Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Recruit Lifestyle Co., Ltd.
PPTX, PDF
4,304 views
分散トレーシングAWS:X-Rayとの上手い付き合い方
JJUG CCC 2020 Fallにて発表した資料になります。 本セッションでは ・ 分散トレーシングとは ・ X-Rayの仕組みについて ・ 独自に拡張したポイントについて などを説明します。
Engineering
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 71
2
/ 71
3
/ 71
4
/ 71
5
/ 71
6
/ 71
7
/ 71
8
/ 71
9
/ 71
10
/ 71
11
/ 71
12
/ 71
13
/ 71
14
/ 71
15
/ 71
16
/ 71
17
/ 71
18
/ 71
Most read
19
/ 71
20
/ 71
21
/ 71
22
/ 71
23
/ 71
24
/ 71
25
/ 71
26
/ 71
27
/ 71
28
/ 71
29
/ 71
30
/ 71
31
/ 71
32
/ 71
33
/ 71
34
/ 71
35
/ 71
36
/ 71
37
/ 71
38
/ 71
39
/ 71
40
/ 71
41
/ 71
42
/ 71
43
/ 71
44
/ 71
45
/ 71
Most read
46
/ 71
47
/ 71
48
/ 71
49
/ 71
50
/ 71
51
/ 71
52
/ 71
53
/ 71
54
/ 71
55
/ 71
56
/ 71
57
/ 71
58
/ 71
59
/ 71
60
/ 71
61
/ 71
62
/ 71
63
/ 71
64
/ 71
65
/ 71
66
/ 71
67
/ 71
68
/ 71
69
/ 71
70
/ 71
Most read
71
/ 71
More Related Content
PDF
Dockerからcontainerdへの移行
by
Kohei Tokunaga
PDF
ゲームアーキテクチャパターン (Aurora Serverless / DynamoDB)
by
Amazon Web Services Japan
PDF
20210127 今日から始めるイベントドリブンアーキテクチャ AWS Expert Online #13
by
Amazon Web Services Japan
PDF
アーキテクチャから理解するPostgreSQLのレプリケーション
by
Masahiko Sawada
PDF
At least onceってぶっちゃけ問題の先送りだったよね #kafkajp
by
Yahoo!デベロッパーネットワーク
PPTX
MongoDBが遅いときの切り分け方法
by
Tetsutaro Watanabe
PDF
20200826 AWS Black Belt Online Seminar AWS CloudFormation
by
Amazon Web Services Japan
PPTX
KeycloakでAPI認可に入門する
by
Hitachi, Ltd. OSS Solution Center.
Dockerからcontainerdへの移行
by
Kohei Tokunaga
ゲームアーキテクチャパターン (Aurora Serverless / DynamoDB)
by
Amazon Web Services Japan
20210127 今日から始めるイベントドリブンアーキテクチャ AWS Expert Online #13
by
Amazon Web Services Japan
アーキテクチャから理解するPostgreSQLのレプリケーション
by
Masahiko Sawada
At least onceってぶっちゃけ問題の先送りだったよね #kafkajp
by
Yahoo!デベロッパーネットワーク
MongoDBが遅いときの切り分け方法
by
Tetsutaro Watanabe
20200826 AWS Black Belt Online Seminar AWS CloudFormation
by
Amazon Web Services Japan
KeycloakでAPI認可に入門する
by
Hitachi, Ltd. OSS Solution Center.
What's hot
PDF
[AWS EXpert Online for JAWS-UG 18] 見せてやるよ、Step Functions の本気ってやつをな
by
Amazon Web Services Japan
PDF
[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス
by
Amazon Web Services Japan
PDF
Infrastructure as Code (IaC) 談義 2022
by
Amazon Web Services Japan
PDF
AWSとオンプレミスを繋ぐときに知っておきたいルーティングの基礎知識(CCSI監修!)
by
Trainocate Japan, Ltd.
PPTX
分散システムについて語らせてくれ
by
Kumazaki Hiroki
PPTX
AWSで作る分析基盤
by
Yu Otsubo
PDF
20210216 AWS Black Belt Online Seminar AWS Database Migration Service
by
Amazon Web Services Japan
PDF
AWSのログ管理ベストプラクティス
by
Akihiro Kuwano
PDF
Python 3.9からの新定番zoneinfoを使いこなそう
by
Ryuji Tsutsui
PPTX
え、まって。その並列分散処理、Kafkaのしくみでもできるの? Apache Kafkaの機能を利用した大規模ストリームデータの並列分散処理
by
NTT DATA Technology & Innovation
PPTX
Kubernetesでの性能解析 ~なんとなく遅いからの脱却~(Kubernetes Meetup Tokyo #33 発表資料)
by
NTT DATA Technology & Innovation
PDF
SolrとElasticsearchを比べてみよう
by
Shinsuke Sugaya
PDF
乗っ取れコンテナ!!開発者から見たコンテナセキュリティの考え方(CloudNative Days Tokyo 2021 発表資料)
by
NTT DATA Technology & Innovation
PDF
マルチテナント化で知っておきたいデータベースのこと
by
Amazon Web Services Japan
PDF
マスターデータの キャッシュシステムの改善の話
by
natsumi_ishizaka
PDF
20200630 AWS Black Belt Online Seminar Amazon Cognito
by
Amazon Web Services Japan
PDF
DockerとPodmanの比較
by
Akihiro Suda
PDF
マイクロサービス時代の認証と認可 - AWS Dev Day Tokyo 2018 #AWSDevDay
by
都元ダイスケ Miyamoto
PDF
20191023 AWS Black Belt Online Seminar Amazon EMR
by
Amazon Web Services Japan
PPTX
Spring Boot ユーザの方のための Quarkus 入門
by
tsukasamannen
[AWS EXpert Online for JAWS-UG 18] 見せてやるよ、Step Functions の本気ってやつをな
by
Amazon Web Services Japan
[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス
by
Amazon Web Services Japan
Infrastructure as Code (IaC) 談義 2022
by
Amazon Web Services Japan
AWSとオンプレミスを繋ぐときに知っておきたいルーティングの基礎知識(CCSI監修!)
by
Trainocate Japan, Ltd.
