Downloaded 41 times



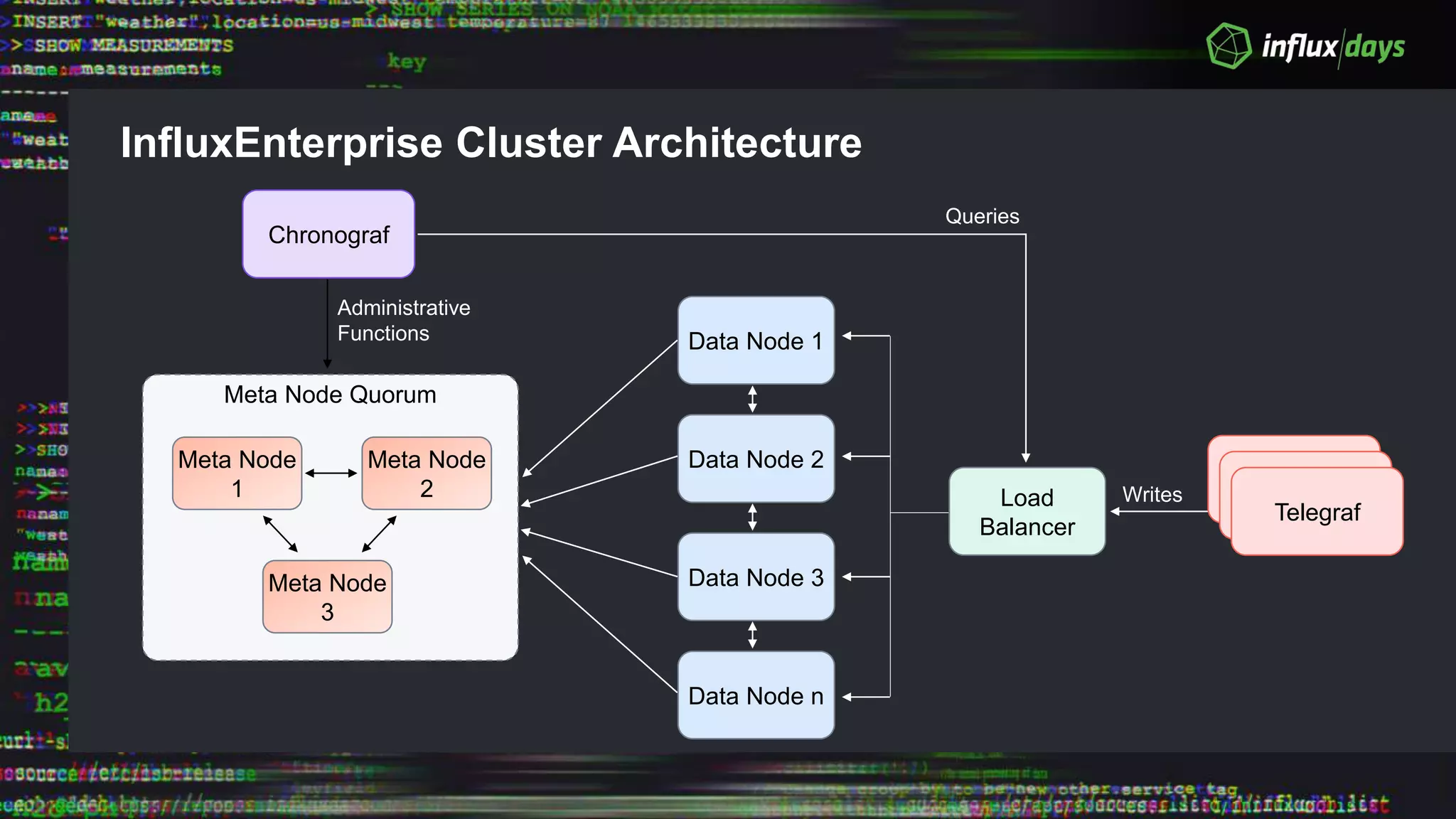
