Download as PDF, PPTX


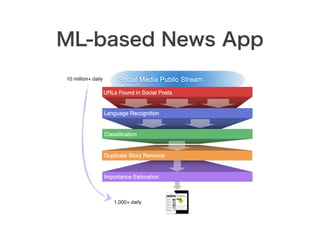






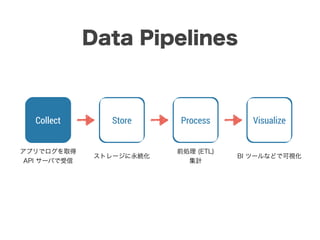



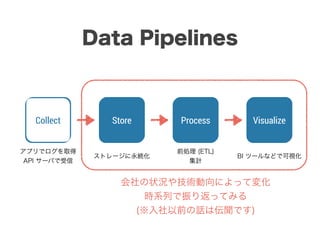
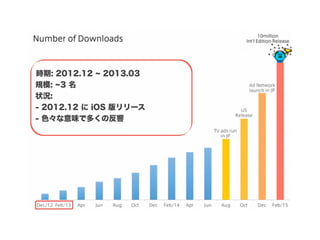

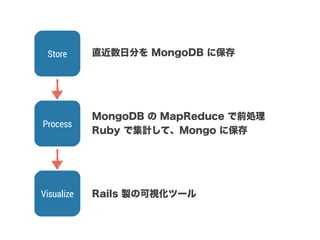
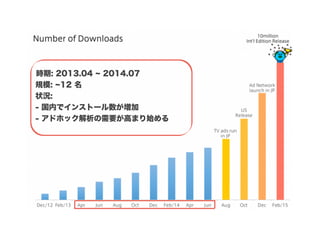

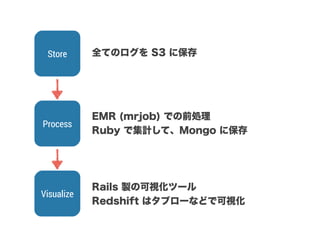
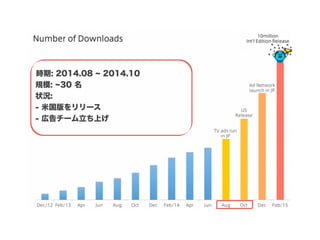

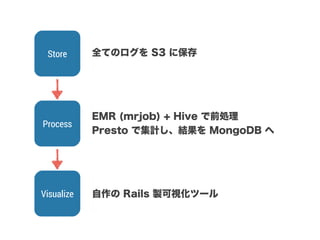
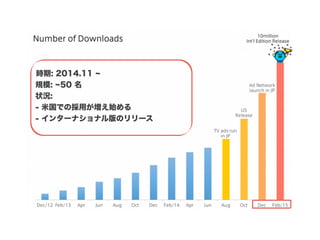


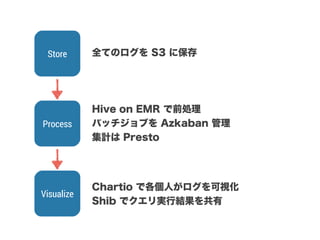


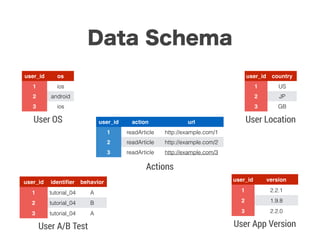

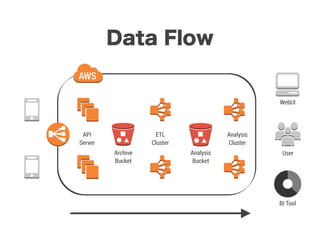


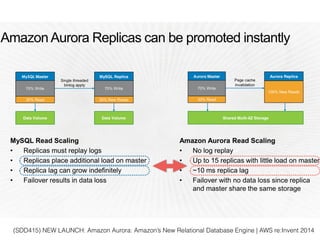
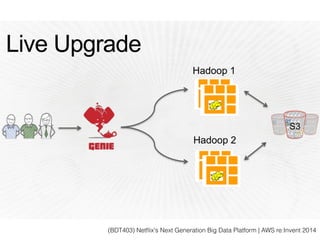
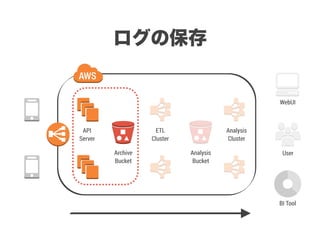
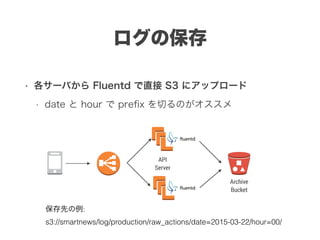
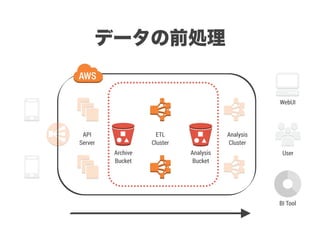