分散システムについて語らせてくれ
by
Kumazaki Hiroki
AWSで作る分析基盤
by
Yu Otsubo
20210216 AWS Black Belt Online Seminar AWS Database Migration Service
by
Amazon Web Services Japan
AWSのログ管理ベストプラクティス
by
Akihiro Kuwano
Python 3.9からの新定番zoneinfoを使いこなそう
by
Ryuji Tsutsui
え、まって。その並列分散処理、Kafkaのしくみでもできるの? Apache Kafkaの機能を利用した大規模ストリームデータの並列分散処理
by
NTT DATA Technology & Innovation
Kubernetesでの性能解析 ~なんとなく遅いからの脱却~(Kubernetes Meetup Tokyo #33 発表資料)
by
NTT DATA Technology & Innovation
SolrとElasticsearchを比べてみよう
by
Shinsuke Sugaya
乗っ取れコンテナ!!開発者から見たコンテナセキュリティの考え方(CloudNative Days Tokyo 2021 発表資料)
by
NTT DATA Technology & Innovation
マルチテナント化で知っておきたいデータベースのこと
by
Amazon Web Services Japan
マスターデータの キャッシュシステムの改善の話
by
natsumi_ishizaka
20200630 AWS Black Belt Online Seminar Amazon Cognito
by
Amazon Web Services Japan
DockerとPodmanの比較
by
Akihiro Suda
マイクロサービス時代の認証と認可 - AWS Dev Day Tokyo 2018 #AWSDevDay
by
都元ダイスケ Miyamoto
20191023 AWS Black Belt Online Seminar Amazon EMR
by
Amazon Web Services Japan
Spring Boot ユーザの方のための Quarkus 入門
by
tsukasamannen
More from Recruit Lifestyle Co., Ltd.
PDF
業務と消費者の体験を同時にデザインするリクルートの価値検証のリアル ー 「Airレジ ハンディ」セルフオーダーのブレない「価値」の確かめ方 ー
by
Recruit Lifestyle Co., Ltd.
PDF
OOUIを実践してわかった、9つの大切なこと
by
Recruit Lifestyle Co., Ltd.
PDF
Flutter移行の苦労と、乗り越えた先に得られたもの
by
Recruit Lifestyle Co., Ltd.
PDF
CTIサービスを支える裏側 〜物理デバイスとの戦い〜 | iOSDC Japan 2020
by
Recruit Lifestyle Co., Ltd.
PDF
「進化し続けるインフラ」のためのマルチアカウント管理
by
Recruit Lifestyle Co., Ltd.
PDF
Air事業のデザイン組織とデザイナー
by
Recruit Lifestyle Co., Ltd.
PDF
リクルートライフスタイル AirシリーズでのUXリサーチ
by
Recruit Lifestyle Co., Ltd.
PDF
ホットペッパービューティーにおけるモバイルアプリ向けAPIのBFF/Backend分割
by
Recruit Lifestyle Co., Ltd.
PPTX
データサイエンティストが力を発揮できるアジャイルデータ活用基盤
by
Recruit Lifestyle Co., Ltd.
PDF
Real-time personalized recommendation using embedding
by
Recruit Lifestyle Co., Ltd.
PDF
データから価値を生み続けるには
by
Recruit Lifestyle Co., Ltd.
PDF
データプロダクト開発を成功に導くには
by
Recruit Lifestyle Co., Ltd.
PDF
Jupyter だけで機械学習を実サービス展開できる基盤
by
Recruit Lifestyle Co., Ltd.
PDF
SQLを書くだけでAPIが作れる基盤
by
Recruit Lifestyle Co., Ltd.
PDF
BtoBサービスならではの顧客目線の取り入れ方
by
Recruit Lifestyle Co., Ltd.
PDF
The Design for Serverless ETL Pipeline データ分析基盤のレガシーなデータロードをサーバレスでフルリプレースするまで道のり
by
Recruit Lifestyle Co., Ltd.
PDF
リクルートライフスタイルにおける深層学習の活用とGCPでの実現方法
by
Recruit Lifestyle Co., Ltd.
PDF
ビックデータ分析基盤の成⻑の軌跡
by
Recruit Lifestyle Co., Ltd.
PDF
Refactoring point of Kotlin application
by
Recruit Lifestyle Co., Ltd.
PDF
データサイエンティストとエンジニア 両者が幸せになれる機械学習基盤を求めて
by
Recruit Lifestyle Co., Ltd.
業務と消費者の体験を同時にデザインするリクルートの価値検証のリアル ー 「Airレジ ハンディ」セルフオーダーのブレない「価値」の確かめ方 ー
by
Recruit Lifestyle Co., Ltd.
OOUIを実践してわかった、9つの大切なこと
by
Recruit Lifestyle Co., Ltd.
Flutter移行の苦労と、乗り越えた先に得られたもの
by
Recruit Lifestyle Co., Ltd.
CTIサービスを支える裏側 〜物理デバイスとの戦い〜 | iOSDC Japan 2020
by
Recruit Lifestyle Co., Ltd.
「進化し続けるインフラ」のためのマルチアカウント管理
by
Recruit Lifestyle Co., Ltd.
Air事業のデザイン組織とデザイナー
by
Recruit Lifestyle Co., Ltd.
リクルートライフスタイル AirシリーズでのUXリサーチ
by
Recruit Lifestyle Co., Ltd.
ホットペッパービューティーにおけるモバイルアプリ向けAPIのBFF/Backend分割
by
Recruit Lifestyle Co., Ltd.
データサイエンティストが力を発揮できるアジャイルデータ活用基盤
by
Recruit Lifestyle Co., Ltd.
Real-time personalized recommendation using embedding
by
Recruit Lifestyle Co., Ltd.
データから価値を生み続けるには
by
Recruit Lifestyle Co., Ltd.
データプロダクト開発を成功に導くには
by
Recruit Lifestyle Co., Ltd.
Jupyter だけで機械学習を実サービス展開できる基盤
by
Recruit Lifestyle Co., Ltd.
SQLを書くだけでAPIが作れる基盤
by
Recruit Lifestyle Co., Ltd.
BtoBサービスならではの顧客目線の取り入れ方
by
Recruit Lifestyle Co., Ltd.
