Download to read offline


![[0/4] Зачем это все?](https://image.slidesharecdn.com/rit2012-search-quality-120903051041-phpapp01/75/slide-3-2048.jpg)




![[1/4] Что такое
релевантность](https://image.slidesharecdn.com/rit2012-search-quality-120903051041-phpapp01/75/slide-8-2048.jpg)







![[battleship]](https://image.slidesharecdn.com/rit2012-search-quality-120903051041-phpapp01/75/slide-19-2048.jpg)




![[battle sheep]?](https://image.slidesharecdn.com/rit2012-search-quality-120903051041-phpapp01/75/slide-24-2048.jpg)























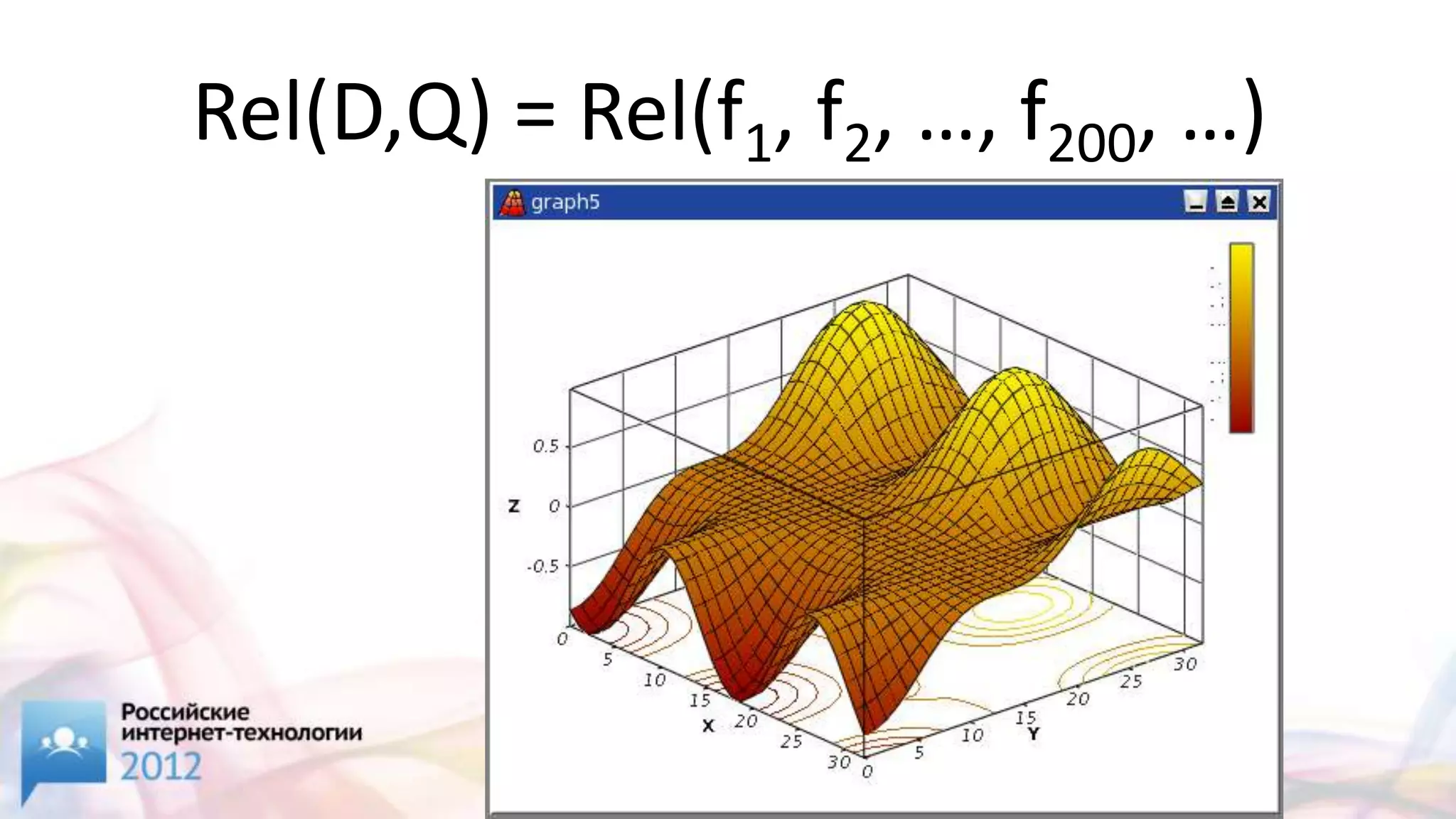





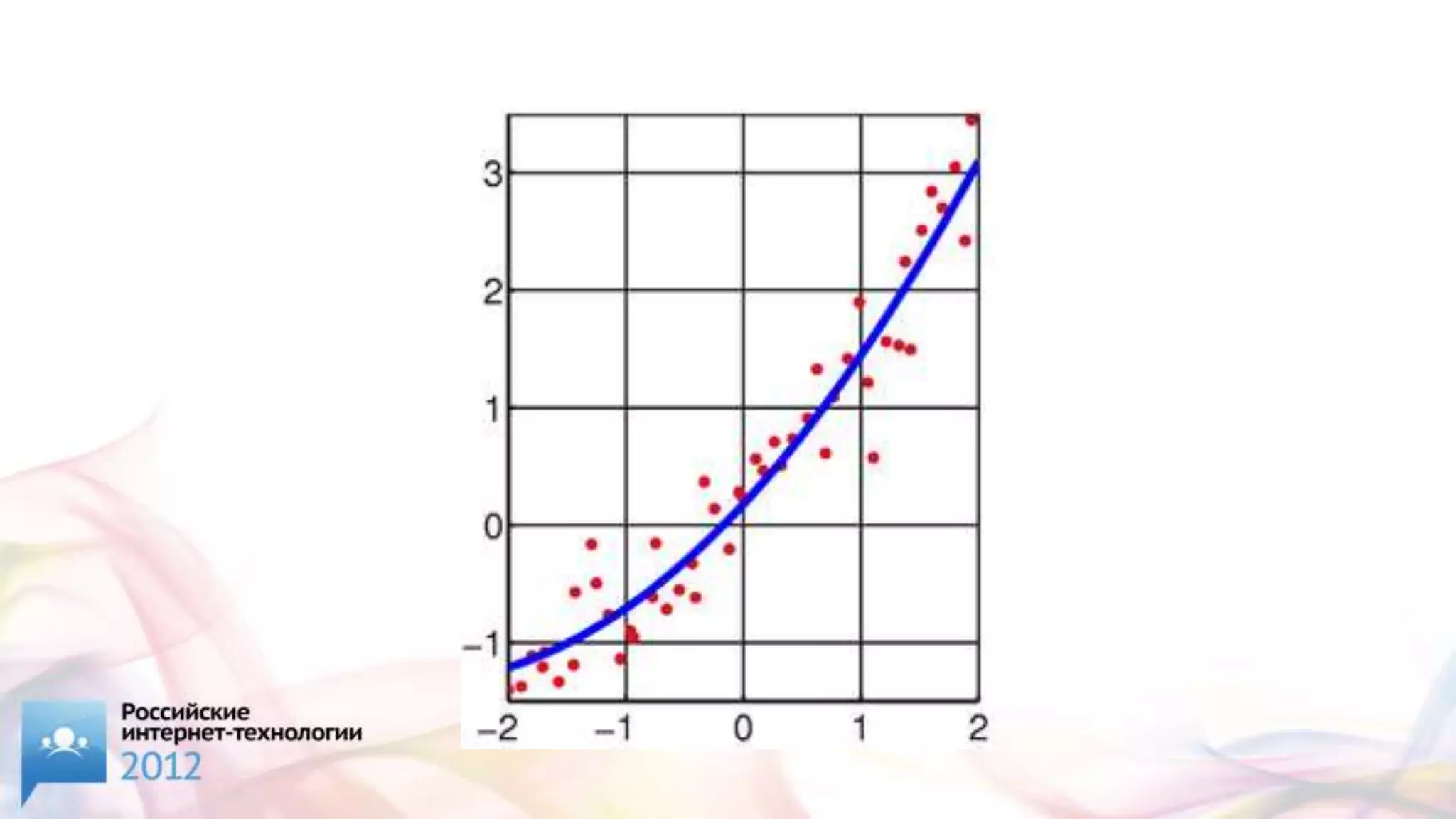




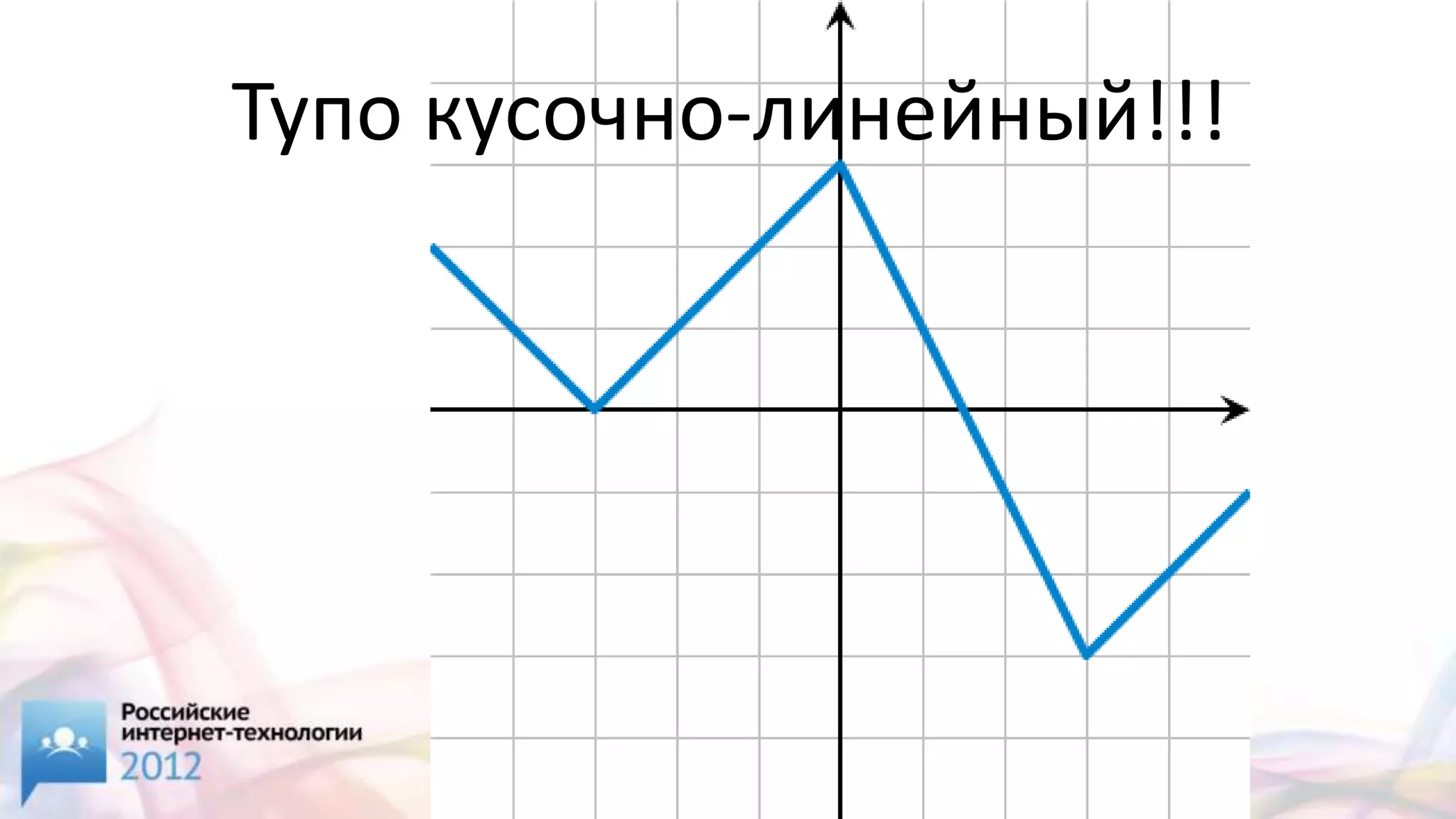






![[2/4] Sphinx,
ранкеры](https://image.slidesharecdn.com/rit2012-search-quality-120903051041-phpapp01/75/slide-66-2048.jpg)





