Downloaded 91 times









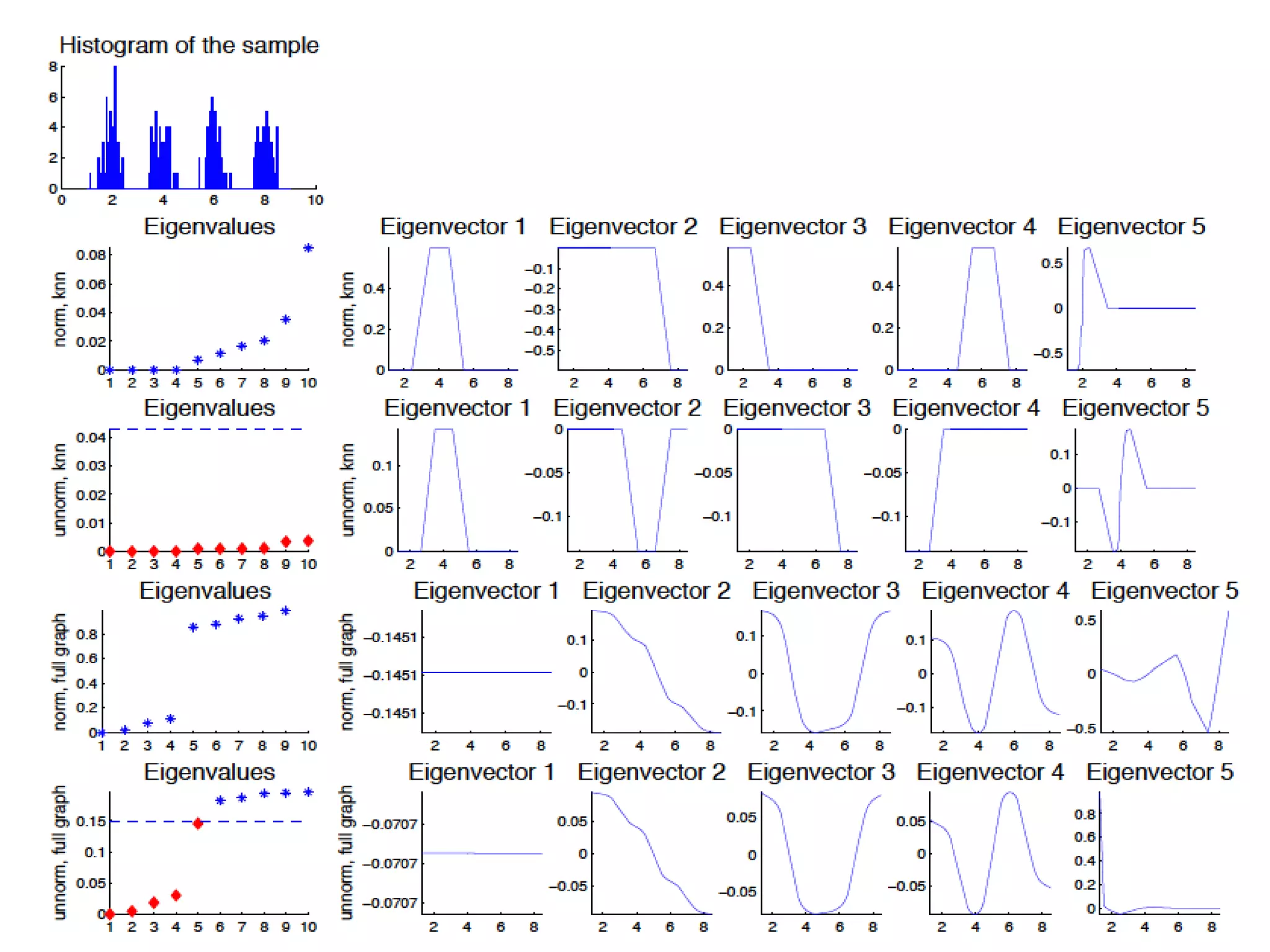







Spectral clustering works by creating an affinity matrix from a similarity matrix and then applying dimensionality reduction before clustering in the reduced space. It represents the data as an undirected graph and uses the graph Laplacian matrix to perform the dimensionality reduction. The number of clusters can be determined using the eigengap heuristic or by setting k equal to the logarithm of the number of data points. The Gaussian kernel is commonly used to create the affinity matrix from the similarity matrix.



































































