Download as PDF, PPTX




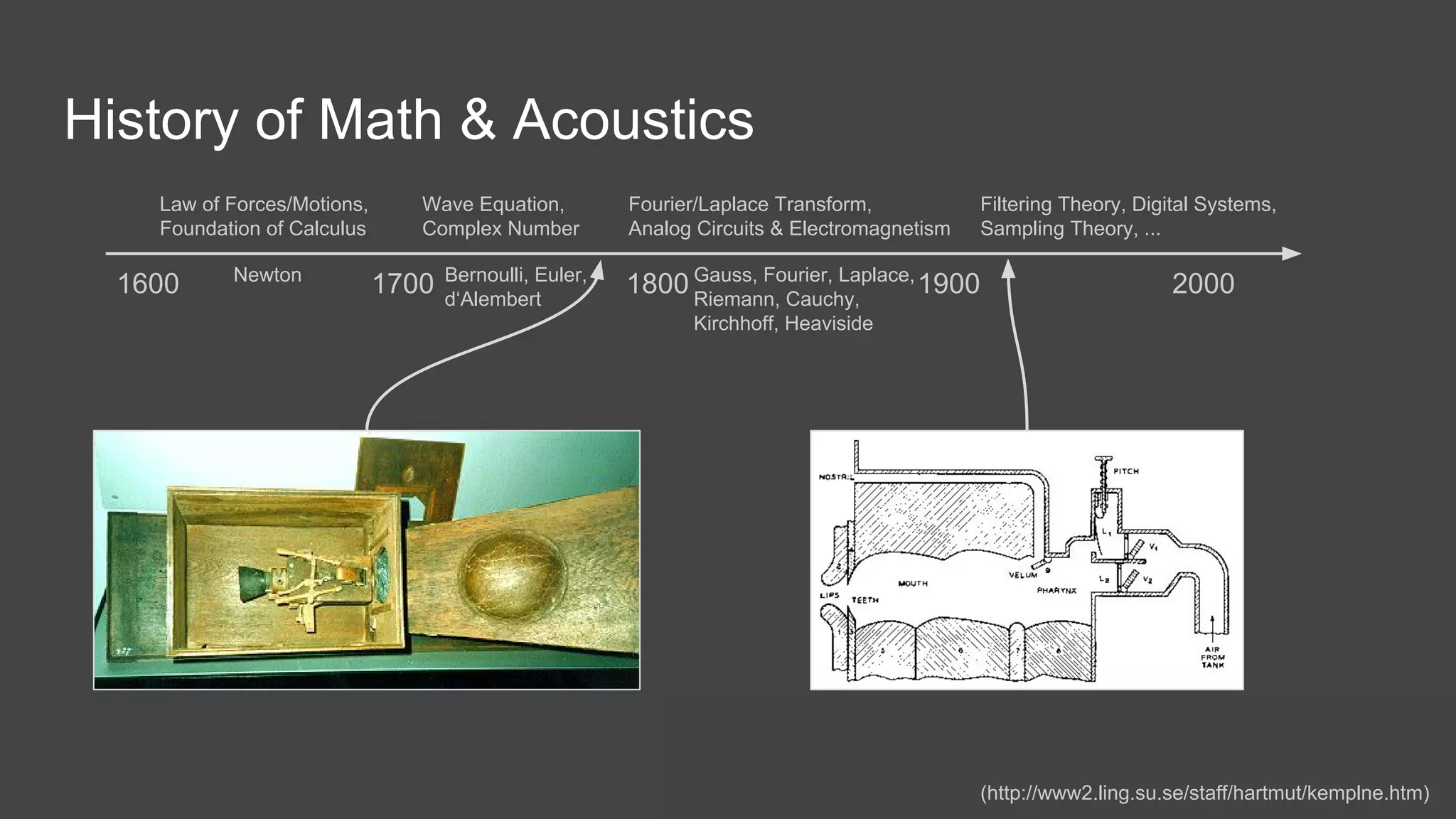






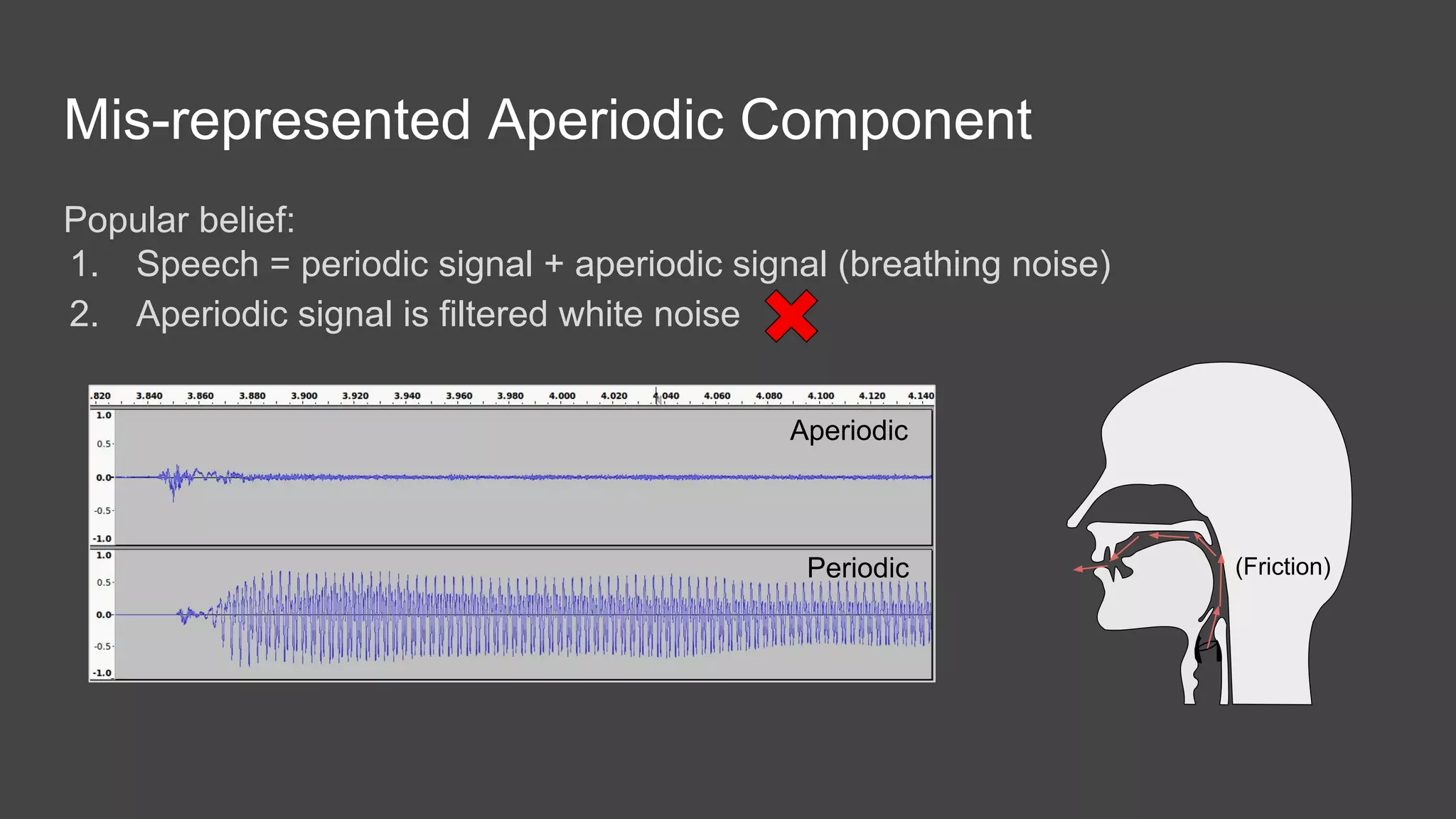




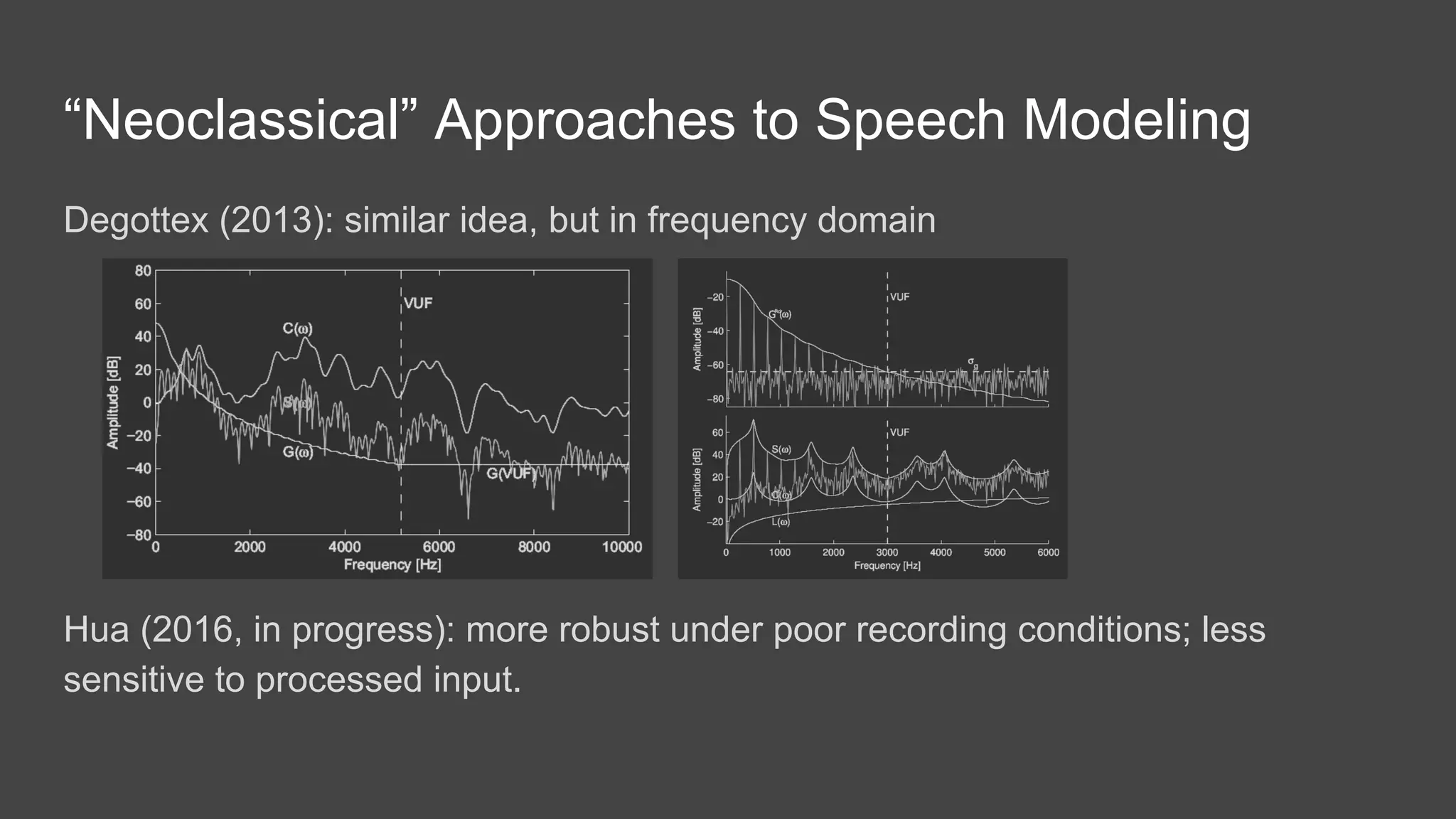
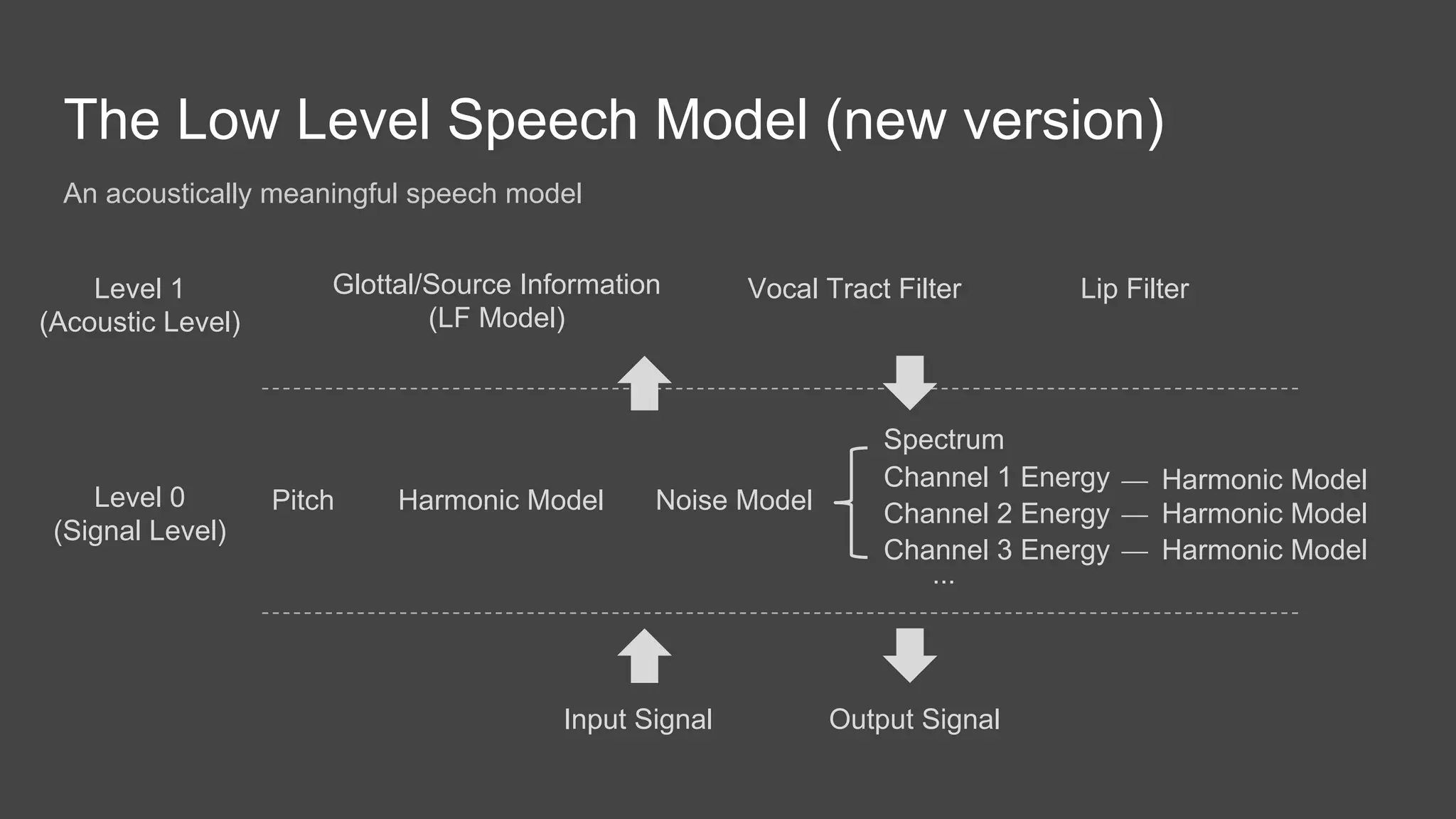





The document discusses the history and current state of speech and singing voice modeling. It addresses limitations in existing models, including the assumptions of quasi-static signals and oversimplified representations of aperiodic components. The author proposes a new "low level speech model" that models the harmonic, noise and transient components separately and incorporates a more accurate glottal/source model. This could enable applications like improved pitch shifting by revealing the instants of vocal fold closure. Overall, the document analyzes past approaches, outlines ongoing challenges, and presents a future direction of research toward a more robust low-level speech model.















































