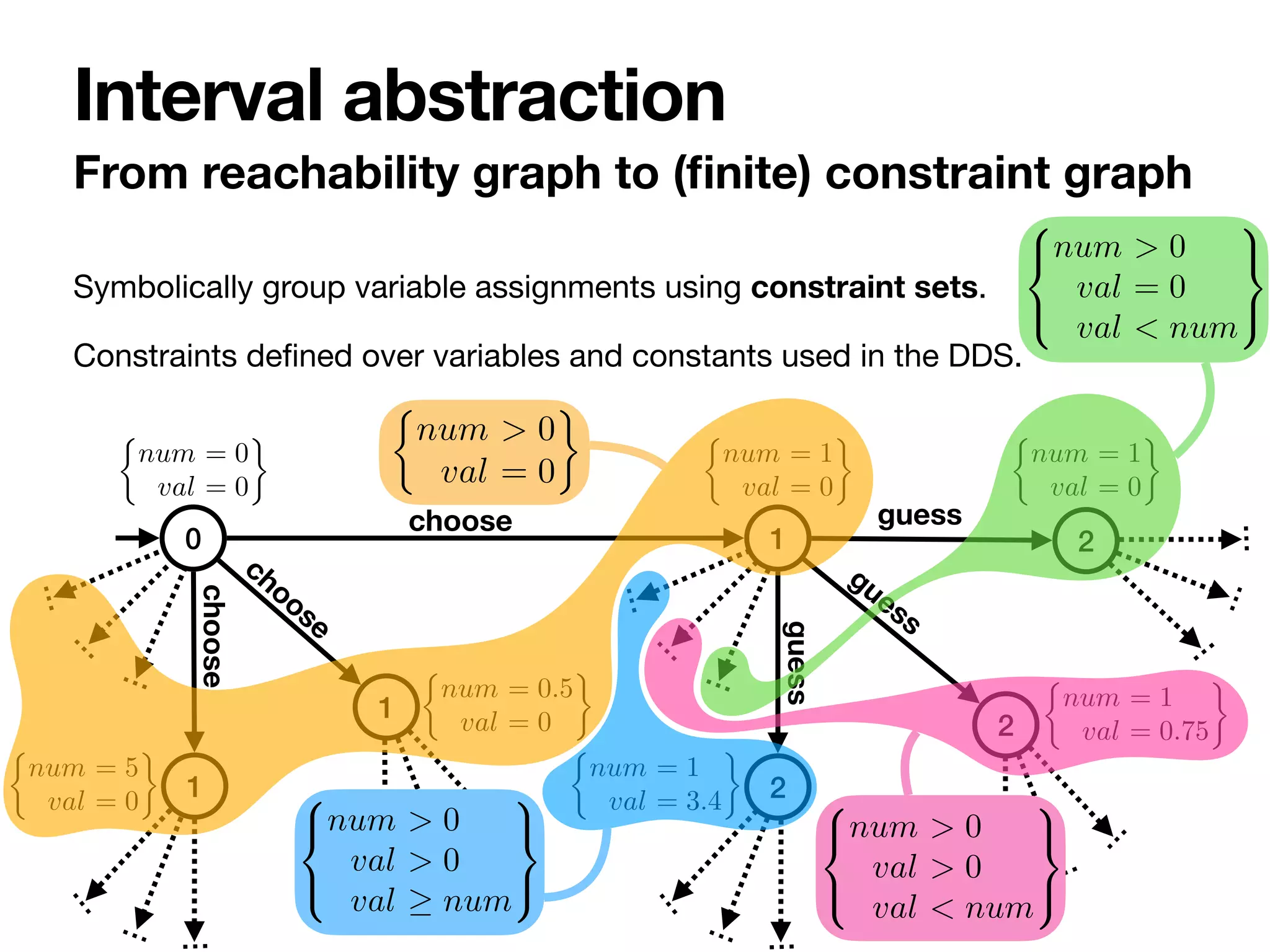
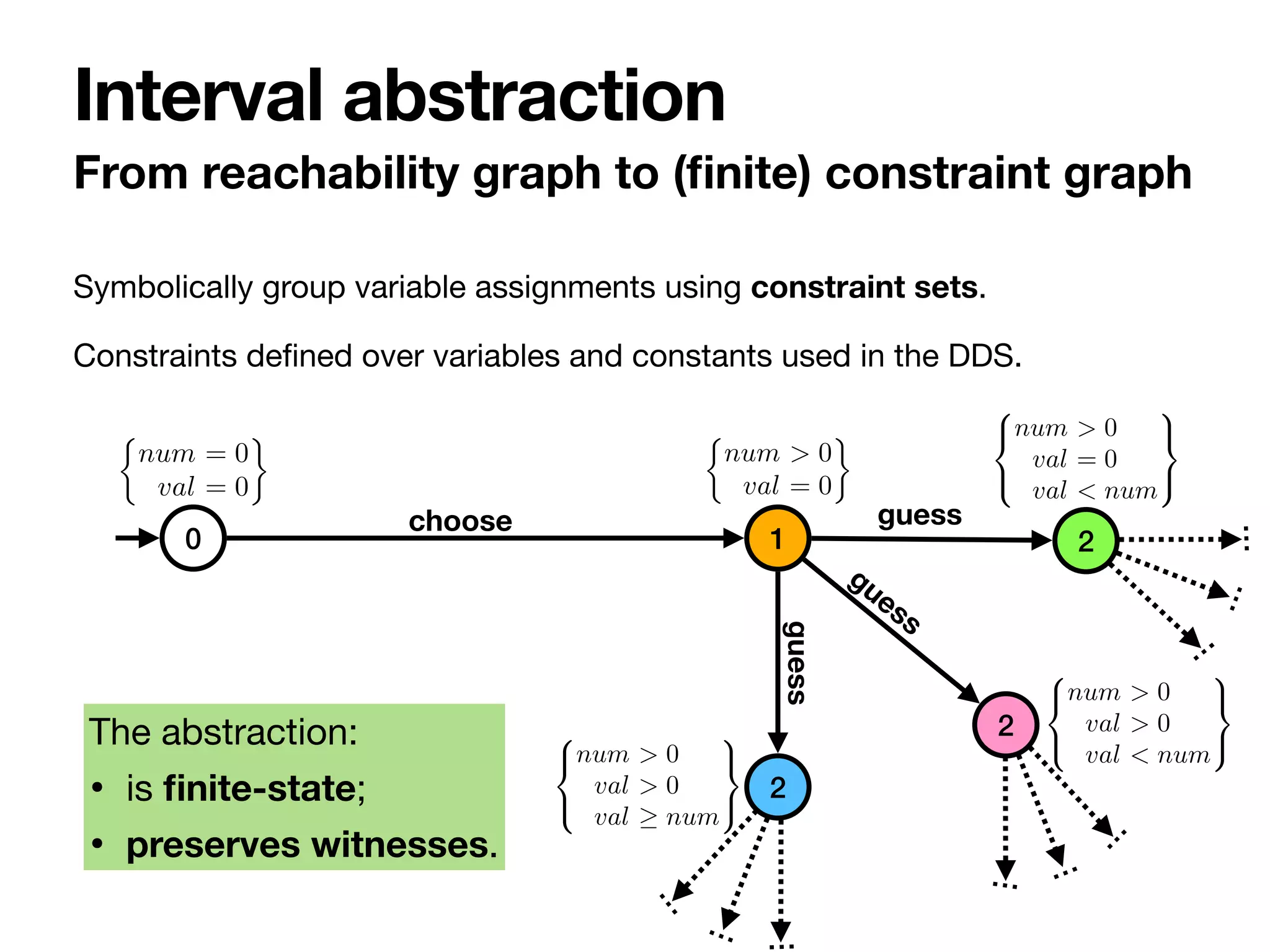
Reachability graph (in
fi
nite in two dimensions)
Execution semantics
0 1 2
choose guess
[ numw > 0 ] [ valw ≥ valr ]
choose
choose
choose
guess
guess
guess
⇢
num = 0
val = 0
⇢
num = 0.5
val = 0
⇢
num = 1
val = 0
⇢
num = 1
val = 0.75
⇢
num = 1
val = 3.4
⇢
num = 1
val = 0
⇢
num = 5
val = 0
0 1
1
2
2
2
1
…
…
…
…
…
…
…
…
…
…
…
…](https://image.slidesharecdn.com/kr2020-dds-synthesis-final-220819224639-0691cdfb/75/Strategy-Synthesis-for-Data-Aware-Dynamic-Systems-with-Multiple-Actors-16-2048.jpg)
![• Atoms: check control state, check constraints.