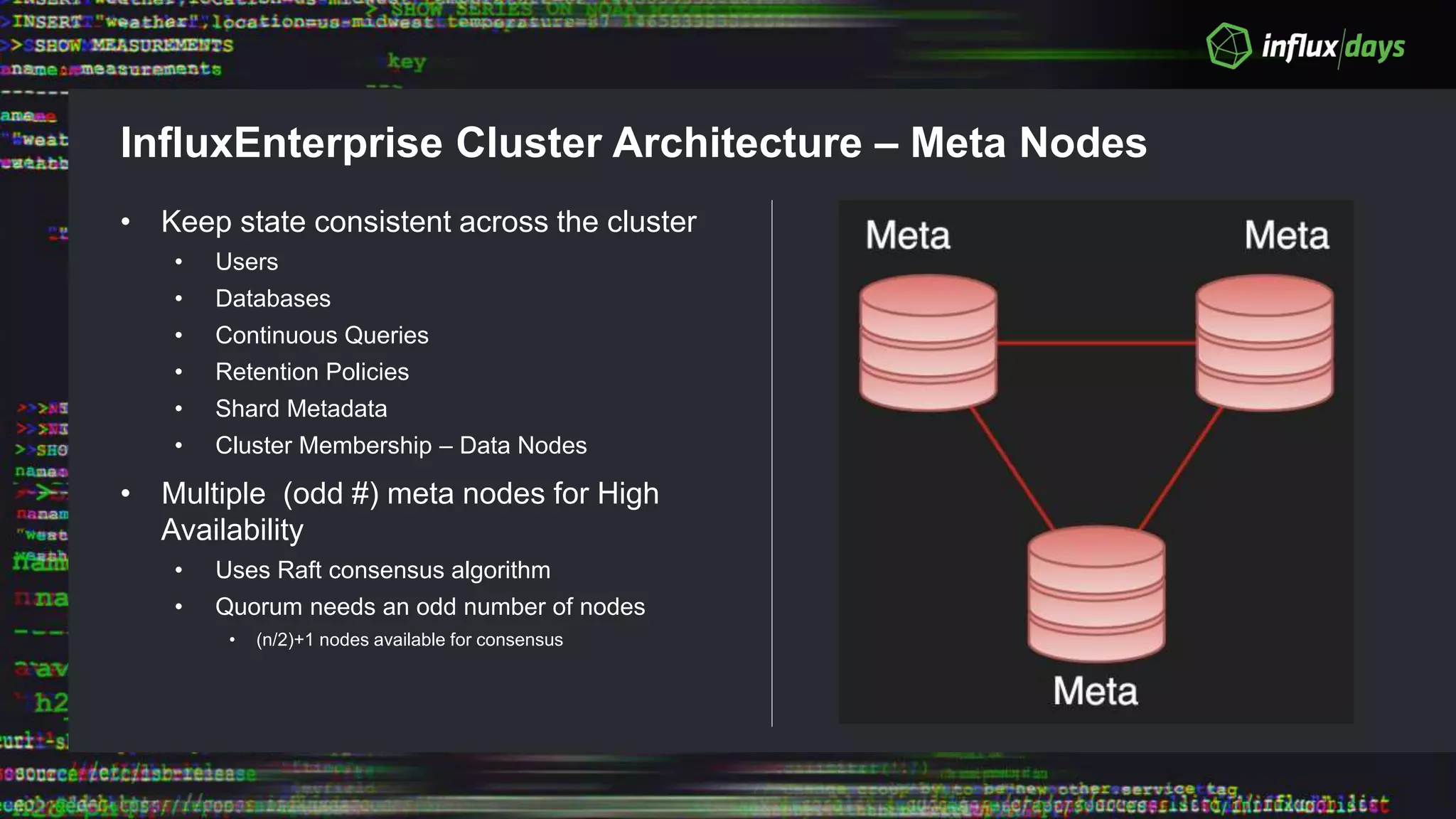
