
Download as PDF, PPTX



























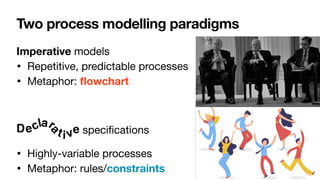








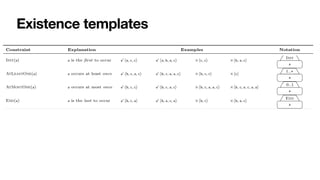
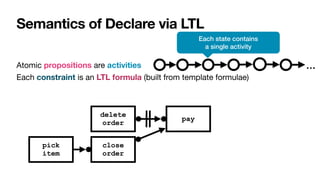
![Constraint-based specifications of behaviour
• Multiagent systems: declarative agent programs [Fisher,JSC1996]
and interaction protocols [Singh,AAMAS2003]
• Data management: cascaded transactional updates
[DavulcuEtAl,PODS1998]
• BPM (1st wave): loosely-coupled subprocesses [SadiqEtAl,ER2001]
• BPM (2nd wave): process constraints
• DECLARE [PesicEtAl,EDOC2007]
• Dynamic Condition-Response (DCR) Graphs
[HildebrandtEtAl,PLACES2010]](https://image.slidesharecdn.com/kes2022-intelligent-process-mining-220909171935-adcdf187/85/Intelligent-Systems-for-Process-Mining-76-320.jpg)




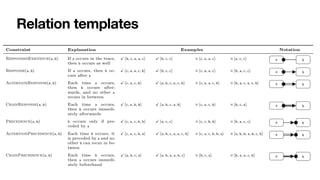


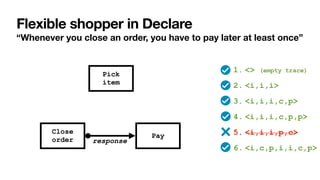
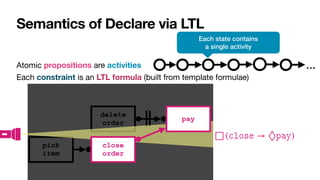
![Interaction among constraints
Aka hidden dependencies [____,TWEB2010]
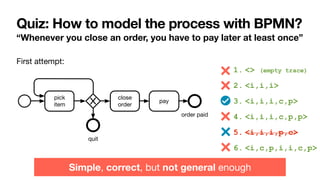
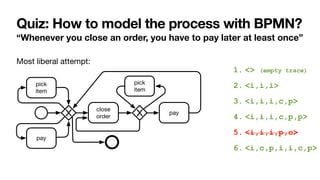
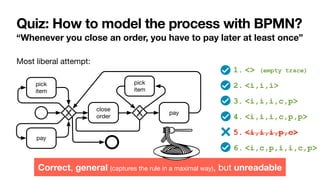
Cancel
order
Close
order
Pay
If you cancel the order,
you cannot pay for it
If you close the order,
you must pay for it
Pick
item
To close an order, you
must
fi
rst pick an item](https://image.slidesharecdn.com/kes2022-intelligent-process-mining-220909171935-adcdf187/85/Intelligent-Systems-for-Process-Mining-88-320.jpg)
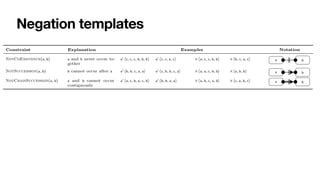
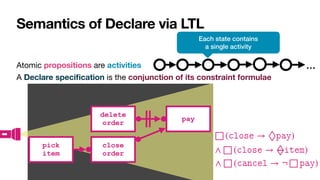
![Interaction among constraints
Aka hidden dependencies [____,TWEB2010]
Cancel
order
Close
order
Pay
If you cancel the order,
you cannot pay for it
If you close the order,
you must pay for it
Pick
item
To close an order, you
must
fi
rst pick an item
Implied: cannot
cancel and
con
fi
rm!](https://image.slidesharecdn.com/kes2022-intelligent-process-mining-220909171935-adcdf187/85/Intelligent-Systems-for-Process-Mining-89-320.jpg)
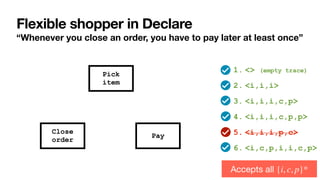
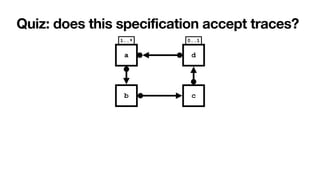
![Interaction among constraints
Aka hidden dependencies [____,TWEB2010]
Cancel
order
Close
order
Pay
If you cancel the order,
you cannot pay for it
If you close the order,
you must pay for it
Pick
item
To close an order, you
must
fi
rst pick an item
Implied: cannot
cancel and
con
fi
rm!
Key questions
1. How to
characterise the
language of a
Declare
speci
fi
cation?
2. How to
understand
whether a
speci
fi
cation is
correct?](https://image.slidesharecdn.com/kes2022-intelligent-process-mining-220909171935-adcdf187/85/Intelligent-Systems-for-Process-Mining-90-320.jpg)


