Download as PDF, PPTX
![/191
グラフデータの機械学習における
特徴表現の設計と学習
北海道⼤学・JSTさきがけ
takigawa@ist.hokudai.ac.jp
瀧川 ⼀学
2017.9.8 @⽇本応⽤数理学会 2017年度 年会 [機械学習研究部会 OS]](https://image.slidesharecdn.com/jsiam2017takigawa-170908110155/75/slide-1-2048.jpg)

















![/1914
Circular FingerprintとMorgan Algorithm
00010000101000100000001000010010010100001001000101001000
分⼦グラフ 固定⻑の0-1特徴ベクトル (fingerprint)
2
1
0
3
4
5
6
7
8
9
Layer-0
(diameter 0)
Layer-1
(diameter 2)
Layer-2
(diameter 4)
• Layer-0では、各頂点のnode
invariantsの配列をhashして
得た整数IDをその頂点に付与
• node invariantsにはその頂点の
周辺情報が暗に含まれる
[Morgan Algorithmの変種]
• Layer-1では、各頂点について、
隣り合う頂点の整数IDの配列を
hashして得た新たな整数IDで更新
• Layer-2以降ではLayer-1で更新さ
れた各々の頂点の整数IDを使って
同じように近傍で整数IDを更新
各subgraphの整数IDをmodして得た桁のbitを1に
※ECFP4(diameter 4まで), ECFP6(diameter 6まで)がよく使われる
0 1 2
3 4 5 6
7 8 9
0 1 2
3 4 5 6
7 8 9
3
0
4
7
1
5
8
2
6
9
実際には各subgraphは整数IDで保持](https://image.slidesharecdn.com/jsiam2017takigawa-170908110155/75/slide-25-2048.jpg)








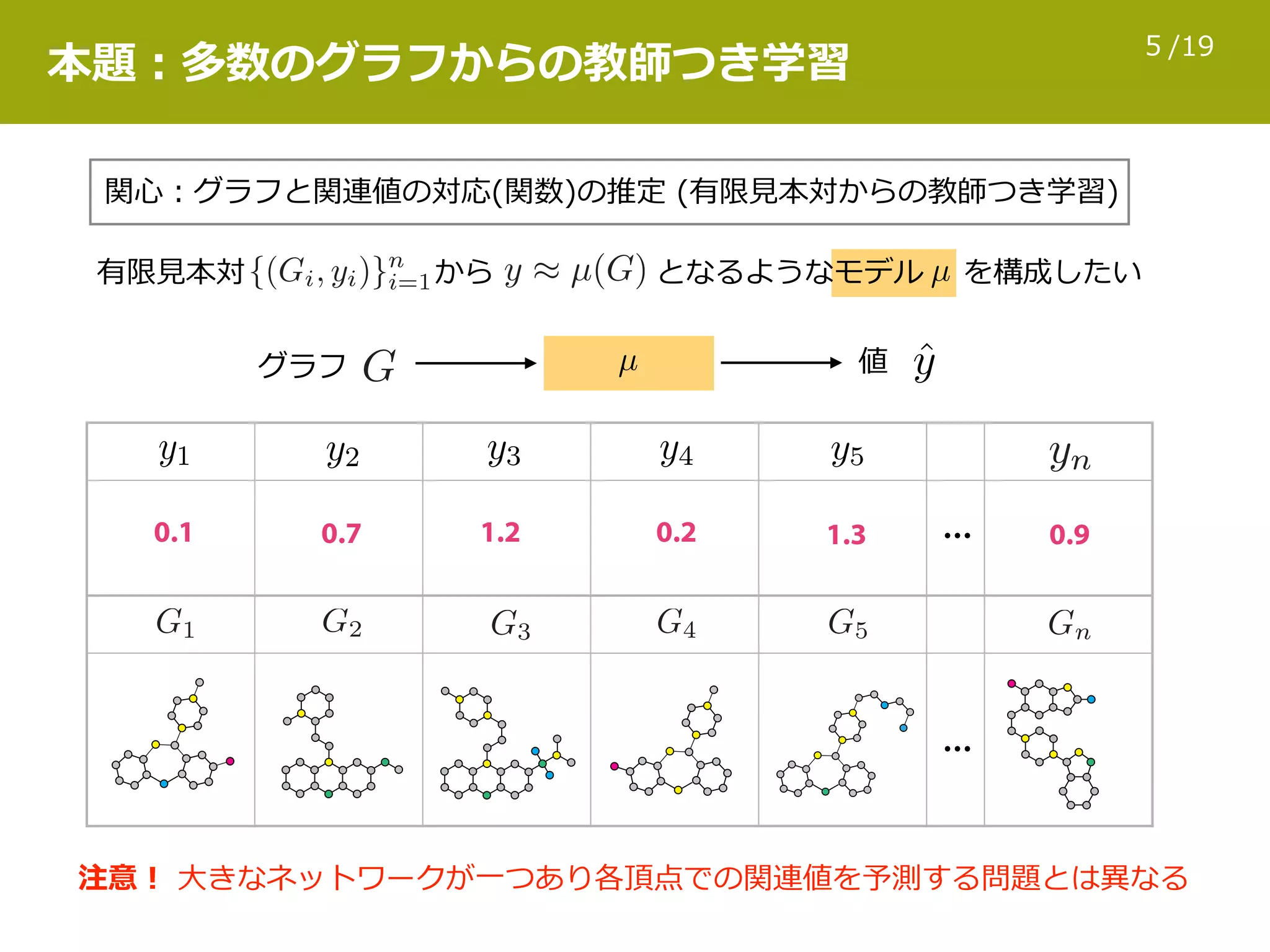
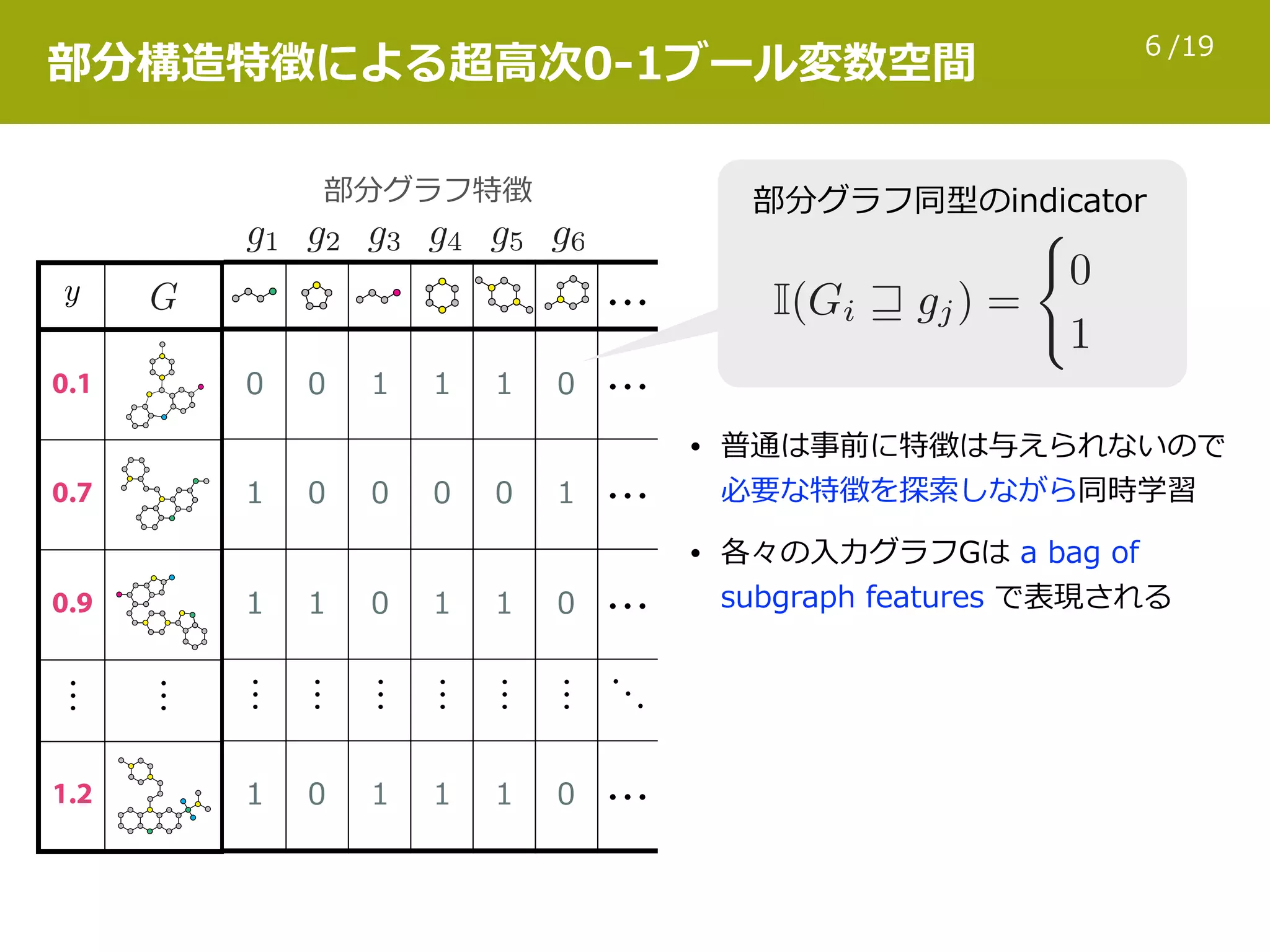
