Download as PDF, PPTX





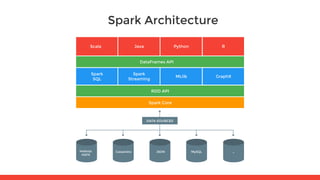












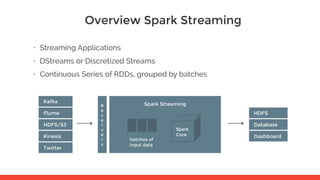




This document provides an overview of the Spark workshop agenda. It will introduce Big Data and Spark architecture, cover Resilient Distributed Datasets (RDDs) including transformations and actions on data using RDDs. It will also overview Spark SQL and DataFrames, Spark Streaming, and Spark architecture and cluster deployment. The workshop will be led by Juan Pedro Moreno and Fran Perez from 47Degrees and utilize the Spark workshop repository on GitHub.










































