The Design for Serverless ETL Pipeline データ分析基盤のレガシーなデータロードをサーバレスでフルリプレースするまで道のり
by
Recruit Lifestyle Co., Ltd.
リクルートライフスタイルにおける深層学習の活用とGCPでの実現方法
by
Recruit Lifestyle Co., Ltd.
ビックデータ分析基盤の成⻑の軌跡
by
Recruit Lifestyle Co., Ltd.
Refactoring point of Kotlin application
by
Recruit Lifestyle Co., Ltd.
データサイエンティストとエンジニア 両者が幸せになれる機械学習基盤を求めて
by
Recruit Lifestyle Co., Ltd.
Editor's Notes
#2
分散トレーシング AWS X-Rayとの上手い付き合い方 の発表を行いたいと思います。 リクルートライフスタイル所属の奥冨です。 宜しくお願いします。
#3
まず自己紹介から 経歴として、新卒でゲーム会社に入社し、オンラインゲームの開発などやっていました。 中途で今の会社に入りまして、横断開発している社内ライフラリを担当していました。 去年からホットペッパー領域に入り、新サービスの開発を行っています。
#4
次に、今日の話の概論といいますか、サラッと内容を まず、分散トレーシングの仕組みについて X-Rayの説明後に導入してプロダクトがどう変わったのか、 取り組んだ施策について話たいと思います。 特に見て頂きたい観点として これから分散トレーシングを導入するプロダクト 特にX-Rayを検討されている方の参考資料として見て頂きたいです。
#5
アジェンダになります。 プロダクト紹介から、分散トレーシングの説明、プロダクトでの利用した話を順を追って話していきたいと思います。
#6
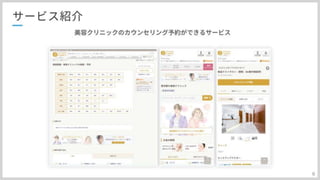
最初はプロダクトの説明から
#8
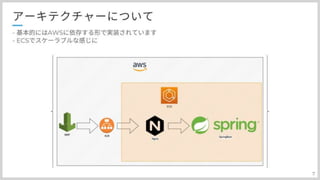
プロダクトのアーキテクチャについて説明いたします 基本的にはaws内で完結するように、完全依存するように作られていまして ECSを使うことで、スケーラビリティを持たせています。 WAFから入ったリクエストをALBで、ECSの各タスクに振り分けています。 各コンポーネントの前段には必ず、nginxをおいていまして 役割としてはリバースプロキシであったり、Springが障害で落ちた際の検知だったりします。 静的コンテンツも、nginx層でCDNにプロキシしたりしています。
#9
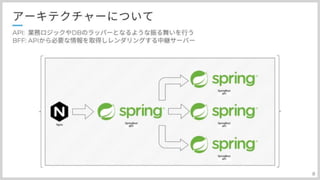
ECSタスクといっても複数ありまして、主にBFF,APIに分かれています。 APIはDBからデータを引っ張ってきて業務ロジックを実行して返すところ BFFは、APIからのデータを受け取ってレンダリングしてブラウザに返すといった役割があります。 このようにロジック毎にコンポーネントが別れているのを分散アーキテクチャまたはマイクロサービスといいます。 詳しいアーキテクチャについては、リクルートライフスタイルのテックブログにかかれていますので、 もしよろしければそちらをご覧ください。
#10
プロダクトが抱えていた課題について紹介したいと思います。 先程紹介したようにコンポーネントが独立しているので、 それぞれでログ出力しているので、HTTPリクエストからの一連の流れを追う コンポーネント横断的な障害調査だったり、ボトルネック調査が出来なかった。 ログに出力するUUIDの発番すればよかったんですが、その仕組もなかったというのが導入以前の課題でした。
#11
次に分散トレーシングについて
#12
分散トレーシングについて紹介したいと思います マイクロサービスのような複数のサービスで構成されるシステムでは 1つのリクエストが複数のサービスをまたいで処理されることにより、リクエスト全体の処理の流れを把握することが難しくなります。 また、トレーサビリティが低下することによって障害やリクエストのレイテンシーが悪化した際に、 どのサービスに問題があるのかを見つけることも難しくなります。 このような問題をサービスの依存関係やサービス単位のレイテンシーを可視化することによって、 解決の手助けをするシステムを分散トレーシングシステムといいます。
#13
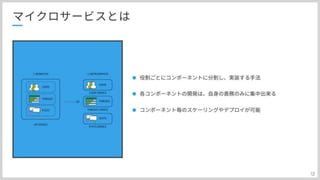
マイクロサービスという単語が出てきましたので補足説明になります。 前のページで出てきたマイクロサービスですが、 役割ごとに別れているので、並列に実装可能だったり 実装中も責務が限定されているので、複雑な依存関係が生まれないなど 様々なメリットがあります。
#14
一方デメリットとしては、 後ほど例として紹介致しますが、 障害が発生したときに追いづらいであったり、 コンポーネント間で通信が発生するのでラグが必ず発生する コンポーネント間をまたいだトランザクションが貼れないなど、デメリットも存在します。
#15
今回は、障害調査がしにくいというデメリットにたいして、 分散トレーシングを使って解消したという話を紹介したいと思います。
#16
分散トレーシングの代表的な標準規格としてOpenTracingとOpenCensusがあります。 Google のような大規模なハイテク企業が分散トレースを使用していたのに対して 10年以上の間、全体的な採用は遅れていました。 OpenTracingは、大企業使われているようなトレースを一般に! を目的として2016年に立ち上げられました。 一方、OpenCensusはGoogle が社内で利用しているメトリクス収集、トレーシングのライブラリ集のOSS バージョンとして2018年にリリースされました。 OpenTracingの著者は、これを インストルメンテーションのポイント - リクエストがすべてを通過するさまざまなプロセス 相互運用するために必要な計装を必要とし、既存の計装オプションは以下のようになります。 は必ずしも特定のトレースベンダにバインドする必要はありません。 これまで述べてきたように、トレース 2018年初頭、Googleは内部の国勢調査プロジェクトのオープンソース版を公開した。 OpenCensusと命名しました。国勢調査は、異なる状況下で、異なる OpenTracingよりも制約があります。国勢調査プロジェクトの目標は、統一された Google サービスからトレースおよびメトリックデータを計測して取得する方法 が自動的に行われます。国勢調査チームは、gRPC などの技術との深い統合を構築しました。 