• Standard temporal operators: labelled next, eventually, globally.
• Interpreted over
fi
nite traces.
Linear temporal properties over the DDS
fi
nite traces
Specification language
me
st,
ss
of
le
is
ri-
),
a-
d,
by
rd
le
di
by
d,
nt
ment ↵ such that for each (v k) 2 C we have ↵(v) k
and, for each (v1 v2) 2 C, we have ↵(v1) ↵(v2).
4 Specification language
Given a DDS B, let LB be the language with grammar:
= true | C | b | ¬ | 1 ^ 2 | 1 _ 2 | hai | 3 | 2
where a 2 A, C is a constraint set over the variables in B
and b 2 B is a system state of B. We now give the semantics
on finite runs on RGB, for expressing properties on these
runs. For brevity, in what follows it is often convenient to
represent a constraint variable assignment ↵ as a constraint
set. Hence we define C↵
.
=
S
v2V {(v = ↵(v))}.
Intuitively, a formula = C is true when C is satisfiable
together with the current constraint variable assignment ↵
in the run of RGB, i.e., constraint variable assignment is a
solution of C (C [ C↵ is satisfiable). Similarly, an atomic
formula b requires the current system state to be b. hai
requires that is true in the run after executing action a (in
the next configuration, which must exist). 2 and 3 are read
as ‘for each step in the run’ and ‘eventually in the run’.
0 1 2
1
4
3
choose
repeat
guess
wait cheat
win
[ numw > 0 ] [ valw ≥ valr ]
[ valr ≥ numr ]
[ numw ≥ valr ]
b c
= val)}
= val)}
m = val)}
m 6= val)}
m = val)}
m 6= val)}
· · ·
{(num 3), win, (num = val)}
{(num < 3), win, (num = val)}
· · · a a0
⇢
num = 0
val = 0
b1
8
<
:
num > 0
val = 0
val < num
9
=
;
⇢
num < 3
num 6= val
a1
8
<
:
num > 0
val = 0
val < num
9
=
;
⇢
num 3
num 6= val
b2
8
<
:
num > 0
val = 0
val < num
9
=
;
⇢
num < 3
num 6= val b2
8
<
:v
⇢
n
b2
8
<
:
num > 0
val > 0
val num
9
=
;
⇢
num < 3
num 6= val
· · ·
wait, cheat
· · ·
wa
wait,
· · ·
guess
init choose guess
r = 3((num < 3) ^ hwini(val = num)), requiring the chosen real to b](https://image.slidesharecdn.com/kr2020-dds-synthesis-final-220819224639-0691cdfb/75/Strategy-Synthesis-for-Data-Aware-Dynamic-Systems-with-Multiple-Actors-17-2048.jpg)

![Veri
fi
cation
Example
{(num 3), ¬win, (num = val)}
{(num 3), ¬win, (num 6= val)}
· · · · · · a a0
⇢
n
a1
8
<
:
num > 0
val = 0
val < num
9
=
;
⇢
num 3
num 6= val 8
<
:
num > 0
val > 0
val num
9
=
;
· · ·
guess
init choose
e 4: Left: D for = 3((num < 3) ^ hwini(val = num)), requiring the
uess to be exact. Dots are used for labels not already labelling other outg
ols labelling arcs) showing a winning run. States are associated to two con
DB and the constraint set A. State labels refer to the states of D and DB.