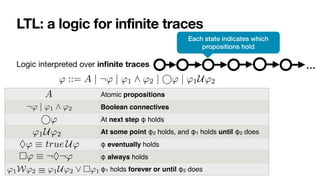
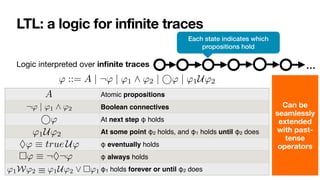
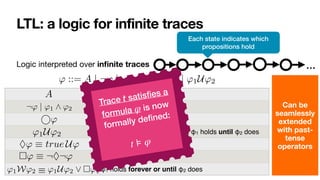




![LTLf: LTL over finite traces
[DeGiacomoVardi,IJCAI2013]
LTL interpreted over
fi
nite traces
' ::= A | ¬' | '1 ^ '2 | ' | '1U'2
No successor!
Same syntax of LTL
In LTL, there is always a next moment… in LTLf, the contrary!
φ always holds from current to the last instant
The next step exists and at next step φ holds
(weak next) If the next step exists, then at next step φ holds
last instant in the trace
' | '1 ^ '2 | ' | '1U'2
⇤'
Last ⌘ ¬ true
' ⌘ ¬ ¬'](https://image.slidesharecdn.com/kes2022-intelligent-process-mining-220909171935-adcdf187/85/Intelligent-Systems-for-Process-Mining-103-320.jpg)
![Look the same, but they are not the same
Many researchers: misled by moving from in
fi
nite to
fi
nite traces
In [____,AAAI14], we studied why!
• People typically focus on “patterns”, not on the entire logic
• Many of such patterns in BPM, reasoning about actions, planning, etc. are
“insensitive to in
fi
nity”](https://image.slidesharecdn.com/kes2022-intelligent-process-mining-220909171935-adcdf187/85/Intelligent-Systems-for-Process-Mining-104-320.jpg)

