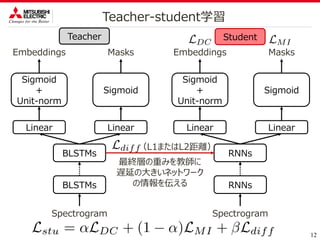
TEACHER-STUDENT DEEP CLUSTERING FOR LOW-DELAY SINGLE CHANNEL SPEECH SEPARATION
1.
(ICASSP2019音声&音響論文読み会)
TEACHER-STUDENT DEEP CLUSTERING
FORLOW-DELAY SINGLE CHANNEL
SPEECH SEPARATION
Ryo Aihara, Toshiyuki Hanazawa, Yohei Okato
(Mitsubishi Electric Corp.)
Gordon Wichern, Jonathan Le Roux
(Mitsubishi Electric Research Labs.)
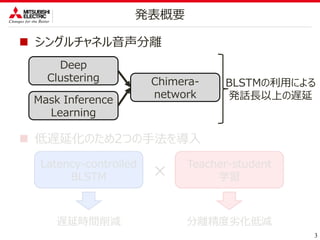
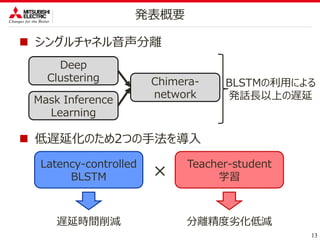
直接的なマスクの推定を避ける
スペクトルの(時間ー周波数)ビンに対して「埋め込みベクトル」を推定
埋め込みベクトルをK-meansしてマスクを推定
Kに話者数を与えることで、アルゴリズム上は何人でも分離可
5
Deep Clustering [J. R. Hershey et al., 2016]
埋め込みベクトル
tV
FxD
F
D
行列化 F
C
クラスラベル
t}{Y
F
tX
混合発話スペクトル
ベクトル
T
BLSTM
K-means Mask
D
6.
直接的なマスクの推定
求めるマスクは、ランダム値で初期化
2つのペアで誤差の小さい方を教師とする
6
Mask Inference Learning
[J. R. Hershey et al., 2016]
[D. Yu et al., 2017]
BLSTM
Speaker A + B
Target
Speaker A
Estimated
Mask ?
Target
Speaker B
Estimated
Mask ?
7.
Deep Clustering+ Mask Inference Learning
分離時にはMIで推定されたマスクを使用
汎化能力の向上によって、分離性精度が向上する
7
Chimera Network [Z.-Q. Wang et al., 2018]
BLSTMs
Linear
Sigmoid
Masks
Spectrogram
Linear
Sigmoid
+
Unit-norm
Embeddings
8.
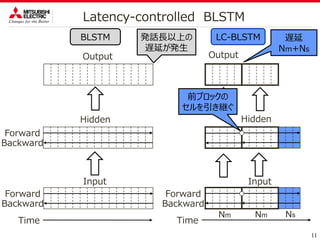
BLSTMではオンライン処理が不可能。
発話全体を入力とするため、発話長以上の遅延が発生。
まずは、処理開始までの遅延を削減したい。
関連研究
“LOW-LATENCY DEEP CLUSTERING FOR SPEECH
SEPARATION”, S. Wang et. al., ICASSP2019.
LSTMでDeep Clusteringを実装。
K-meansをブロック化。
BLSTMと比較して大幅な精度劣化は避けられない。
8
Our motivation



![ 直接的なマスクの推定を避ける
スペクトルの(時間ー周波数)ビンに対して「埋め込みベクトル」を推定
埋め込みベクトルをK-meansしてマスクを推定
Kに話者数を与えることで、アルゴリズム上は何人でも分離可
5
Deep Clustering [J. R. Hershey et al., 2016]
埋め込みベクトル
tV
FxD
F
D
行列化 F
C
クラスラベル
t}{Y
F
tX
混合発話スペクトル
ベクトル
T
BLSTM
K-means Mask
D](https://image.slidesharecdn.com/aihara20190603forupload-190608012655/85/TEACHER-STUDENT-DEEP-CLUSTERING-FOR-LOW-DELAY-SINGLE-CHANNEL-SPEECH-SEPARATION-5-320.jpg)
![ 直接的なマスクの推定
求めるマスクは、ランダム値で初期化
2つのペアで誤差の小さい方を教師とする
6
Mask Inference Learning
[J. R. Hershey et al., 2016]
[D. Yu et al., 2017]
BLSTM
Speaker A + B
Target
Speaker A
Estimated
Mask ?
Target
Speaker B
Estimated
Mask ?](https://image.slidesharecdn.com/aihara20190603forupload-190608012655/85/TEACHER-STUDENT-DEEP-CLUSTERING-FOR-LOW-DELAY-SINGLE-CHANNEL-SPEECH-SEPARATION-6-320.jpg)
![ Deep Clustering + Mask Inference Learning
分離時にはMIで推定されたマスクを使用
汎化能力の向上によって、分離性精度が向上する
7
Chimera Network [Z.-Q. Wang et al., 2018]
BLSTMs
Linear
Sigmoid
Masks
Spectrogram
Linear
Sigmoid
+
Unit-norm
Embeddings](https://image.slidesharecdn.com/aihara20190603forupload-190608012655/85/TEACHER-STUDENT-DEEP-CLUSTERING-FOR-LOW-DELAY-SINGLE-CHANNEL-SPEECH-SEPARATION-7-320.jpg)