ugh only three are in CGB (see Figure 2): two outcomes disambiguate b
ded to the set of assumptions A. A winning strategy exists if at least num
oller game moves guaranteeing to satisfy is {}, {pick(num, {num > 0, n
roller (with X Y = ;). The objective is to control, at
step, the values of variables in Y in such a way that for
ossible values of those in X a certain formula is true.
set o
then
ing g
0 1 2
1
4
3
choose
repeat
guess
wait cheat
win
[ numw > 0 ] [ valw ≥ valr ]
[ valr ≥ numr ]
[ numw ≥ valr ]](https://image.slidesharecdn.com/kr2020-dds-synthesis-final-220819224639-0691cdfb/75/Strategy-Synthesis-for-Data-Aware-Dynamic-Systems-with-Multiple-Actors-19-2048.jpg)
![Strategy synthesis
Example
0 1 2
1
4
3
choose
repeat
guess
wait cheat
win
num val
[ numw > 0 ] [ valw ≥ valr ]
[ valr ≥ numr ]
[ numw ≥ valr ]
b c
= val)}
6= val)}
m = val)}
m 6= val)}
m = val)}
m 6= val)}
· · ·
{(num 3), win, (num = val)}
{(num < 3), win, (num = val)}
· · · a a0
⇢
num = 0
val = 0
b1
8
<
:
num > 0
val = 0
val < num
9
=
;
⇢
num < 3
num 6= val
a1
8
<
:
num > 0
val = 0
val < num
9
=
;
⇢
num 3
num 6= val
b2
8
<
:
num > 0
val = 0
val < num
9
=
;
⇢
num < 3
num 6= val b
8
<
:
⇢
b2
8
<
:
num > 0
val > 0
val num
9
=
;
⇢
num < 3
num 6= val
· · ·
wait, cheat
· · ·
w
wait
· · ·
guess
init choose guess
or = 3((num < 3) ^ hwini(val = num)), requiring the chosen real to b
c
3), win, (num = val)}
< 3), win, (num = val)}
· · · a a0
⇢
num = 0
val = 0
b1
8
<
:
num > 0
val = 0
val < num
9
=
;
⇢
num < 3
num 6= val
a1
8
<
:
num > 0
val = 0
val < num
9
=
;
⇢
num 3
num 6= val
b2
8
<
:
num > 0
val = 0
val < num
9
=
;
⇢
num < 3
num 6= val b2
8
<
:
num > 0
val > 0
val < num
9
=
;
⇢
n
b2
8
<
:
num > 0
val > 0
val num
9
=
;
⇢
num < 3
num = val
b2
8
<
:
num > 0
val > 0
val num
9
=
;
⇢
num < 3
num 6= val
8
<
:v
· · ·
wait, cheat
· · ·
wait, cheat
· · ·
wait, cheat
· · ·
guess
init choose guess
c
c
w
m < 3) ^ hwini(val = num)), requiring the chosen real to be smaller than](https://image.slidesharecdn.com/kr2020-dds-synthesis-final-220819224639-0691cdfb/75/Strategy-Synthesis-for-Data-Aware-Dynamic-Systems-with-Multiple-Actors-20-2048.jpg)
![Veri
fi
cation reduces to strategy synthesis
with a single agent controlling everything.
To solve strategy synthesis we take
inspiration from classical approaches [Pnueli
and Rosner 1998]. However:
• The reachability graph is in
fi
nite.
• We have to handle constraints: “data-
aware” alphabet.