![From Declare to automata
LTLf NFA
nondeterministic
DFA
deterministic
LTLf2aut determin.
'
nt
lf formulas can be translated into equivalent nfa:
t |= Ï iff t œ L(AÏ)
/ldlf to nfa (exponential)
to dfa (exponential)
often nfa/dfa corresponding to ltlf /ldlf are in fact small!
ompile reasoning into automata based procedures!
Process engine!
[DeGiacomoVardi,IJCAI2013]
[____,TOSEM2022]](https://image.slidesharecdn.com/kes2022-intelligent-process-mining-220909171935-adcdf187/85/Intelligent-Systems-for-Process-Mining-114-320.jpg)
![Vision realised!
LTLf NFA
nondeterministic
DFA
deterministic
LTLf2aut determin.
'
nt
lf formulas can be translated into equivalent nfa:
t |= Ï iff t œ L(AÏ)
/ldlf to nfa (exponential)
to dfa (exponential)
often nfa/dfa corresponding to ltlf /ldlf are in fact small!
ompile reasoning into automata based procedures!
Process engine!
[DeGiacomoVardi,IJCAI2013]
[____,TOSEM2022]](https://image.slidesharecdn.com/kes2022-intelligent-process-mining-220909171935-adcdf187/85/Intelligent-Systems-for-Process-Mining-115-320.jpg)
![Few lines of code
[____,TOSEM2022] 0:8 G. De Giacomo et al.
(tt, ⇧) = true
(↵ , ⇧) = false
( , ⇧) = (h itt, ⇧) ( prop.)
('1 ^ '2, ⇧) = ('1, ⇧) ^ ('2, ⇧)
('1 _ '2, ⇧) = ('1, ⇧) _ ('2, ⇧)
(h i', ⇧) =
⇢
E (') if ⇧ |= ( prop.)
false if ⇧ 6|=
(h ?i', ⇧) = ( , ⇧) ^ (', ⇧)
(h⇢1 + ⇢2i', ⇧) = (h⇢1i', ⇧) _ (h⇢2i', ⇧)
(h⇢1; ⇢2i', ⇧) = (h⇢1ih⇢2i', ⇧)
(h⇢⇤
i', ⇧) = (', ⇧) _ (h⇢iF h⇢⇤i', ⇧)
([ ]', ⇧) =
⇢
E (') if ⇧ |= ( prop.)
true if ⇧ 6|=
([ ?]', ⇧) = (nnf (¬ ), ⇧) _ (', ⇧)
([⇢1 + ⇢2]', ⇧) = ([⇢1]', ⇧) ^ ([⇢2]', ⇧)
([⇢1; ⇢2]', ⇧) = ([⇢1][⇢2]', ⇧)
([⇢⇤
]', ⇧) = (', ⇧) ^ ([⇢]T [⇢⇤]', ⇧)
(F , ⇧) = false
(T , ⇧) = true
Fig. 1: Definition of , where E (') recursively replaces in ' all occurrences of atoms of
the form T and F by .
1: algorithm LDLf 2NFA
2: input LDLf formula '
3: output NFA A(') = (2P
, S, s0, %, Sf )
4: s0 {'} . set the initial state
5: Sf {;} . set final states
6: if ( (', ✏) = true) then . check if initial state is also final
7: Sf Sf [ {s0}
8: S {s0, ;}, % ;
9: while (S or % change) do
10: for (s 2 S) do
11: if (s0
|=
V
( 2s) ( , ⇧) then . add new state and transition
12: S S [ {s0
}
13: % % [ {(s, ⇧, s0
)}
14: if (
V
( 2s0) ( , ✏) = true) then . check if new state is also final
15: Sf Sf [ {s0
}
Fig. 2: NFA construction.
' NFA](https://image.slidesharecdn.com/kes2022-intelligent-process-mining-220909171935-adcdf187/85/Intelligent-Systems-for-Process-Mining-118-320.jpg)
![Few lines of code
[____,TOSEM2022] 0:8 G. De Giacomo et al.
(tt, ⇧) = true
(↵ , ⇧) = false
( , ⇧) = (h itt, ⇧) ( prop.)
('1 ^ '2, ⇧) = ('1, ⇧) ^ ('2, ⇧)
('1 _ '2, ⇧) = ('1, ⇧) _ ('2, ⇧)
(h i', ⇧) =
⇢
E (') if ⇧ |= ( prop.)
false if ⇧ 6|=
(h ?i', ⇧) = ( , ⇧) ^ (', ⇧)
(h⇢1 + ⇢2i', ⇧) = (h⇢1i', ⇧) _ (h⇢2i', ⇧)
(h⇢1; ⇢2i', ⇧) = (h⇢1ih⇢2i', ⇧)
(h⇢⇤
i', ⇧) = (', ⇧) _ (h⇢iF h⇢⇤i', ⇧)
([ ]', ⇧) =
⇢
E (') if ⇧ |= ( prop.)
true if ⇧ 6|=
([ ?]', ⇧) = (nnf (¬ ), ⇧) _ (', ⇧)
([⇢1 + ⇢2]', ⇧) = ([⇢1]', ⇧) ^ ([⇢2]', ⇧)
([⇢1; ⇢2]', ⇧) = ([⇢1][⇢2]', ⇧)
([⇢⇤
]', ⇧) = (', ⇧) ^ ([⇢]T [⇢⇤]', ⇧)
(F , ⇧) = false
(T , ⇧) = true
Fig. 1: Definition of , where E (') recursively replaces in ' all occurrences of atoms of
the form T and F by .
1: algorithm LDLf 2NFA
2: input LDLf formula '
3: output NFA A(') = (2P
, S, s0, %, Sf )
4: s0 {'} . set the initial state
5: Sf {;} . set final states
6: if ( (', ✏) = true) then . check if initial state is also final
7: Sf Sf [ {s0}
8: S {s0, ;}, % ;
9: while (S or % change) do
10: for (s 2 S) do
11: if (s0
|=
V
( 2s) ( , ⇧) then . add new state and transition
12: S S [ {s0
}
13: % % [ {(s, ⇧, s0
)}
14: if (
V
( 2s0) ( , ✏) = true) then . check if new state is also final
15: Sf Sf [ {s0
}
Fig. 2: NFA construction.
' NFA
Automata manipulations
much easier to handle
than in the in
fi
nite case,
with huge performance
improvements
[ZhuEtAl,
IJ
CAI17]
[Westergaard,BPM11]](https://image.slidesharecdn.com/kes2022-intelligent-process-mining-220909171935-adcdf187/85/Intelligent-Systems-for-Process-Mining-119-320.jpg)