これらの技術を使用した開発者は、基本的なトレースとメトリクスを無料で提供しています。 の追加作業を行いました。 このように、Census のデザインは OpenTracing. Census は、トレースとメトリクスのための SDK 全体で、完全な のためのgRPCと緊密に結合され、深く絡み合ったAPIに加えて コンテキストの伝播などの活動を行っています。オープンソースの国勢調査は、多くの点で以下のような取り組みでした。 既存の Google トレースインフラを Google サービスの外部ユーザーに拡張する。 スパナーなどのGoogleサービスは国勢調査を使ってトレースされ、外部からのリクエストも 国勢調査を利用してトレースされたものをシームレスに接続することができました。さらに、トレースを維持し メトリクス・フレームワークをさまざまなツールやベンダーと統合することは、非常に困難です。 コストがかかるため、オープンソース化の経済性はGoogleの勝利となりました。 OpenCensus の基本的な設計は OpenTracing とは大きく異なり、以下のようになっています。 図 3-4 に示す。前述のようにトレース API に加えて、メトリクス API が含まれている。 を使用したすべての実装のおかげで、コンテキストの伝播を自動的に処理することができました。 トレースコンテキストを伝播するための同じフォーマットを使用しています。これは、トレースの自動収集をサポートし このデータのローカル・ビューア(「zPages」と呼ばれる)とともに、統合されたフレームワークからのメトリクス。 これにより、箱から出してすぐに使えるようになります。最後に、ランタイムに頼るのではなく トレースアナライザにデータをキャプチャしてエクスポートするためのAPIのスワップ可能な実装は、それが は、ほぼすべてのバックエンドにデータをアップロードできるように、プラグイン可能なエクスポータモデルを提供しました。 デザインと同様に、仕様は異なります - いくつかのプリミティブな型に焦点を当てるのではなく、それは は、図3:5に示すように、お互いに構築するいくつかの異なるコンポーネントを定義しています。 OpenCensus メトリクス収集、[分散トレーシング] のためのライブラリ群。データの収集までを担い、グラフ化や分析は他のサービスを利用する。Google が車内で利用しているメトリクス収集、トレーシングのライブラリ集 Census の OSS バージョンとして2018/1 にリリースされた。
#17
オープンテレメトリはOpenTracing OpenCensusが統合した新しいプロジェクトです。 統合したのは最近ですが、先程紹介した2つの規格の次期メジャーバージョンとして、現在開発が進められています。 インストルメンテーション・ライブラリを書くことは、一言で言えば難しいことです。実際のプロセスでは サービスからテレメトリを収集して生成することは、概念的にはかなり簡単です。 そのプロセスをパフォーマンスの高い方法で実施することで、多様な人々の賛同を得ることができます。 ユーザーのグループは非常にやりがいがあります。その理由の第一は、どのような2つの ソフトウェアの断片が共通して持っているものは、非常に異なっている可能性があります。これは の課題を議論する際には、やや還元主義的ではあるが、心に留めておくと便利なことである。 一般ユーザ向けのインストルメンテーション・ライブラリを書くことができます。しかし、いくつかの良い カスタムメイドよりも汎用インストゥルメンテーション・ライブラリの方が良いと思われる理由を説明します。 汎用ライブラリの方が、一般的な用途ではよりパフォーマンスが高くなります。 のケースを考慮している可能性が高い。 汎用ライブラリの作者は、エッジケースを考慮した可能性が高い など、様々な状況に対応しています。 汎用ライブラリを使用することで、数ヶ月間のメンテナンスの頭痛の種であった カスタムメイドのものを適応、拡張、および使用することができます。 ソフトウェアがより複雑になり、開発サイクルがより緊迫してきます。 汎用図書館の合理性への欲求が高まる おそらく、あなたには時間がなかったり を使用して、独自のテレメトリコレクタや API を実装することができます。を作成する専門知識がないかもしれません。 アプリケーションで使用されるすべての言語に対応した特注のテレメトリ・ライブラリを保守するか、または は、内部標準を作成するための組織的なダイナミクスが乗り越えられないと感じるかもしれません。 最後に、おそらくあなたは、次のような点で車輪を再発明する必要はないでしょう。 RPC フレームワーク、HTTP ライブラリなどの依存関係からテレメトリデータを取得することができます。 OpenTelemetry はこれらの問題を解決し、他の多くの問題を解決してくれます。の主な目的は OpenTelemetryは、API、ライブラリ、エージェント、コレクターの単一のセットを提供することです。 を使用して、アプリケーションから分散トレースとメトリック遠隔測定をキャプチャします。そうすることで OpenTelemetryは、ポータブルで高品質なテレメトリデータが組み込まれた世界を想像しています。 クラウドネイティブソフトウェアの特徴 OpenTelemetryは、2019年5月に正式に発表された次のメジャーリリースとして、両方の OpenTracing と OpenCensus。この2つのプロジェクトは似たような目標を持っていましたが、方法は異なります。 を達成するために OpenTelemetryの種は2018年秋にいくつかのワイド 両プロジェクトが直面している主要な躓きを結晶化させた、広範囲にわたるTwitterのスレッド。 の間の「規格戦争」の様相。オープンソースプロジェクトの作者は、それを見て 計装用に2つの互換性のない規格があった場合、トレースの追加を延期して のライブラリやフレームワークを使用していますが、どのライブラリやフレームワークに焦点を当てるべきかについてのコンセンサスがない場合は、そのライブラリやフレームワークを使用しています。 (詳細については、「OpenTracing」と「OpenCensus」を参照)。 これらの意見の相違やその他の意見の相違が、バックチャンネルの交渉や 中立的なメディエーターとともに、各プロジェクトの創設者が参加しています。小さな技術チームが結成されました。
#18
ちょうど今年の四月にオライリーから分散トレーシングの本が出ましたので、紹介致します。 ちょっと画像は版権上乗せられないんですが、、、 ここまでのことはすべてこちらに書かれています。 まだ和訳は出ていないんですが、おすすめです!