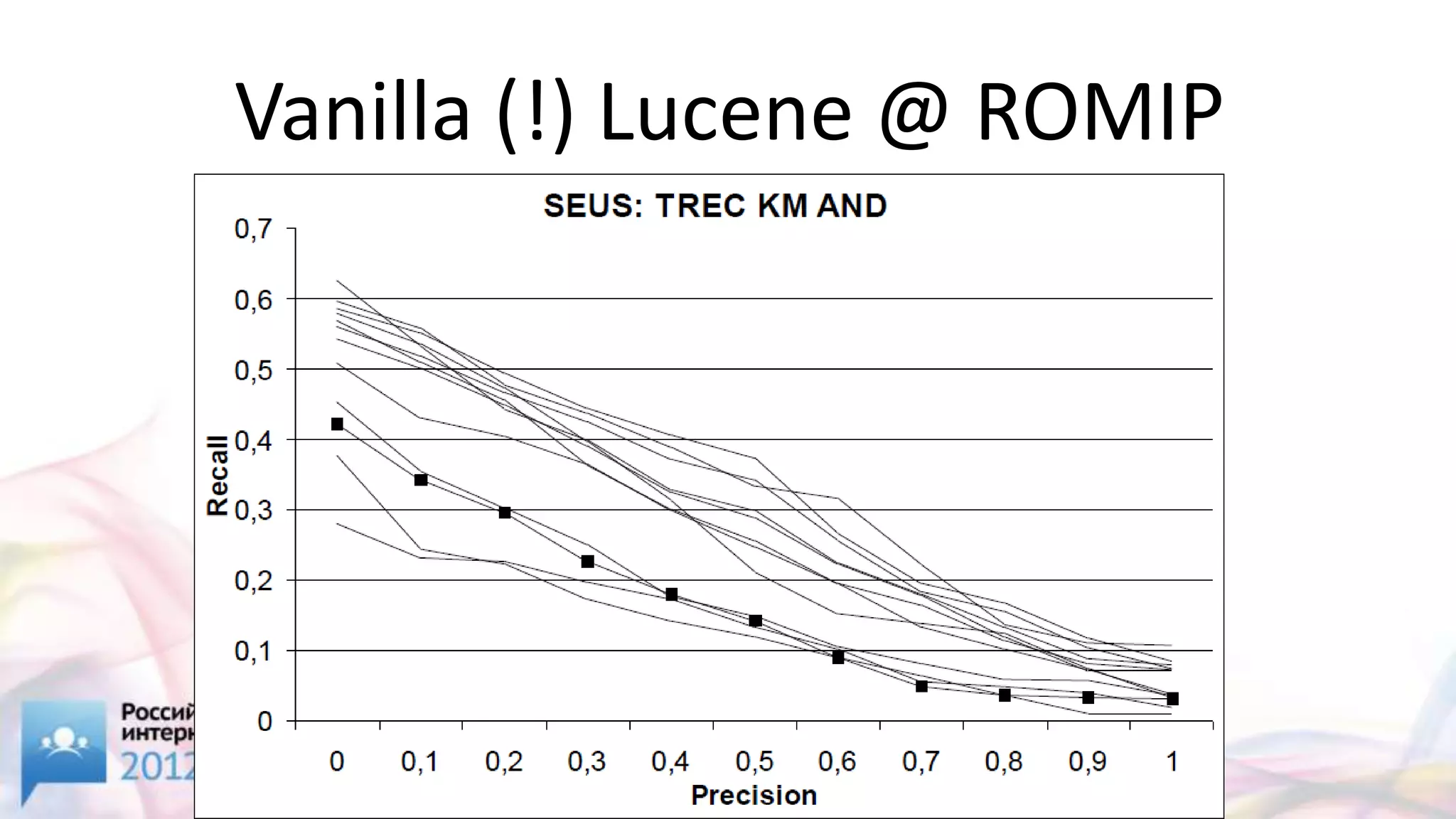



![[3/4] Sphinx,
expression ranker](https://image.slidesharecdn.com/rit2012-search-quality-120903051041-phpapp01/75/slide-76-2048.jpg)






![[4/4] “Низколетящие
фрукты”...](https://image.slidesharecdn.com/rit2012-search-quality-120903051041-phpapp01/75/slide-83-2048.jpg)
![[4/4] …или, что еще
можно сделать](https://image.slidesharecdn.com/rit2012-search-quality-120903051041-phpapp01/75/slide-84-2048.jpg)









Доклад посвящен вопросам релевантности в поисковых системах, в частности, в контексте Sphinx Technologies. Обсуждаются факторы, влияющие на ранжирование, методы оценки качества и необходимость машинного обучения для оптимизации метрик удовольствия пользователей. Доклад акцентирует внимание на субъективности оценок и предложениях по улучшению различных аспектов поиска, включая обработку опечаток и морфологии.






