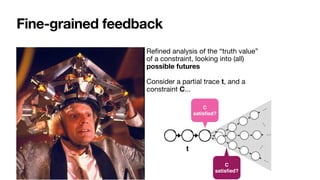
![RV-LTL truth values
[BauerEtAl,InfCom2010]
C is permanently satis
fi
ed if t
satis
fi
es C and no matter how t is
extended, C will stay satis
fi
ed
C is currently satis
fi
ed if t satis
fi
es C
but there is a continuation of t that
violates C
…
…
t
…
…
…
t](https://image.slidesharecdn.com/kes2022-intelligent-process-mining-220909171935-adcdf187/85/Intelligent-Systems-for-Process-Mining-130-320.jpg)
![RV-LTL truth values
C is currently violated if t violates C
but there is a continuation that leads
to satisfy C
C is permanently violated if t violates
C and no matter how t is extended, C
will stay violated
t
…
…
…
…
…
[BauerEtAl,InfCom2010]](https://image.slidesharecdn.com/kes2022-intelligent-process-mining-220909171935-adcdf187/85/Intelligent-Systems-for-Process-Mining-131-320.jpg)
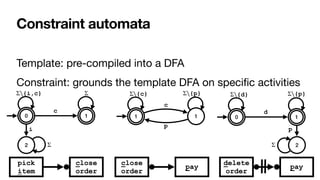
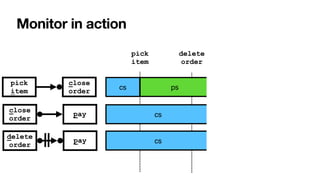
![RV-LTL on finite traces
[____,BPM2011] [____,BPM2014] [____,TOSEM2022]
close
order
delete
order
pay
pick
item
close
order
pay
0 1
2
i
Σ
{i,c}
Σ∖ Σ
c
1
1
{c}
Σ∖
c
{p}
Σ∖
p
0 1
2
p
Σ
{d}
Σ∖
d
{p}
Σ∖
Su
ffi
xes of the current trace: each with unbounded,
fi
nite length
• Again standard DFAs -> all formulae of LTLf are monitorable
Each state of the DFA: colored with an RV-LTL value via simple reachability checks](https://image.slidesharecdn.com/kes2022-intelligent-process-mining-220909171935-adcdf187/85/Intelligent-Systems-for-Process-Mining-132-320.jpg)
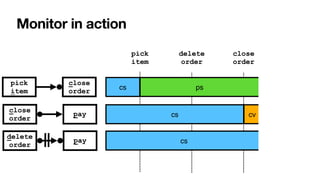
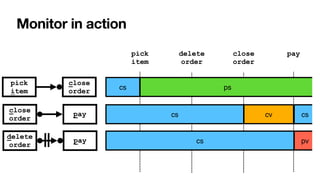
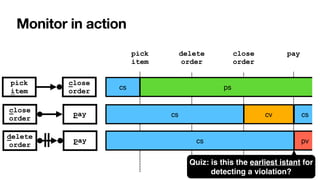
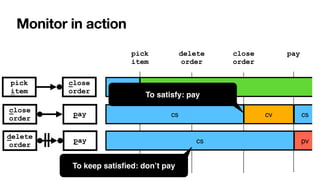
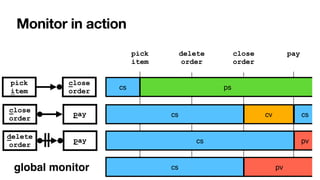
![RV-LTL on finite traces
[____,BPM2011] [____,BPM2014] [____,TOSEM2022]