#19
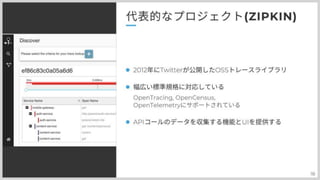
また分散トレーシングの代表的なライブラリを紹介します。 Zipkinです。 Twitter社によって開発されたOSSの分散トレーシングシステムで Zipkinでは、各サービス間のAPIコールのデータを収集する機能と、そのデータを可視化するためのUIを提供しており 先程紹介した、OpenTelemetryでもサポートされています。 ジップキン TwitterはZipkinを開発し 2012年にオープンソースコミュニティに公開しました それは 注目すべきは、リリースされた Dapper スタイルのトレースの最初の人気のある実装の一つであることです。 でサポートされている規約の多くは、オープンソース・ソフトウェア・ライセンスの下にあります。 より広く分散したトレースの世界は、それらを普及させるためにZipkinに借りがあります。全体的には、Zipkin には、トレース分析バックエンド、コレクター/デーモンプロセス、クライアントライブラリと 一般的なRPCやWebフレームワークとの統合が可能です。 Zipkinで使われている用語の多くは、以下のような理由で他のトレースシステムにも移植可能です。 Dapper紙からの共有遺産です。スパンは一つの作品の単位であり、トレースは スパンのコレクション;などなど。ジプキンの中でも特に不朽の名作の一つが を介してトレースコンテキストを渡すためのデファクトスタンダードとして B3 HTTP ヘッダを普及させる ワイヤB これらのヘッダは事実上 W3C TraceContext 仕様に取って代わられています。 特に OpenTelemetry でサポートされているので、野生で見られる可能性が高いです。 [/ Reporter] : ログを送信する。 [/ Collector] : ログを収集する。HTTP, Kafka, RabbitMQ, Scribe がサポートされている [/ Storage] : ログを永続化する。In-Memory, MySQL, Cassandra, Elasticsearch がサポートされている
#20
次にX-Rayの紹介になります。
#21
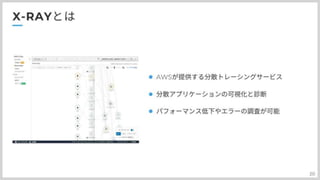
X-Rayの紹介になります。 X-RayはAWSが提供する分散トレーシングサービスで、基本的には 提供されているSDKを組み込んで、AWS側にトレースデータを送信する 送信したデータをAWSのコンソールで確認するという形で使用します。 X-Rayは、Amazon Web Services (AWS)の製品で、以下のような分散トレースを提供します。 アプリケーションをAWSエコシステム上で実行しています。X-Rayの利点の1つは、深い統合 をAWSクライアントSDKに組み込むことで、様々なAWSマネージドコールをシームレスにトレースすることができます。 サービスを提供しています。さらに、X-Rayはトレースデータのために以下のような一連の分析ツールを提供しています。 トレースビジュアライザとサービスマップがあります。 高レベルでは、X-Ray はスパンベースのトレースシステムと多くの共通点があり、いくつかの の命名規則の違いを示しています。X-Rayではスパンではなく、セグメントという用語を使って をトレースされている作業単位に変換します。セグメントは アプリケーションのホスト名、リクエスト/レスポンスの詳細、発生したエラーなど。 操作中に、セグメントは任意のアノテーションやメタデータを追加することができます。さらに、セグメントは任意のアノテーションやメタデータを追加することができます。 開発者は、それらを分類して分析するのを助けるために 個々のスパンを使って 一つのリクエストの中で行われた作業をキャプチャするために、X-Ray は サブセグメントでは、ダウンストリームコールの詳細なタイミング情報をキャプチャします。 リモートまたは内部。単一の論理リクエストのすべてのセグメントが単一のトレースにロールアップされます。 を使用しています。X-Ray は独自のトレースヘッダ X-Amzn- TracelDは、X-Ray SDKと他のすべてのAWSサービスによって伝播されます。この単一キー ルートトレース識別子、サンプリング決定などのトレースに関するすべての情報を含みます。 と親セグメント(該当する場合)があります。 機能的には、X-Ray は X-Ray SDK と連携したデーモンプロセスに依存しています。 を使用して遠隔測定データを収集します。からセグメントデータを受信するためには、このデーモンが存在するか、利用可能でなければなりません。 あなたのサービスに転送し、それを X-Ray バックエンドに転送してトレースの組み立てと表示を行うことができます。 X-Ray についての詳細は開発者向けドキュメントを参照してください。
#22
先ほど紹介したZipkinとの比較です。 X-Rayはサービスでの提供なので、一概には比較出来ませんせんが このような差分があります。 特にトレースデータ保管に関しては、zipkinではDBの種類から保存期間まで柔軟に設定できます 対してX-Rayでは30日と限られています。 メリデメでみるとDBの管理をしなくてもいいのですが、30日から引き上げが出来ないのでそこがデメリットですね。 後は、AWSが提供するサービスということもあり、他に提供しているRDSやS3などもトレースすることが可能です。 自分のプロダクトでは、AWSに依存していますので、その点でX-Rayを採用することとなりました。
#23
自分のプロダクトでは、AWSに依存していますので、その点でX-Rayを採用することとなりました。
#24