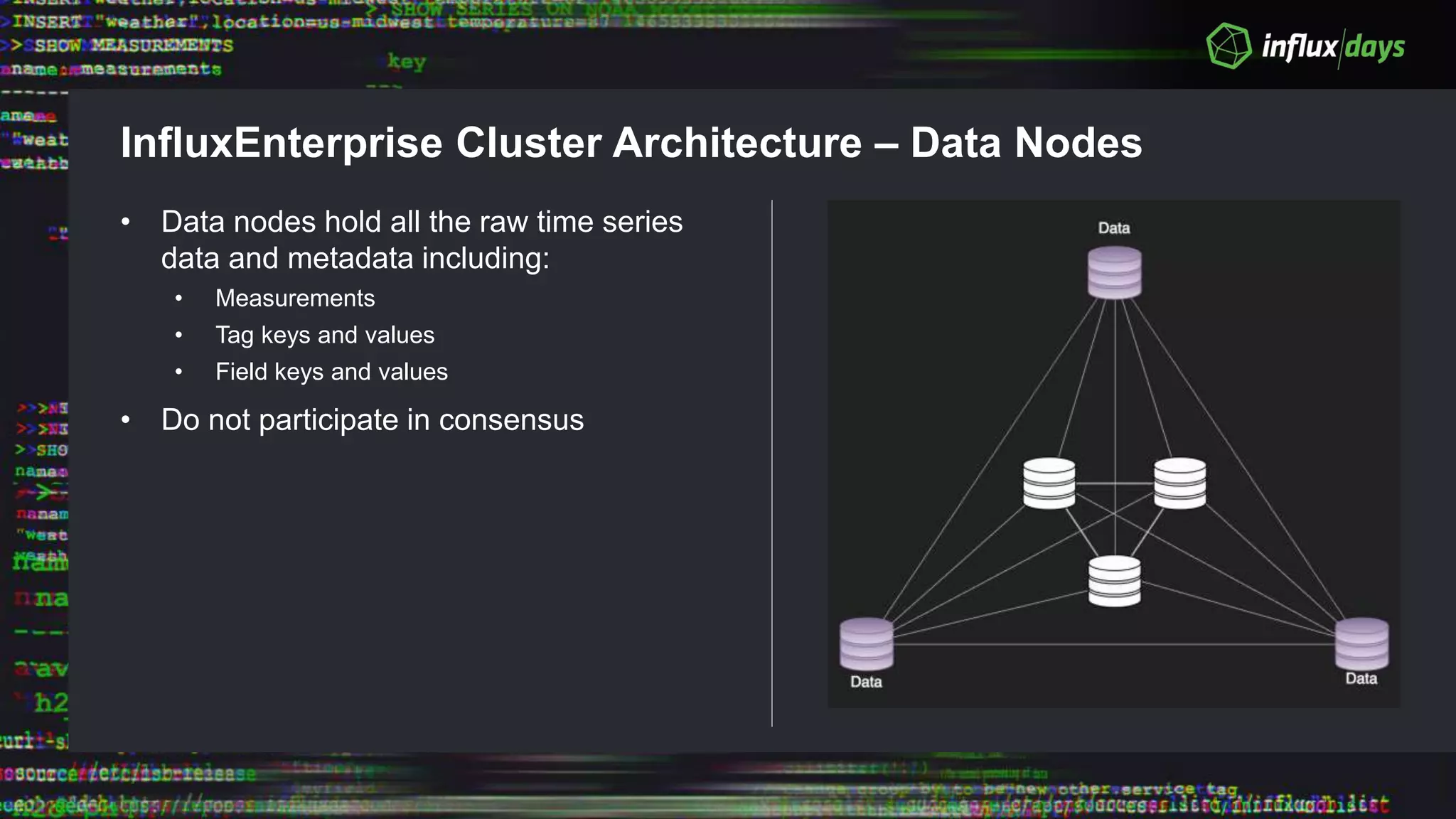