Su
ffi
xes of the current trace: each with unbounded,
fi
nite length
• Again standard DFAs -> all formulae of LTLf are monitorable
Each state of the DFA: colored with an RV-LTL value via simple reachability checks
Σ
Σ
Σ
0
[cs]
1
[ps]
2
[pv]
1
[cv]
0
[cs]
0
[cs]
1
[cs]
2
[pv]
c
{i,c}
Σ∖
i
{c}
Σ∖
c
{p}
Σ∖
p
p
{d}
Σ∖
d
{p}
Σ∖
close
order
delete
order
pay
pick
item
close
order
pay](https://image.slidesharecdn.com/kes2022-intelligent-process-mining-220909171935-adcdf187/85/Intelligent-Systems-for-Process-Mining-133-320.jpg)
![002
[cs,cs,pv]
111
[ps,cv,cs]
112
[ps,cv,pv]
200
[pv,cs,cs]
102
[pv,cs,cs]
211
[pv,cv,cs]
202
[pv,cs,pv]
{i,c,d}
Σ∖
{i,c,p}
Σ∖
{i,c}
Σ∖
{c,d}
Σ∖
{c,p}
Σ∖
{d,p}
Σ∖
{p}
Σ∖
100
[ps,cs,cs]
101
[ps,cs,cs]
000
[cs,cs,cs]
001
[cs,cs,cs]
{c}
Σ∖
{c,d}
Σ∖
d
c c
i
p
c
i d
110
[ps,cv,cs]
c
p p
d
p
210
[pv,cv,cs]
c
{p,d}
Σ∖
p
d
{p}
Σ∖ p
{c}
Σ∖
i
c
p
{p}
Σ∖
c
212
[pv,cv,pv]
{p}
Σ∖
p
c
Global monitor](https://image.slidesharecdn.com/kes2022-intelligent-process-mining-220909171935-adcdf187/85/Intelligent-Systems-for-Process-Mining-142-320.jpg)
![002
[cs,cs,pv]
111
[ps,cv,cs]
112
[ps,cv,pv]
200
[pv,cs,cs]
102
[pv,cs,cs]
211
[pv,cv,cs]
202
[pv,cs,pv]
{i,c,d}
Σ∖
{i,c,p}
Σ∖
{i,c}
Σ∖
{c,d}
Σ∖
{c,p}
Σ∖
{d,p}
Σ∖
{p}
Σ∖
100
[ps,cs,cs]
101
[ps,cs,cs]
000
[cs,cs,cs]
001
[cs,cs,cs]
{c}
Σ∖
{c,d}
Σ∖
d
c c
i
p
c
i d
110
[ps,cv,cs]
c
p p
d
p
210
[pv,cv,cs]
c
{p,d}
Σ∖
p
d
{p}
Σ∖ p
{c}
Σ∖
i
c
p
{p}
Σ∖
c
212
[pv,cv,pv]
{p}
Σ∖
p
c
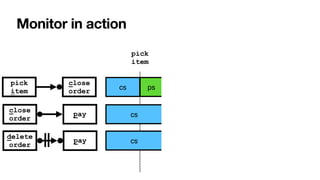
Global monitor Anticipatory
violation detection](https://image.slidesharecdn.com/kes2022-intelligent-process-mining-220909171935-adcdf187/85/Intelligent-Systems-for-Process-Mining-143-320.jpg)
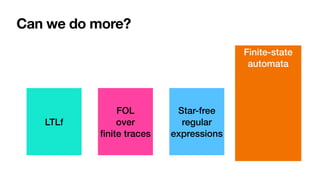