X-Rayの構成要素は主に X-Ray API,Daemon,consoleの3つになります。 トレーデータの送信、受信用のAPIがあり、 アプリケーションとしては直接送信するのではなく、デーモン経由で送信します。 最後にコンソールですが、ここのトレースデータの回覧以外にも期間内の平均レスポンスタイムや 障害率なども表示してくれます。 X-Rayの構成要素 X-Ray API──管理のためのAPI データの送信,取得などを行うためのAWS側にあるAPIです。SDKからのデータは直接APIに対して送信されるのではなく,次に説明するエージェントソフトウェア,X-Ray daemonを経由します。 X-Ray daemon──トレース転送用デーモン アプリケーションからネットワーク経由でセグメントデータを受信するエージェントです。通常はアプリケーションと同一ホストで稼働し,受信した複数のセグメントデータをまとめてX-Ray APIへ送信する役割を担います。 X-Ray SDK──アプリケーションに組み込むライブラリ アプリケーションに組込み,実際にトレースを取得するライブラリです。2019年5月時点ではJava,JavaScript,.Net,Ruby,Go,PHP,PythonのSDKが公式で提供されています。 SDKはアプリケーション内部の処理を捕捉し,X-Ray daemonに対してセグメントデータを送信します。 X-Ray console──トレースを可視化する X-Ray APIに送信されたトレースをブラウザ上で可視化して表示するコンソール画面です。どのコンポーネントで障害や遅延が発生しているのかの概観,個々のトレースの表示,検索などが行えます。
#25
実際にコンソールについて紹介したいと思います
#26
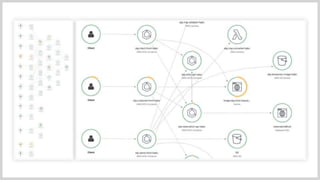
左側に見えているのは、コンポーネントの一覧をマップにしたもので、 拡大してみてみると、アクセスによる依存関係が書かれています。 緑と黄色で別れている部分があると思いますが、 緑が200系,黄色が400系,赤が500系のレスポンスを表しており その割合になっています。
#27
トレース画面で最初に処理されるBFFのトレースデータが表示されています。
#28
次にAPIの処理が処理順に記載されています。 各APIのレスポンスタイムと200と書かれているのが、レスポンスのステータスコードになっています。 ここで実際に画面を紹介します
#29
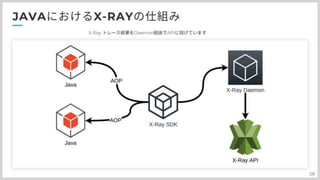
X-Rayの仕組みについて紹介したいと思います AWSが提供している、X-Ray SDKがAOP、spring AOP という仕組みを使いまして、Javaのメソッド実行前後に計測処理とか スタックトレースの取得処理を挟んでいます。 計測したデータをDaemonに送信して、DaemonがまとめてX-Ray APIに送信しています。
#30
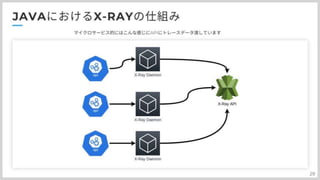
マイクロサービスなので、コンポーネント毎にみると それぞれにDaemonがいて、X-Ray APIを叩いている感じになります。 それぞれがX-RayAPIにデータを送信して、AWS側で一つの画面に情報をまとめているって感じです
#31
ちなみにX-Ray Daemonは公式でdockerイメージが提供されていて、 自分たちのプロジェクトですと、docker composeで一つのにまとめてECSにデプロイしています。
#32
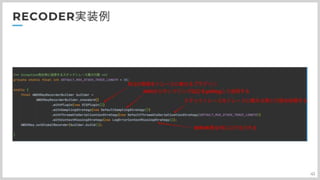
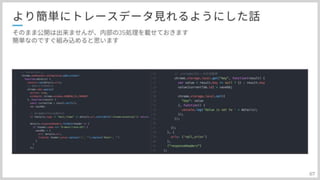
先程名前が出てきた、Filter,Recoderですが 設定例をここで紹介したいと思います。 まずFilterですが、こんな感じに設定しています。 コンソール画面にて出てくる、コンポーネント名は AWS_XRay_Tracing_Nameという環境変数がまず使われます。 それが設定されていない場合に、画像のように名前設定のStrategyクラスが名前を決定します。 画像では末尾に環境名を追加しようとしています 次に、FilterのDispatcherTypeの設定ですが、Request以外にErrorを追加する必要があります。エラーハンドリング時のトレースがこれで有効になります。 最後にFilterの優先度ですが、ログにトレースIDを出す手前、最速で採番してほしいので、一番最初に来るように設定しています。
#33
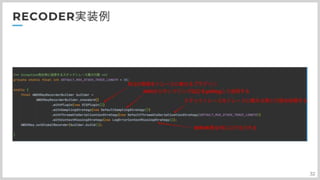
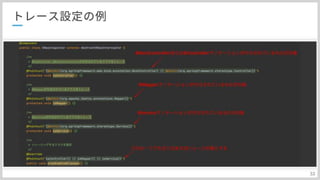
次にRecoderです 色々と設定項目があるんですが まず、pluginの設定ですね。 ここで実行環境のプラグインを指定することで、その環境の詳細情報をトレース結果に乗せてくれます。 ECS以外にもEC2とかEKSなどがあります。 次にサンプリングの設定です。ここではdefaultSamplingを指定しているので、定期的にawsからpollingして、反映する設定です。約5分間隔ですね これ以外にもすべてトレースするAllSamplingStrateするだったり、逆にSamplingしないNoSamplingStrategyなどがあったりします。 次にThrowableSerializationStrategyです。ここはスタックトレースに関する処理を決めるんですが、defaultクラスを設定すると スタックトレースの先頭50行をトレース情報に載せてくれます。ここで自身のプロダクトでは半分の25行に設定しています。理由はあとで説明します。 最後に、ContextMissingStrategyですこれ、エラーをどう処理するかなんですが、基本的はLogErrorContextMissingを指定して、ログにエラーを吐き出すようにするのがいいかと 先程の、スタックトレースの行数を半分に設定している理由ですが
#34
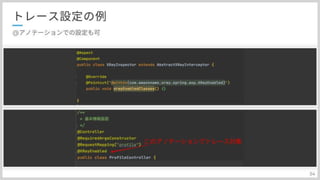