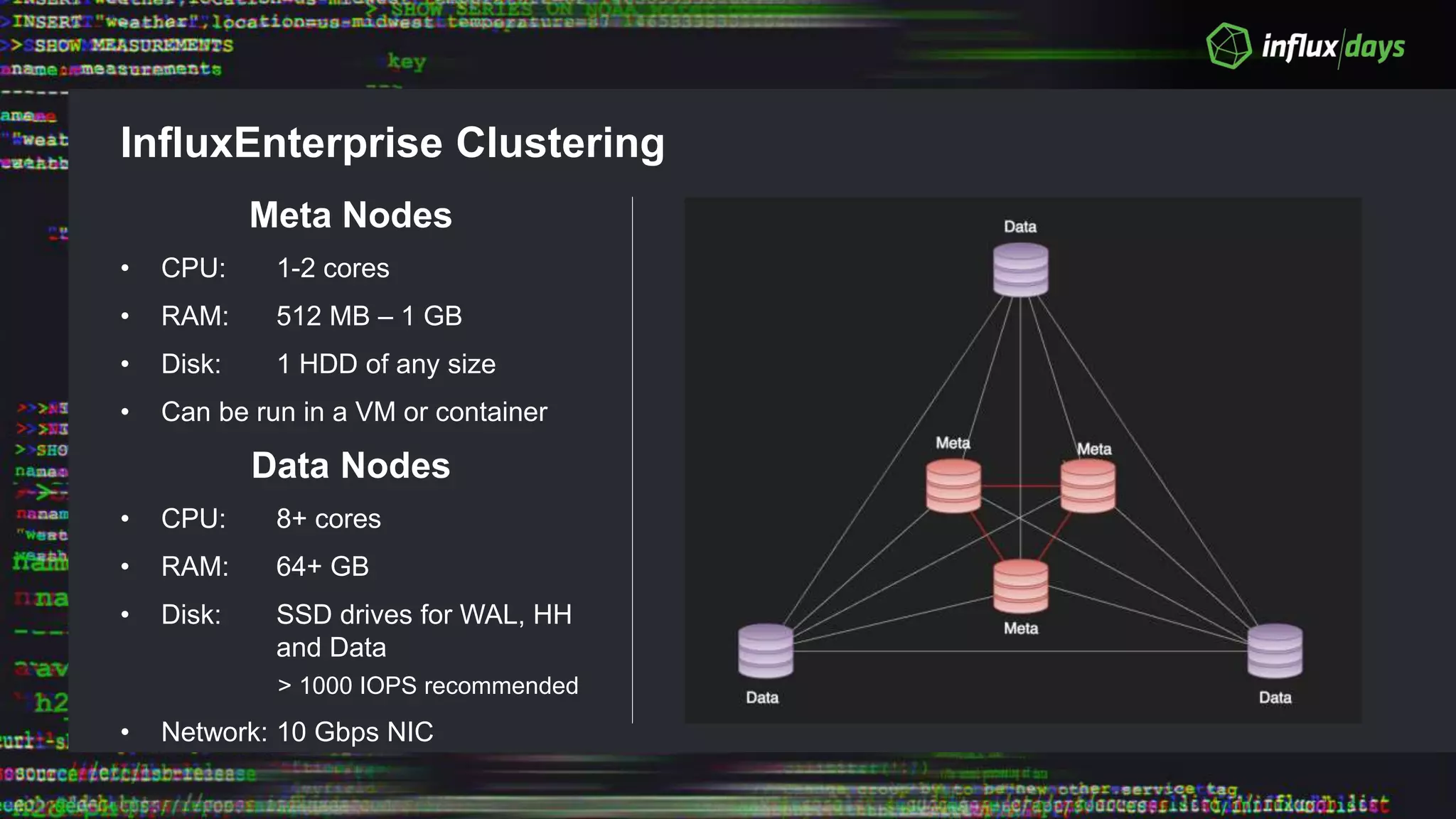
