Download to read offline





![Нет препятствий патриотам!
• Про скорость, древняя-древняя история
• Раз, vector<int> & res
• Два, vector<int> g_res + reserve() +20%
• Три, int[12] + int * res + MAGIC_EOF +40%
• Про память, понятная беда
• 8, 16, 32, 64, …, 512K, 1M, 2M, 4M, …
• reserve() заранее – спасает, но жрет память
• Политики resize – tradeoff RAM/CPU](https://image.slidesharecdn.com/8-140506052110-phpapp01/85/Sphinx-6-320.jpg)




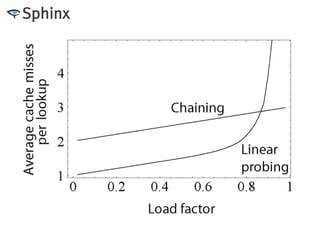
![Что такое хеш
• Задача, по ключу K найти значение V
• Влобное решение, перебор
• Быстрое решение, перебор / N
• Массив key2value[N]
• Хеш-функция F(K) = {0, …, N-1}
• V (ну или указатель) кладем в key2value[F(K)]
• Или в F(K)+1, +2, +3, …, или +1, +4, +9, +16…
• Fun fact, в этом вашем PHP массивов-то нет](https://image.slidesharecdn.com/8-140506052110-phpapp01/85/Sphinx-11-320.jpg)




![А как на самом деле?
• Напоминаю, 19075K лукапов
• Все функции... вредят, медленнее на 3-10%
• Кроме shift-mul-xor, вредит не сильно
• 106 mb/sec vs 108 mb/sec
• В принципе, понятно, почему
DWORD uHash = 0;
for ( int i=0; i<(iLen+3)>>2; i++ )
uHash ^=
((DWORD*)pData)[i] * 0x607cbb77UL;](https://image.slidesharecdn.com/8-140506052110-phpapp01/85/Sphinx-17-320.jpg)








![Хардкод или таблицы?
• Задача, быстро “промотать” некие
ненужные данные
• Sette, “совершенно очевидно, что…”
• while (…) p += skip_length_table[*p]
• switch это всякие JMP, а то целые CMP
• Таблица длин махонькая, отлично кешируется
• В других местах таблицы работают лучше
• И тут обязана быть лучше!](https://image.slidesharecdn.com/8-140506052110-phpapp01/85/Sphinx-26-320.jpg)




![Случайная история про read()
• Otto, “совершенно очевидно, что…”
• read() это лишнее копирование, медленно
• mmap() почитай прямой доступ, быстро
• А как на самом деле?
• Несколько лет, несколько попыток
• Ни разу не смогли измерить эффект, но вот!!!
• [the rarity]
• 10 msec, 1 msec, 0.1 msec](https://image.slidesharecdn.com/8-140506052110-phpapp01/85/Sphinx-31-320.jpg)












Документ содержит анализ производительности различных алгоритмов и структур данных, включая векторы и хеш-таблицы. Обсуждаются важные аспекты, такие как эффективность хранения и обработки данных, а также важность тестирования на практике. Основной вывод заключается в том, что распространенные представления о производительности, часто оказываются неверными.



































