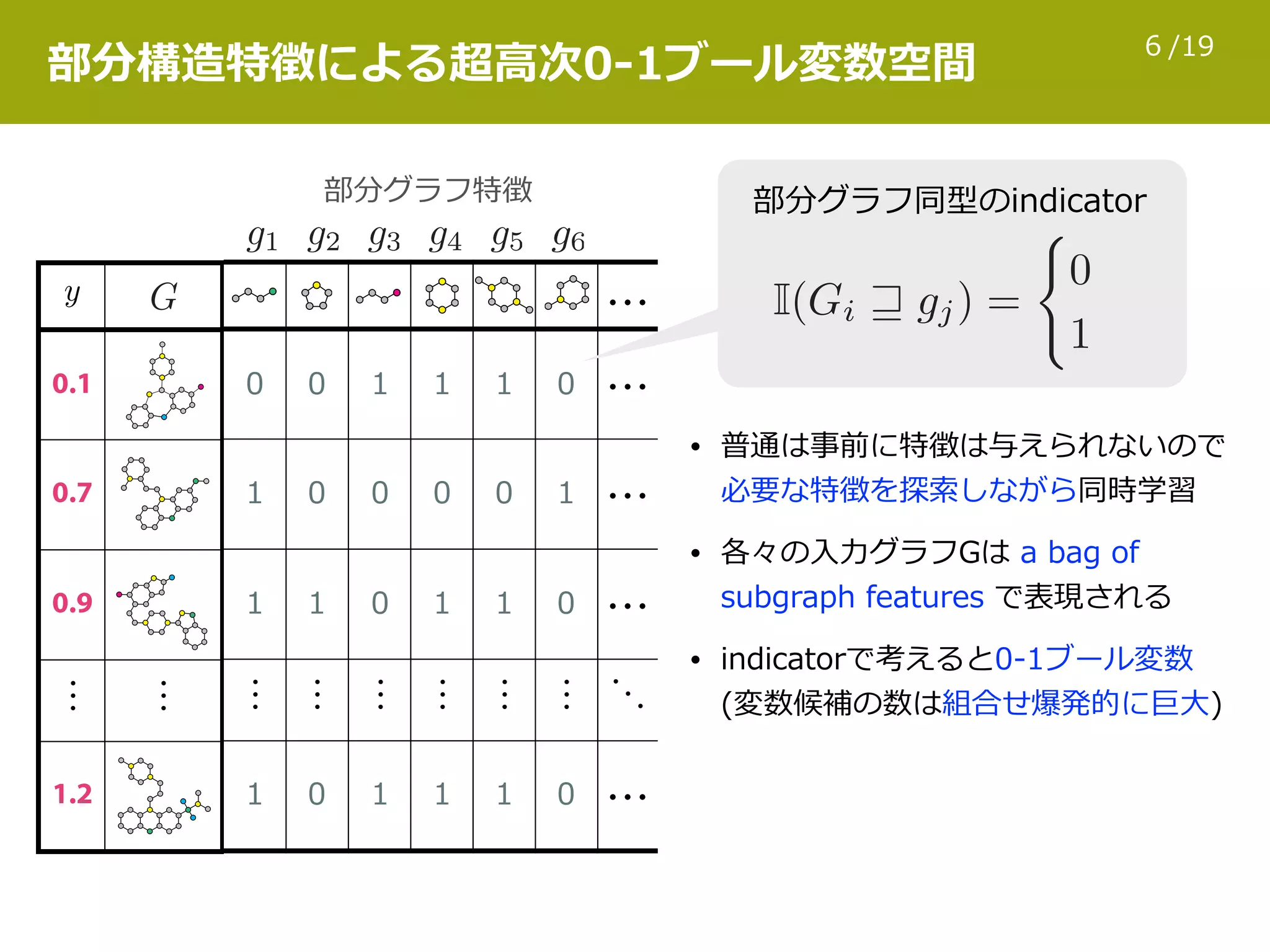
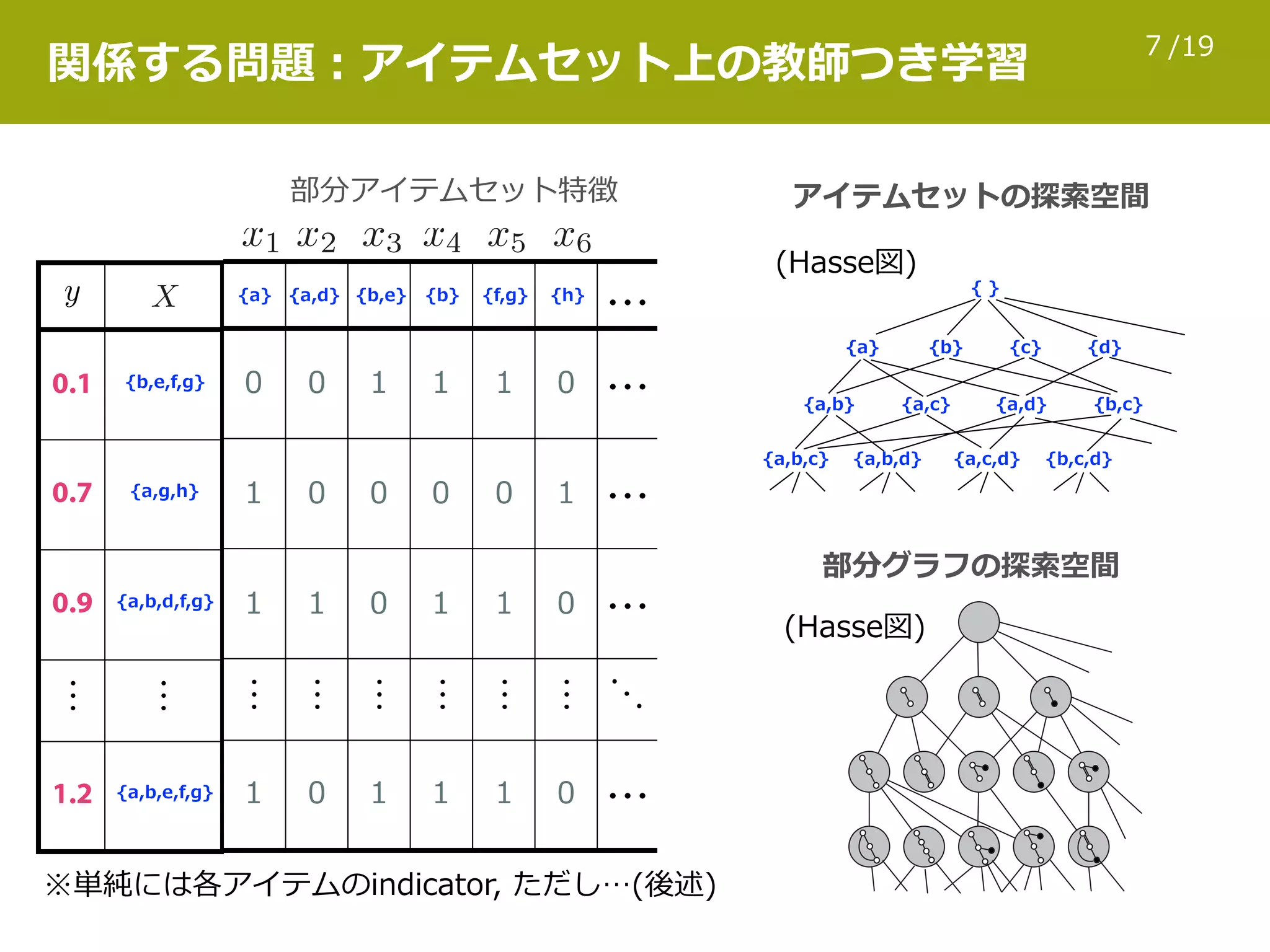
日本応用数理学会 2017年度 年会 2017年9月8日(金) [ [研究部会 OS] 機械学習] http://annual2017.jsiam.org/program#1422 グラフとして表現された対象が多数ある場合、そのデータセットの統計的トレンドを理解するための情報技術が必要となる。この目的のため、様々な教師付き学習方式が現在までに研究されてきた。本発表では、発表者が関わってきた生命科学・材料科学の例について、低分子化合物のグラフエンコードや特徴量計算の手法、スパース学習や回帰森を用いた教師付き学習、及び最近の話題についての概要を紹介する。



















![[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets](https://cdn.slidesharecdn.com/ss_thumbnails/20220325okimura-220405024717-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Neural Ordinary Differential Equations](https://cdn.slidesharecdn.com/ss_thumbnails/nnasode1-190111001755-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DL輪読会]Graph Convolutional Policy Network for Goal-Directed Molecular Graph G...](https://cdn.slidesharecdn.com/ss_thumbnails/graphconvolutionalpolicynetworkforgoal-directedmoleculargraphgeneration-181102004011-thumbnail.jpg?width=640&height=640&fit=bounds)







