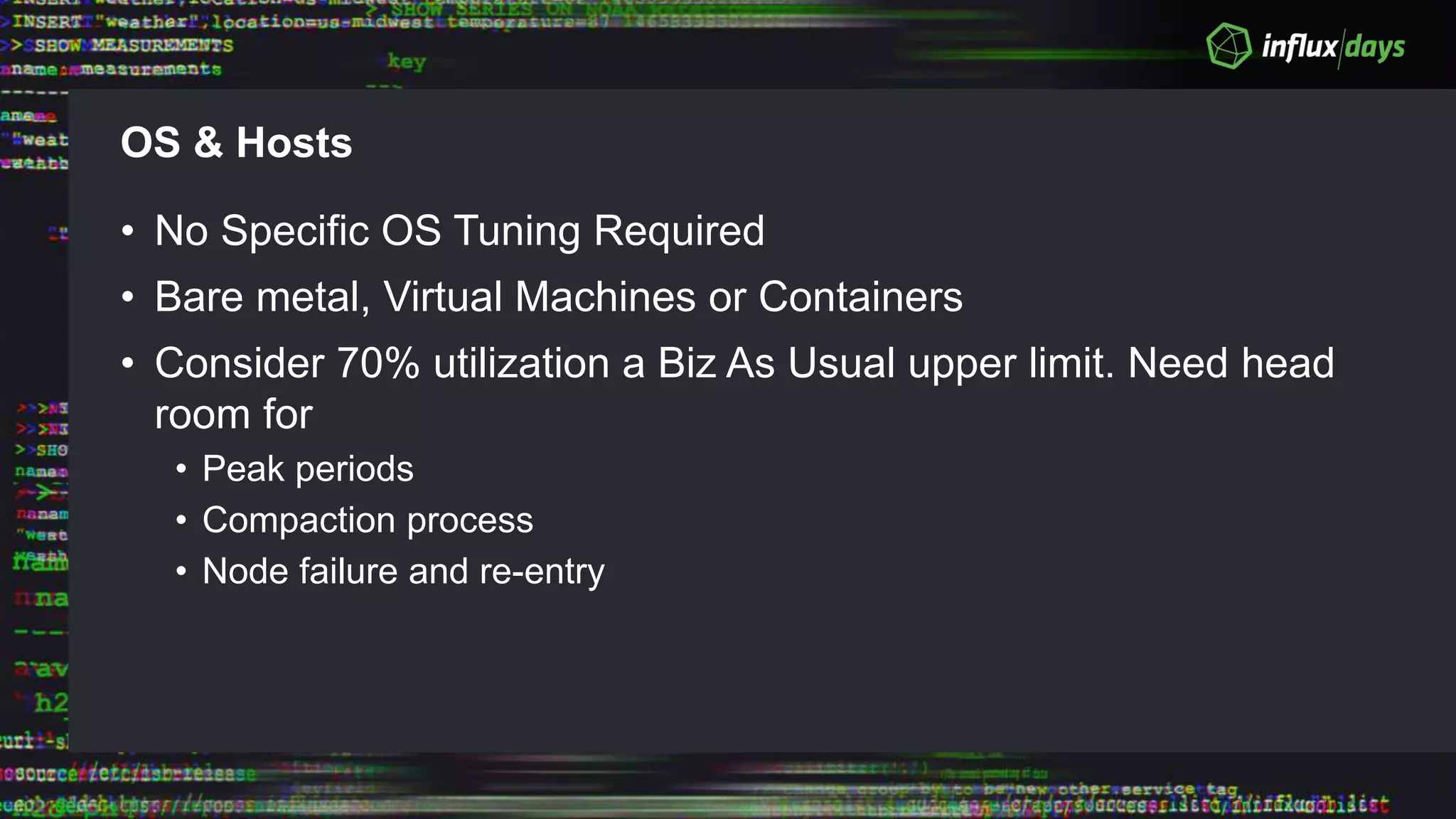