![LDLf
linear dynamic logic
over
fi
nite traces
[DeGiacomoVardi,
IJ
CAI2013]
MSOL over
fi
nite traces
Regular
expressions
Can we do more?
LTLf
FOL
over
fi
nite traces
Star-free
regular
expressions
Finite-state
automata](https://image.slidesharecdn.com/kes2022-intelligent-process-mining-220909171935-adcdf187/85/Intelligent-Systems-for-Process-Mining-146-320.jpg)
![LDLf
linear dynamic logic
over
fi
nite traces
[DeGiacomoVardi,
IJ
CAI2013]
MSOL over
fi
nite traces
Regular
expressions
Can we do more?
[____,BPM2014] [____,TOSEM2022]
LTLf
FOL
over
fi
nite traces
Star-free
regular
expressions
Finite-state
automata](https://image.slidesharecdn.com/kes2022-intelligent-process-mining-220909171935-adcdf187/85/Intelligent-Systems-for-Process-Mining-147-320.jpg)
![LDLf
linear dynamic logic
over
fi
nite traces
[DeGiacomoVardi,
IJ
CAI2013]
MSOL over
fi
nite traces
Regular
expressions
Can we do more?
[____,BPM2014] [____,TOSEM2022]
LTLf
FOL
over
fi
nite traces
Star-free
regular
expressions
Finite-state
automata](https://image.slidesharecdn.com/kes2022-intelligent-process-mining-220909171935-adcdf187/85/Intelligent-Systems-for-Process-Mining-148-320.jpg)
![LDLf
linear dynamic logic
over
fi
nite traces
[DeGiacomoVardi,
IJ
CAI2013]
MSOL over
fi
nite traces
Regular
expressions
Can we do more?
[____,BPM2014] [____,TOSEM2022]
LTLf
FOL
over
fi
nite traces
Star-free
regular
expressions
Finite-state
automata](https://image.slidesharecdn.com/kes2022-intelligent-process-mining-220909171935-adcdf187/85/Intelligent-Systems-for-Process-Mining-149-320.jpg)
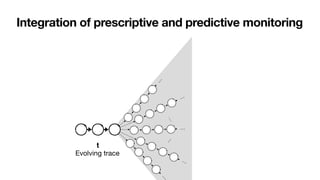
![From constraints to metaconstraints
[____,BPM2014] [____,TOSEM2022]
LDLf expresses RV-LTL monitoring states of LDLf constraints
• Support for metaconstraints predicating over the monitoring status of
other constraints
Example: a form of “contrary-to-duty” process constraint
• If constraint C1 gets permanently violated, eventually satisfy a
compensation constraint C2
Interesting open problem: relationship with normative frameworks and
defeasible reasoning
• [Governatori,EDOC2015] -> LTL cannot express normative notions
• [AlechinaEtAl,FLAP2018]-> not true!](https://image.slidesharecdn.com/kes2022-intelligent-process-mining-220909171935-adcdf187/85/Intelligent-Systems-for-Process-Mining-150-320.jpg)