Observations
Reasoning tasks](https://image.slidesharecdn.com/kr2020-dds-synthesis-final-220819224639-0691cdfb/75/Strategy-Synthesis-for-Data-Aware-Dynamic-Systems-with-Multiple-Actors-21-2048.jpg)
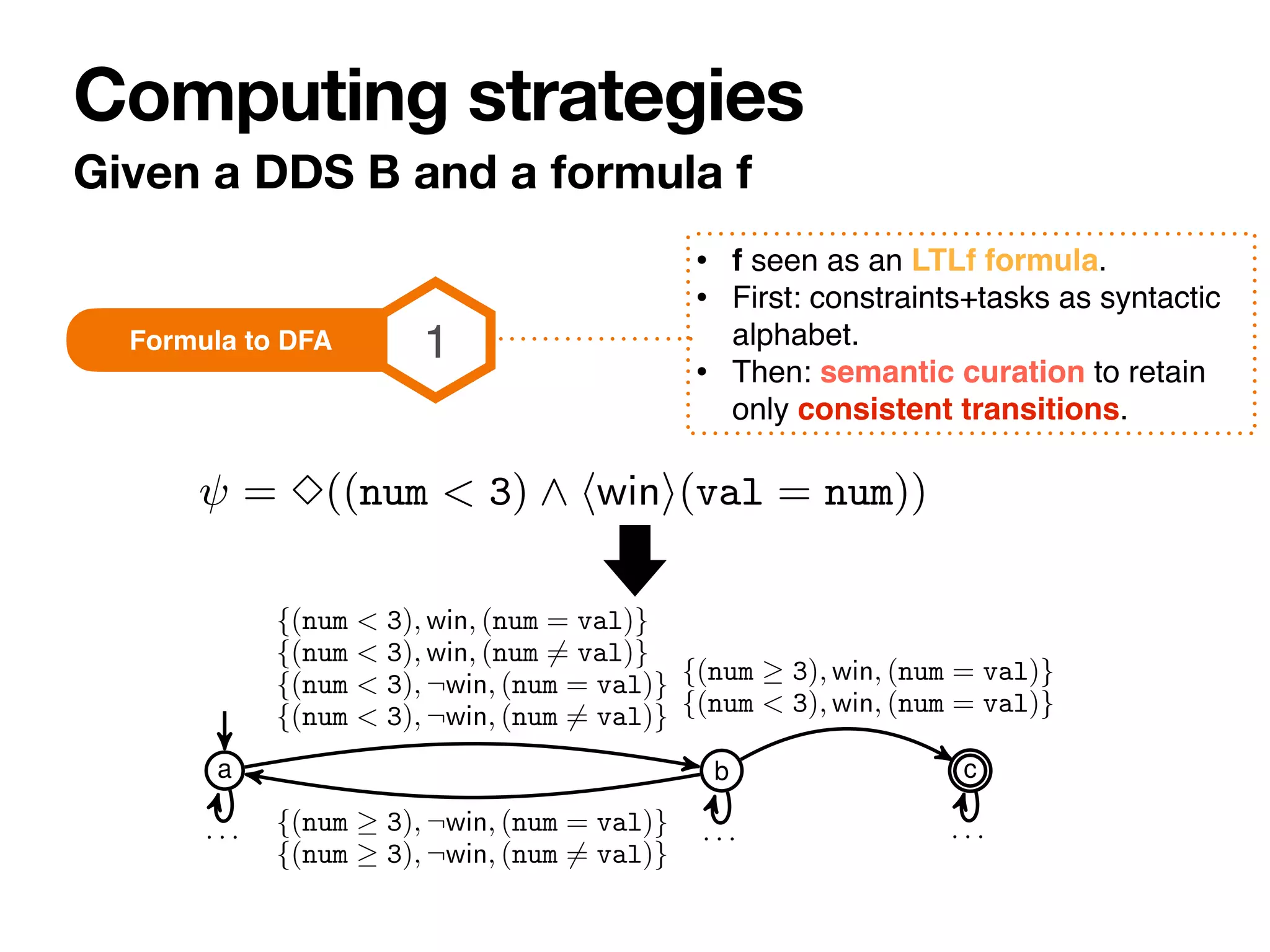
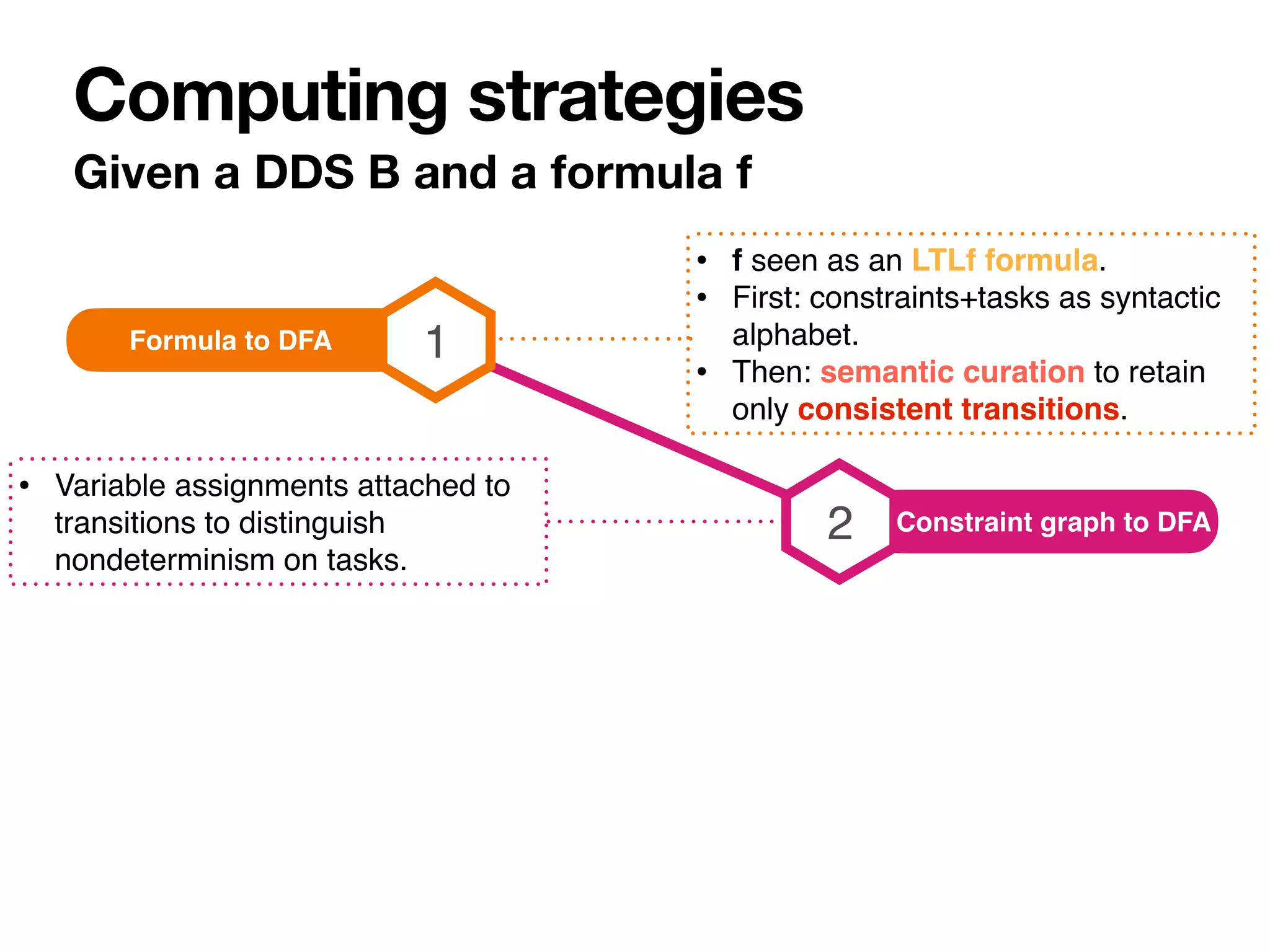
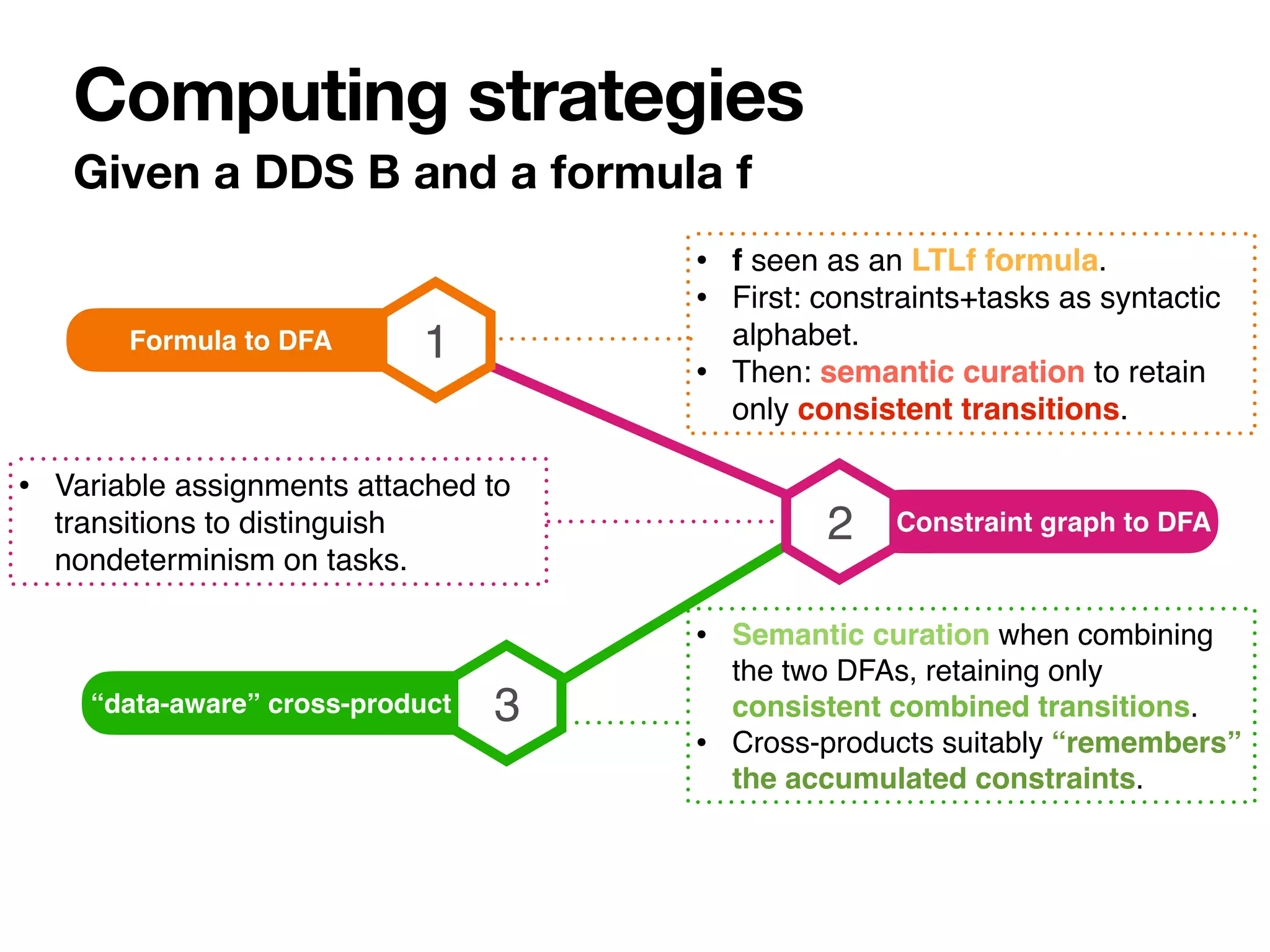