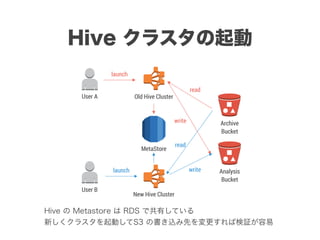





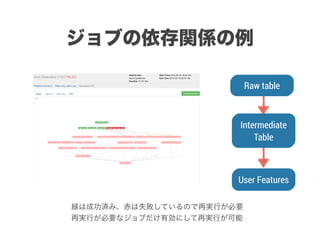

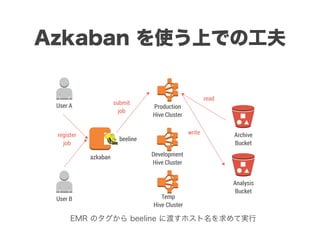
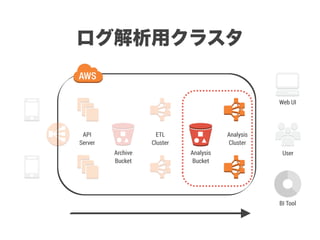

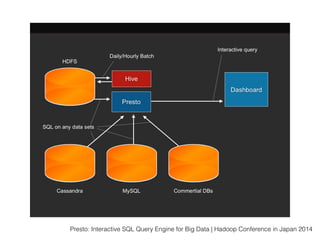



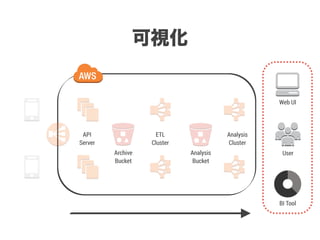

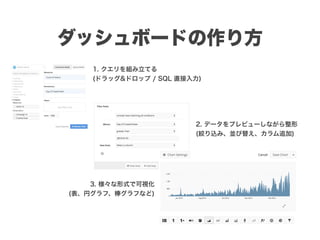


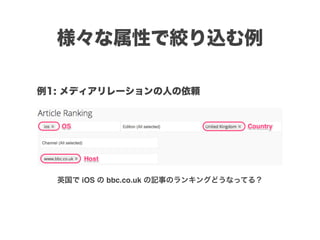
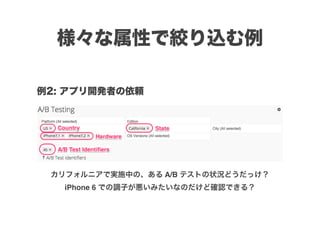










スマートニュースは昨年の 10/1 に米国版をローンチするにあたり、ログ解析基盤のリニューアルを行いました。日本に加えて米国やその他の国が入ってくることにより、単なるユーザ数の増加に加え、OS x 国 x タイムゾーン x 多種多様なメトリクスのような集計軸が増えることで、ログの前処理、集計、可視化に様々な工夫が必要になってきます。本セッションでは、会社の成長に応じたログ集計基盤の転換を振り返りながら、世界進出にあたってどのようなことを考え、どのようにログ集計基盤をリニューアルしていったか、および、そのログ解析基盤を支える Amazon EMR, Hive, Presto, Azkaban, Shib, Chartio などのツールについてお話します。










































![[db tech showcase Tokyo 2014] D33: Prestoで実現するインタラクティブクエリ by トレジャーデータ株式会社 斉藤太郎](https://cdn.slidesharecdn.com/ss_thumbnails/dbtstokyo2014d33presto-141120012543-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)














![[db tech showcase OSS 2017] A14: IoT時代のデータストア--躍進するNoSQL、拡張するRDB by OSSコンソーシア...](https://cdn.slidesharecdn.com/ss_thumbnails/20170616dbtechshowcaseossyoshida-170621081930-thumbnail.jpg?width=640&height=640&fit=bounds)