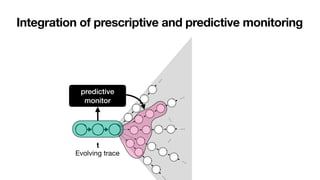
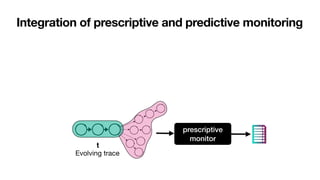




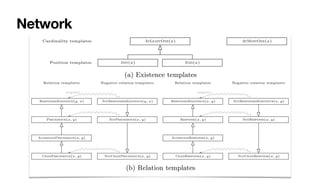
![3D processes require 3D models
Object-centric constraints [____,DL17] [____,BPM19]
Constraints co-referring via data model: co-evolution of multiple objects
• From propositional to
fi
rst-order temporal logics
• Interesting balance between expressiveness and decidability
• Discoverable from data (ongoing work)
Item
Order Package
create
order
add
item
get
package
0..1 *
* 0..1
includes is in](https://image.slidesharecdn.com/kes2022-intelligent-process-mining-220909171935-adcdf187/85/Intelligent-Systems-for-Process-Mining-165-320.jpg)


















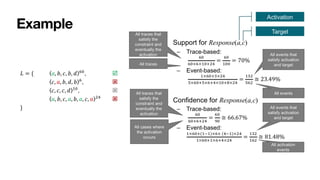




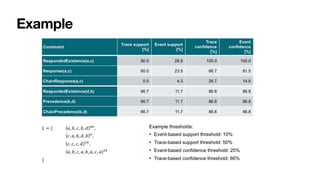
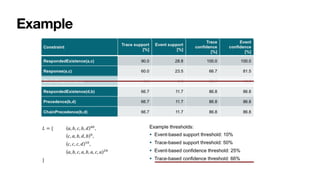
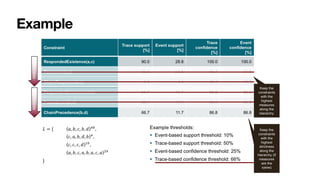
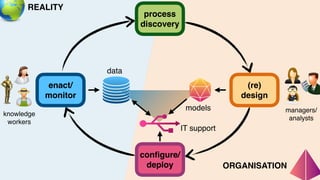
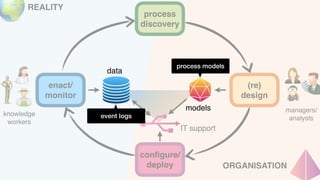
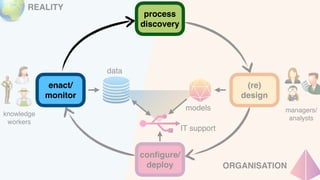
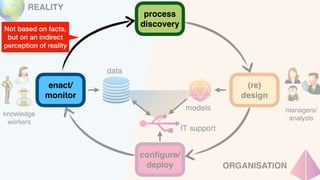
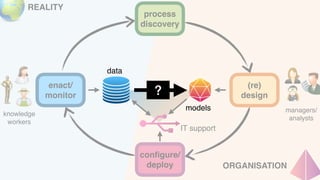
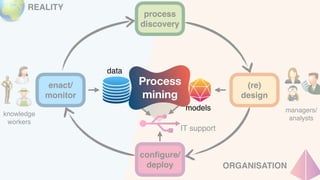
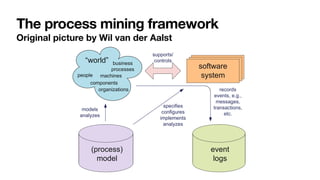
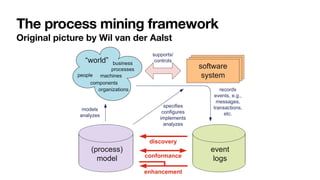
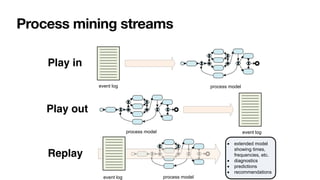
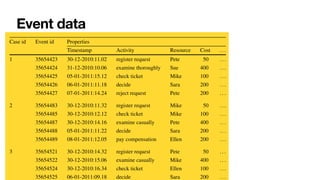
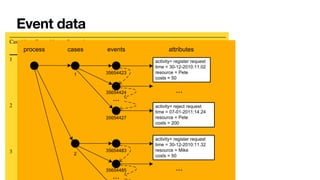
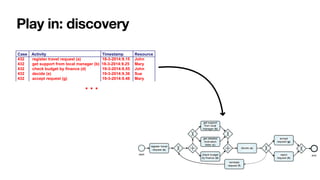
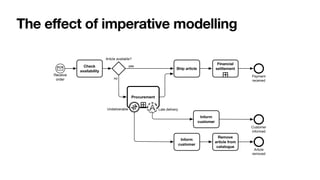
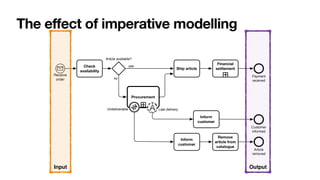
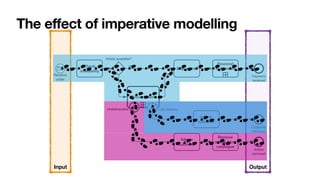
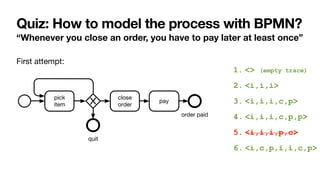
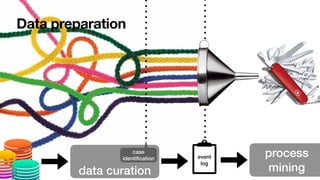
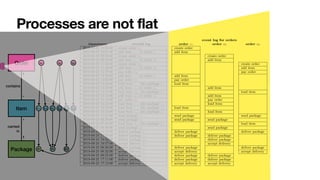
The document discusses advanced techniques in process mining using intelligent systems grounded in artificial intelligence and formal methods. It highlights the importance of data-driven decision-making in business processes and the challenges of connecting management with operational reality. The role of event logs, models, and flexibility in process management are emphasized, along with a growing market for process mining solutions.

























![[IJET-V1I4P3] Authors :Mekhala](https://cdn.slidesharecdn.com/ss_thumbnails/ijet-v1i4p3-150728160211-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)









