次にどうやってトレース対象を設定しているのか紹介したいと思います トレース方法としては、AOP, Spring AOPを使用しています。 指定したメソッドの処理の前後に、意図的に処理を挟み込めるんですね。 実装ですが基本的には、X-Ray SDKが提供するInterceptorクラスをextendしてAOPに登録します。 @withinという指定子を使って、アノテーションだったり、クラスだったり、メソッドだったりを指定することが出来ます。 自身のプロダクトでは、@RestController,@Controllerといったコントローラーアノテーションを指定しています。 明確にはアノテーションが付与されたクラスですね。 あとは、DB層のMapperアノテーション、そしてSpringのServiceアノテーションになります。 この4つのアノテーションが基本的なトレース対象としてプロダクトでは使っています。
#35
あの様な設定以外にも、公式のドキュメントに書かれた方法ですがこういったのもあります。 X-Ray SDKでX-Ray Enabledといったアノテーションが提供されているので、 そのアノテーションをトレース対象にして、後はトレースしたいクラスにアノテーションを付与していくやりかたです。
#36
それ以外にもトレースするための便利なクラスがSDKで用意されてます。 RestTemplate用だったり、AWS SDKに組み込むようのTracing Handlerだったり、 DBトレースも用意されています。
#37
次にサンプリング設定についてです。 基本的には、AWS のX-Rayコンソール上でぽちぽち設定します。 アプリケーションの設定ファイルには何も書かなくていいんです。 複数のルールがかけますので、静的ファイルへのアクセスを除外したり とある環境だけ、サンプリング率を100%にしたりと、用意されている変数は多いので カスタマイズしたルールが作れます。
#38
実際にプロダクトで使用してみて プロダクトが、プロジェクトがどう変わったのかというのを紹介したいと思います
#39
複数あるので、目次なんですが トレース対象の話だったり、パフォーマンス検証を行った話 実際に使ってみて、料金どうなのみたいな あとは
#40
プロジェクトのコミュニケーションがどういう風に変わったのが あとは、用意されているクラスが拡張性高いので、どうカスタマイズして使いやすくしたのか というところを紹介していきたいと思います。
#41
プロダクトのX-Ray設定について紹介致します。 ここでは、X-Ray Recoderクラスで特別に対応していた箇所の理由について紹介したいと思います。
#42
X-Rayの設定の箇所でも話しましたが、 ここのスタックトレースの表示行数を25行に設定している理由についてになります。
#43
Message TOO Longエラー対策でやってました。 これはどういったエラーなのかというと、X-Ray SDKがX-Ray Daemonにデータ送信する際に UDPを使うんですが、その転送サイズの上限を超えるとこういったエラーが出てきます。 なんで転送サイズを超えるのかというと、Or MapperとかスタックトレースにSQL文が入ってきたり 1行がながいスタックトレースの場合に、超えてしまうんですね。 これが出たからと言って、アプリケーションに影響は無いんですがエラーログは吐き出されるので エラーとして通知されてしまうんですね。 これがですね、エラーが起こるたびに一緒に出てくるので、X-Ray導入者というか担当者に めちゃくちゃ問い合わせがくるんです。
#44
こんな感じですね。 これは毎回説明するのも大変ですし、回数も回数なので スタックトレースの行数は50から25ぐらいに減らしたほうがいいかなと思います。 25に減らしても、スタックトレース追跡出来るので、今の所問題になってないです。
#45
次にサンプリング、トレース対象についてです BFFとAPIでトレース対象が違うので、個別に話していきます
#46
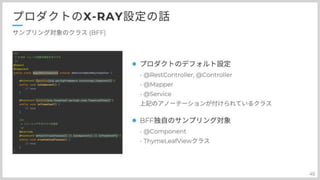
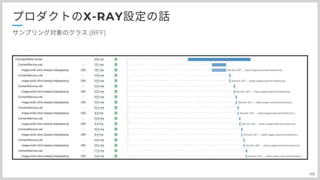
まずBFFになります。 先程話しました RestController Controller Mapper Serviceの他に ComopnentとレンダリングエンジンのthymeLeafを対象にしています。
#47
レンダリングにどれくらい掛かっているのかというのと レンダリング時に何をしているのかを確認するためにこれを追加しています。
#48
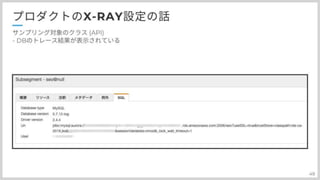
次にAPI側のトレースになります。 先程のアノテーションに追加して、DBトレースを行っています。
#49
ちょっとなまえがnullになってしまっているんですが DBトレースするとこういうふうに画面に出てきます。 理由として、mariadb Driverを使っているんですが jdbcURLが特殊なので、そのパースがうまく行っていないんですね ちなみに、こちらクリックすると
#50
DBの種別だったり Driverのバージョン、urlやuser名などが取れます。 SQL文は取れないようになっています。
#51
次にサンプリングのレートについてです ここには cssを除外するルールと環境別ルールが記載されています。 cssは0%で設定しており、環境別としては100%でSamplingを行っています。 100%にする理由ですが、障害発生時のみ、ステータスコードがエラーの時のみ 強制Samplingっていうことが出来ないので、前もって100%で設定してます。
#52
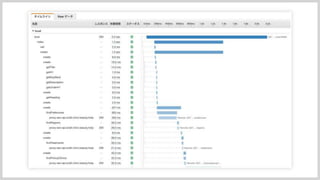
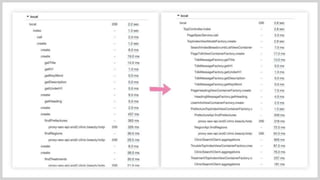
次にX-Rayのカスタマイズの紹介になります。 こちらデフォルトのコンソール画面なんですが、 各セグメントの名前が、indexだったり,createだったりでパット見よく分からないですよね これはメソッド名なんですが、クラス名はクリックしないと分かりません。 さすがに見ずらいので、SDKのクラスを拡張してみました。
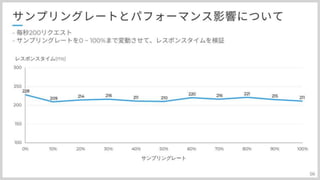
#53
AOP用のInteceptorクラスですが、ちゃんとセグメント名を決めるメソッドはprotectedで定義されているので拡張しやすいです。 画像では、AOPのjoin pointからクラス名、メソッド名を取得して使っています。 セグメント名には禁止文字がありますので、ちゃんと置換するのを忘れずに! これを書くだけで
