Download as PDF, PPTX







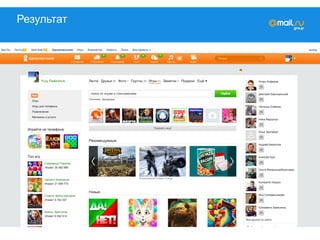
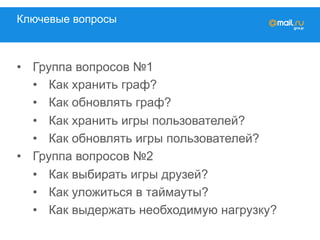
![Это очень простая задача
#!/usr/bin/env python
friends = {1: [2,3], 2: [1], … }
games = {1: [game1], 2: [game2], …}
wp = defaultdict(defaultdict([]))
ok_id = 1
for friend_id in friends[ok_id]:
for game in games[friend_id]:
wp[ok_id][game].append(friend_id)](https://image.slidesharecdn.com/mytarget-150320041428-conversion-gate01/85/C-myTarget-10-320.jpg)






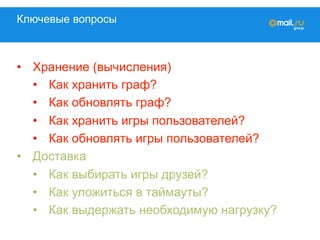





![Очевидное решение
• Считаем граф на hadoop (~90 гигабайт)
• Считаем игры на hadoop (~20 гигабайта)
• Заливаем в tarantool
1. вытаскиваем друзей пользователя:
• ok_id è [friend_id]
2. вытаскиваем игры друзей
• friend_idè [game]
3. Вытаскиваем имя и фамилию друга
• friend_idè {first name, surname}](https://image.slidesharecdn.com/mytarget-150320041428-conversion-gate01/85/C-myTarget-28-320.jpg)


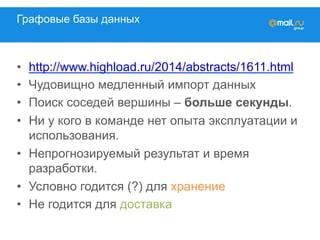
![Менее очевидное решение
• Считаем граф на hadoop (~90 Гб)
• Считаем игры на hadoop (~20 Гб)
• Считаем на hadoop игры друзей (~ 400 Гб)
• Заливаем в tarantool
1. вытаскиваем игры друзей пользователя:
• ok_id è [{game, [friend_id]}]
2. вытаскиваем имя и фамилию друга
• friend_id è {first name, surname}](https://image.slidesharecdn.com/mytarget-150320041428-conversion-gate01/85/C-myTarget-31-320.jpg)






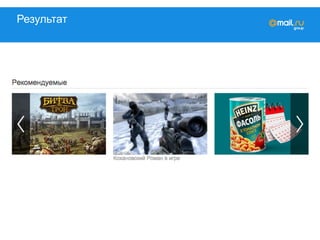
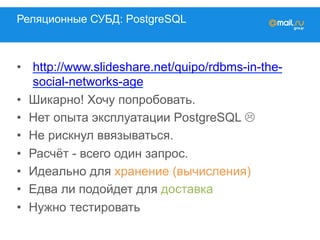
![Друзья
Расчёт: ok_id => { GENERATION: X,
FRIENDS: [friend_id]}
Дельта: ok_id => { ADDED: [friend_id],
DELETED: [friend_id],
KEEP: [friend_id]}](https://image.slidesharecdn.com/mytarget-150320041428-conversion-gate01/85/C-myTarget-41-320.jpg)
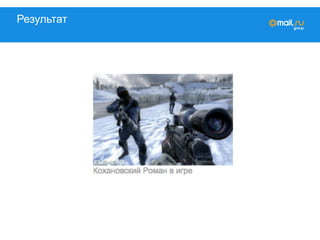
![Игры
Расчёт: ok_id => { GENERATION: X,
GAMES: [game]}
Дельта: ok_id => { ADDED: [game],
DELETED: [game],
KEEP: [game]}](https://image.slidesharecdn.com/mytarget-150320041428-conversion-gate01/85/C-myTarget-42-320.jpg)
![Соединение
ok_id => { ADDED: {[friend_id], [game]}
DELETED: {[friend_id], [game]}
KEEP: {[friend_id], [game]}}](https://image.slidesharecdn.com/mytarget-150320041428-conversion-gate01/85/C-myTarget-43-320.jpg)
![Инверсия связей
friend_id => {
game: {ADDED: [ok_id],
DELETED: [ok_id],
KEEP: [ok_id]}
}
• Последний штрих: из списка играющих в игру друзей
случайным образом выбираем пять, остальные
выкидываем (для большинства пользователей не
выкидывает ничего, но вот отдельных странных
порезало основательно)](https://image.slidesharecdn.com/mytarget-150320041428-conversion-gate01/85/C-myTarget-44-320.jpg)





Доклад Олега Царева касается использования социального графа пользователей платформы 'Одноклассники' для таргетированной рекламы через систему mytarget. Рассматриваются ключевые аспекты работы с графом, технические проблемы, требования к быстродействию и хранению данных, а также методы оптимизации вычислений для повышения эффективности сервиса. В результате предложено решение, которое обеспечивает быстрое извлечение данных с малым временем отклика и высоким уровнем нагрузки.


































