![ データベース:Wall Street Journal (WSJ0)
Training: 20,000発話 (約30時間)
Validation: 5,000発話 (約10時間)
Test: 3,000発話(約5時間)
特徴量: 129次元log-magnitudeスペクトル
サンプリング周波数: 8k[Hz], フレームシフト: 8[ms]
分析窓: Hann窓, 窓幅:32[ms]
ネットワークと学習
Chimera Network (BLSTM, LSTM, LC-BLSTM)
Adam ( )
学習エポック数:100
評価指標
Signal-to-Distortion Ratio (SDR) [dB] 14
実験条件](https://image.slidesharecdn.com/aihara20190603forupload-190608012655/85/TEACHER-STUDENT-DEEP-CLUSTERING-FOR-LOW-DELAY-SINGLE-CHANNEL-SPEECH-SEPARATION-14-320.jpg)
![16
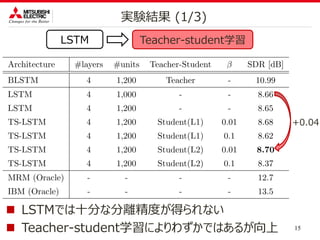
実験結果 (2/3)
9.8
10
10.2
10.4
10.6
10.8
11
Teacher-student学習BLSTM LC-BLSTM
BLSTM LC-BLSTM TS-LC-BLSTM
×
- (150,0) (100,50) (50,100) (100,50)(100,50)
TS距離 - - - - L1 L2
SDR[dB]
0.27
0.23
(Teacher)
遅延
発話長
以上 1.2 [s] 1.2 [s]1.2 [s] 1.2 [s] 1.2 [s]
r
Better
1.2[s]遅延 0.50[dB]の向上を実現](https://image.slidesharecdn.com/aihara20190603forupload-190608012655/85/TEACHER-STUDENT-DEEP-CLUSTERING-FOR-LOW-DELAY-SINGLE-CHANNEL-SPEECH-SEPARATION-16-320.jpg)
![17
実験結果 (3/3)
9.8
10
10.2
10.4
10.6
10.8
11
Teacher-student学習BLSTM LC-BLSTM
BLSTM LC-BLSTM TS-LC-BLSTM
×
- (75,0) (50,25) (25,50) (50,25)(50,25)
TS距離 - - - - L1 L2
SDR[dB]
0.27
0.12
(Teacher)
遅延
発話長
以上 0.6 [s] 0.6 [s]0.6 [s] 0.6 [s] 0.6 [s]
r
Better
0.6[s]遅延 0.39[dB]の向上を実現](https://image.slidesharecdn.com/aihara20190603forupload-190608012655/85/TEACHER-STUDENT-DEEP-CLUSTERING-FOR-LOW-DELAY-SINGLE-CHANNEL-SPEECH-SEPARATION-17-320.jpg)
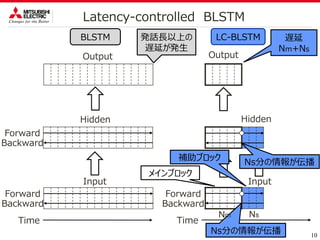
![ シングルチャネル音声分離の低遅延化手法を提案
18
まとめ
Latency-controlled
BLSTM
Teacher-student
学習
BLSTM
発話長以上遅延
10.99[dB]
0.6[s]遅延
10.19[dB]
0.6[s]遅延
10.31[dB]
今後の課題
さらなる遅延時間の削減
Teacher-student学習によるネットワークの小規模化?
ネットワークの
小規模化?](https://image.slidesharecdn.com/aihara20190603forupload-190608012655/85/TEACHER-STUDENT-DEEP-CLUSTERING-FOR-LOW-DELAY-SINGLE-CHANNEL-SPEECH-SEPARATION-18-320.jpg)



































![[DL輪読会]Discriminative Learning for Monaural Speech Separation Using Deep Embe...](https://cdn.slidesharecdn.com/ss_thumbnails/201912227dldiscriminativeleraningformanaouraspeechseparationusingdeepembeddingfeaturessumissionver2-191227001259-thumbnail.jpg?width=640&height=640&fit=bounds)