#54
右が対応後なんですが どのクラスの処理なのか分かりやすくなったかなと思います。
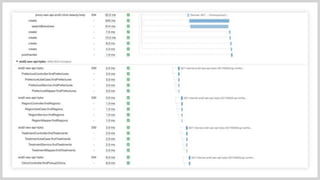
#55
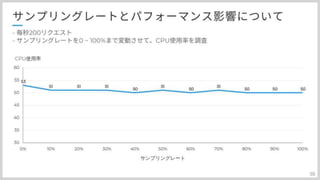
サンプリングレートの話しましたが、100%だとパフォーマンスに影響出るのではと検証を行いました。
#56
実際に高負荷環境に置きまして、サンプリングレートを0から100%まで変動させてみました。 こちらCPUですが、特に影響無さそう レスポンスタイムで見てみると
#57
こちらも横並びで影響無さそう
#58
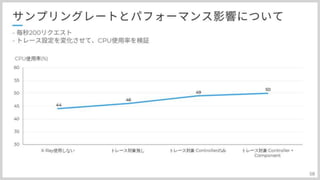
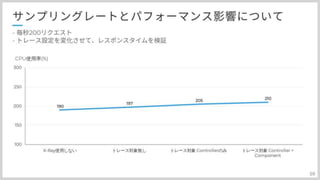
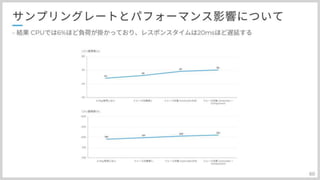
ただ、サンプリングレートは影響無さそうだが、トレース設定はどうなんだろうという疑問が生まれたので 検証してみました。
#59
一番左から、そもそもSDKを入れない設定からSDKをだけ入れた、+コントローラーのトレースのみ、+コンポーネントも という順に試してみました。 AOP挟んでいるだけあって影響はありました。SDKの組み込みだけでも影響ありますが トレース対象の数も関係しています。
#60
レスポンスタイム的にも20msぐらい遅くなっています。
#61
トレースして送信して、、って一連の処理を行うのでパフォーマンス影響あるのは仕方がないですが あまりトレース対象増やしすぎるのも危ないですね。
#62
次に掛かった料金を見て行きたいと思います。 実際に開発環境を例として、 6つの環境がありまして、すべて100%サンプリングしております 結果一ヶ月に300万リクエストぐらい流れています。
#63
結果なんですが、無料枠も合わせて5$ぐらいしか掛かってないです ここ最初見た時びっくりしたんですが、割引されているとかではなく、ずっとこの料金ですね。 レットブル2本分で払えるのは安いかなと思います。
#64
次にX-ray導入でプロジェクトのコミュニケーションがどう変わったのか紹介したいと思います。 基本的にX-Ray見れば、スタックトレースも見れますし、どのAPI叩いたのかもわかりますし みなさんトレースIDで会話するようになりました。 エラー通知BOTって各プロダクトにあると思うのですが、トレースID毎のコンソール画面URLが簡単に作れるので すぐ組み込むことが出来ます。 末尾にトレースIDくっつけるだけですね。
#65
あとは、ログにトレースIDを吐き出しているので うちはAWSなのでCloudWatchを使いますが、IDで検索するだけで 横断的に処理が終えるので楽になりました。
#66
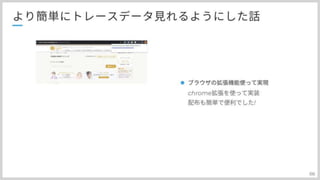
ちょっと番外編なんですが、 ブラウザでサイトアクセスして、トレースID取得してコンソール画面見に行くっていうのが ちょっと面倒なんですね chrome開いて開発者ツール起動して、レスポンスヘッダーみて〜〜みたいな なので、chromeの拡張を作りまして一発でコンソール画面に飛んでトレース情報を見れるようにしました。
#67
こんな感じで、右上にPOPするようになっていまして リンクになっているので、すぐ飛べるという
#68
仕組み自体は簡単なので、すぐ導入できます。 これbackground.jsですが、これ書いて、あとは受け取る側書くだけなので
#69
最後にまとめになります
#70
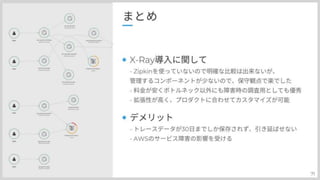
最後に再度、プロダクトが抱えていた課題について紹介したいと思います。 障害調査が出来なかった。 ボトルネック調査が出来なかった。 ログに出力するUUIDの発番が出来なかったなどがありました。 これをX-Ray導入によって
#71
X-Rayコンソールに必要な情報がまとまるようになったので、障害調査ができるようになったり その情報使ってボトルネックを調べたり、 ログについてもトレースIDをUUIDとして、出力することで横断的なログ検索が可能になったり そういった課題解決が出来ました。
#72
X-Ray導入に関して Zipkinを使っていないので明確な比較は出来ないが、管理するコンポーネントが少ないので、保守観点で楽でした 料金が安くボトルネック以外にも障害時の調査用としても優秀 拡張性が高く、プロダクトに合わせてカスタマイズが可能 というのが使ってみた感想ですね 合わせて使いづらいところとしては、トレースデータが30日まで保存されないし、伸ばせないので そこは調査観点で見ると使いづらいかなと思いました。 あとは、ちょくちょくあったんですがAWSのサービス障害のあおりを食らうところですね トレースデータが見れなくなったり、エラー吐いたりっていうのは、サービスとして利用しているので仕方ないと思いつつも自前でデータを管理するzipkinとかがうらやましく思えました。 以上が私からのプレゼンになります。 つたない発表でしたがご清聴ありがとうございました。
Download

















































![[AWS EXpert Online for JAWS-UG 18] 見せてやるよ、Step Functions の本気ってやつをな](https://cdn.slidesharecdn.com/ss_thumbnails/awsxon18howfarstepfunctionsgo-211124111849-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス](https://cdn.slidesharecdn.com/ss_thumbnails/amazonauroratips-170307140000-thumbnail.jpg?width=640&height=640&fit=bounds)





