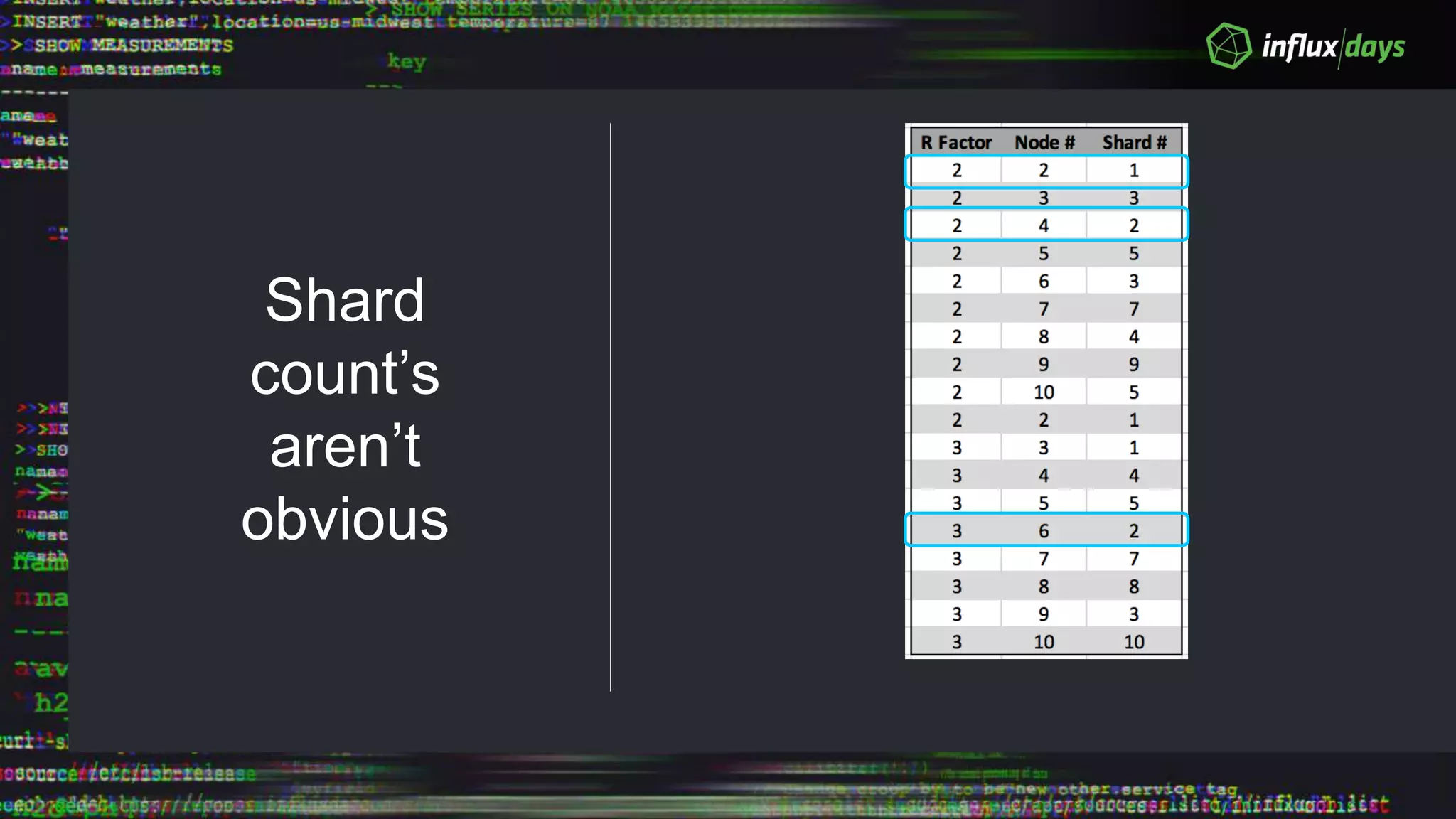


