Downloaded 14 times



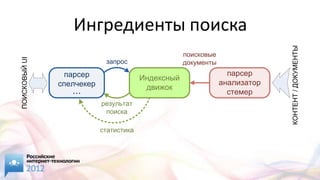








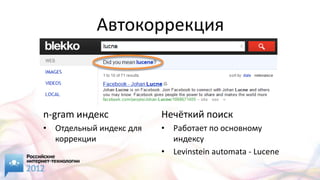
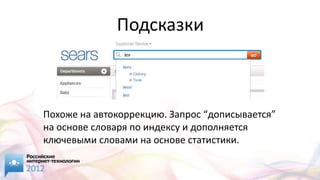




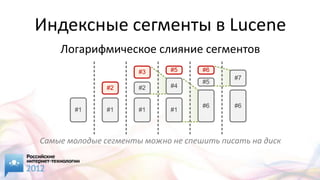









Документ представляет обзор различных open source решений для поиска на сайте, включая Elasticsearch, Solr и Sphinx, с акцентом на их функциональность и характеристики. Обсуждаются методы индексации, такие как инвертированный индекс и сегментированные индексы, а также важные аспекты поисковых запросов и их обработка. Упоминаются дополнительные функции, такие как автокоррекция, фасетная навигация и пространственный поиск, а также необходимость регулярной переиндексации для повышения производительности.















