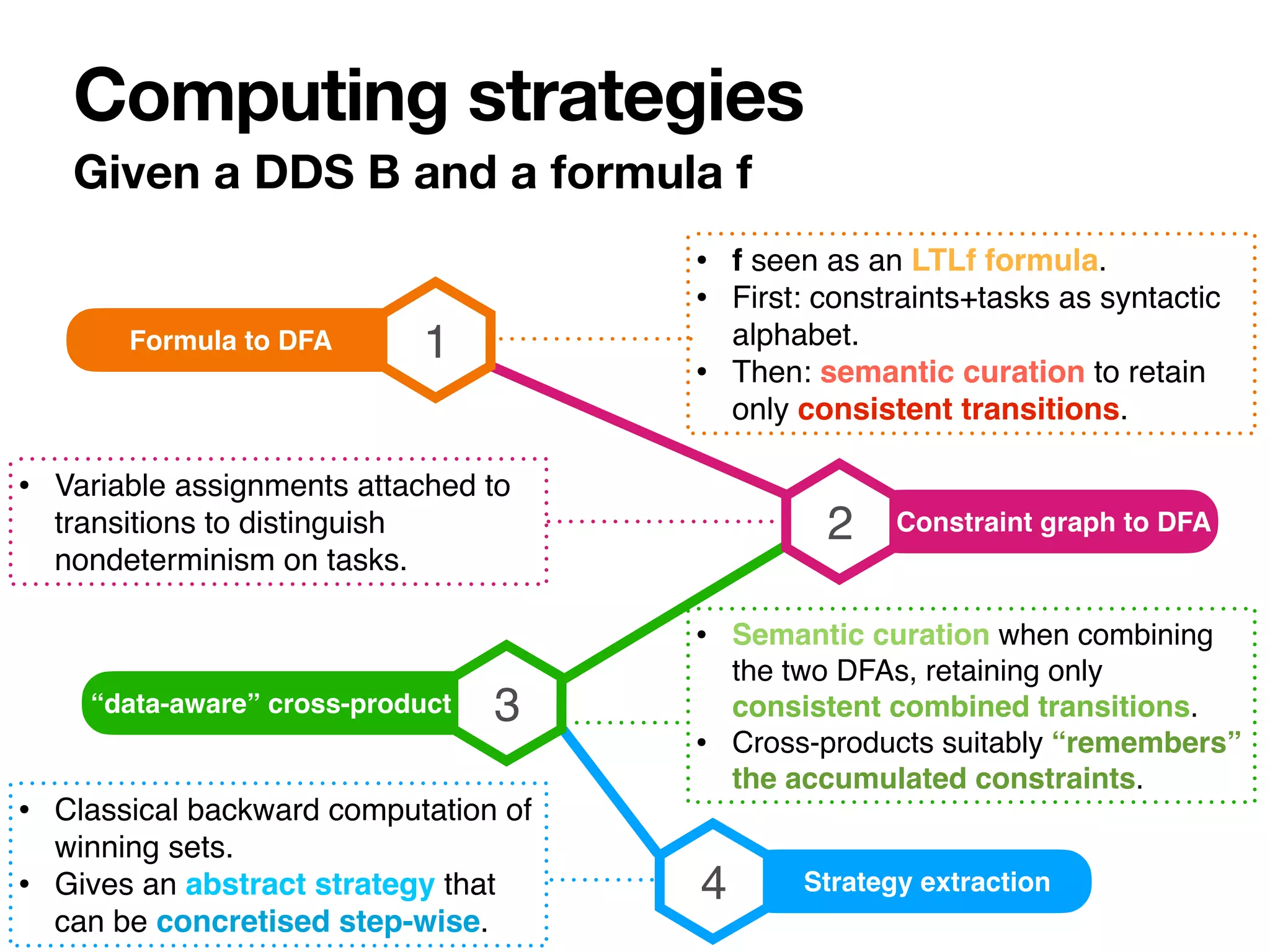
![Lower bound
2-EXPTIME from classical propositional setting.
Upper bound
Doubly-exponential in the formula.
Exponential in the compact DDS. Speci
fi
cally:
#variables, #used constants, #constraint
[Constructions need to call constraint solver]
Complexity](https://image.slidesharecdn.com/kr2020-dds-synthesis-final-220819224639-0691cdfb/75/Strategy-Synthesis-for-Data-Aware-Dynamic-Systems-with-Multiple-Actors-29-2048.jpg)

The document discusses strategy synthesis for data-aware dynamic systems involving multiple actors, focusing on the data-process divide and how agents impact decision-making in various scenarios. It presents models such as data-aware Petri nets and methodologies for task verification and strategy generation in finite state systems. The significance of constraints and their role in strategy synthesis is emphasized, highlighting the need to manage an infinite reachability graph effectively.



































































