Downloaded 32 times





















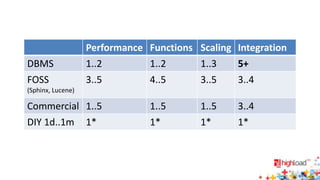


































Документ обсуждает выбор систем поиска, таких как Sphinx, Lucene и другие, акцентируя внимание на их сравнительных характеристиках, включая производительность, функциональность, масштабируемость и интеграцию. Основные рекомендации направлены на выбор подходящей системы в зависимости от конкретных требований, а также на необходимость тестирования и бенчмаркинга. Подчеркивается, что различия между системами могут сильно влиять на результаты поиска, и важно ориентироваться на реальные потребности перед выбором.
















































