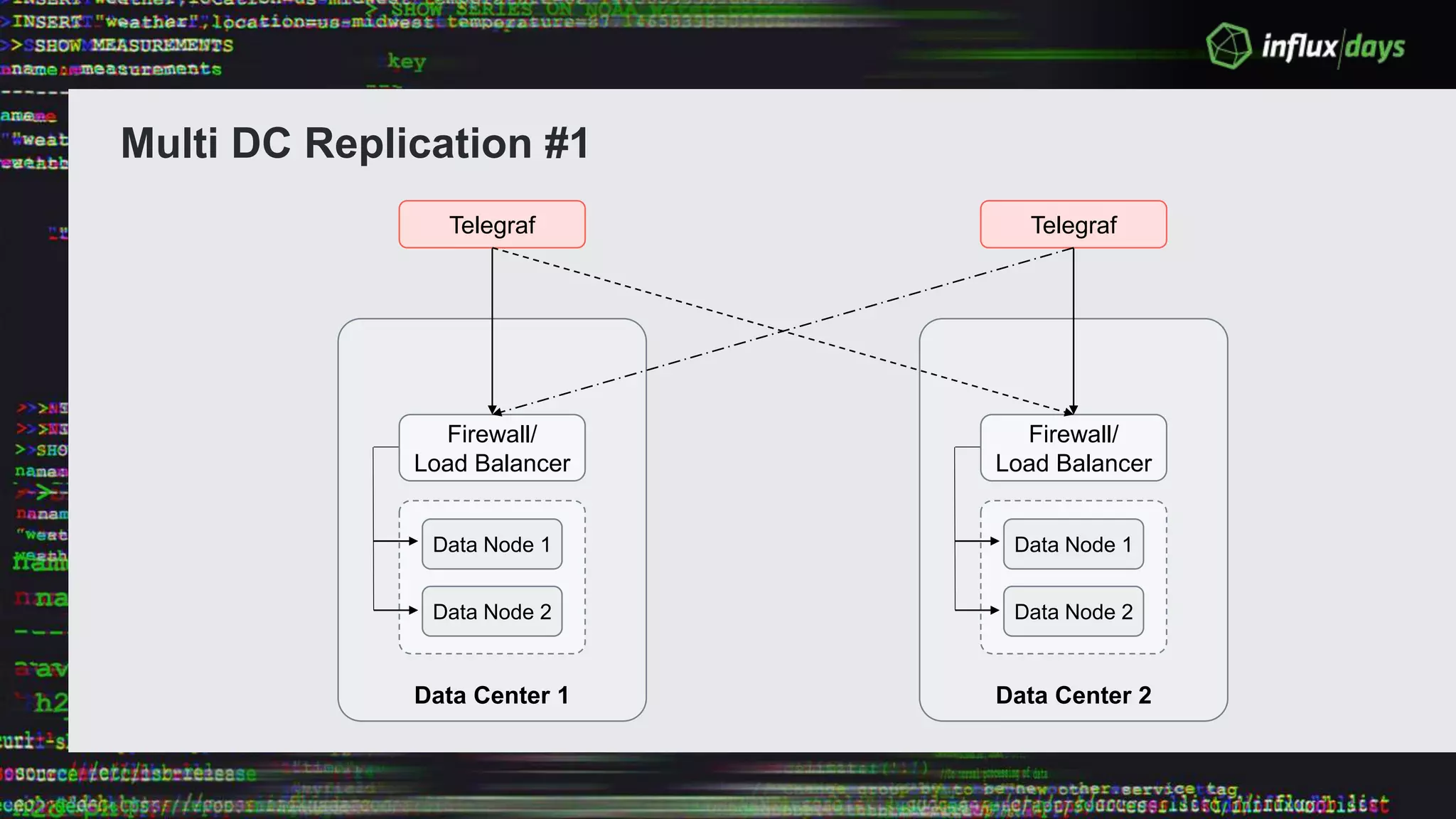
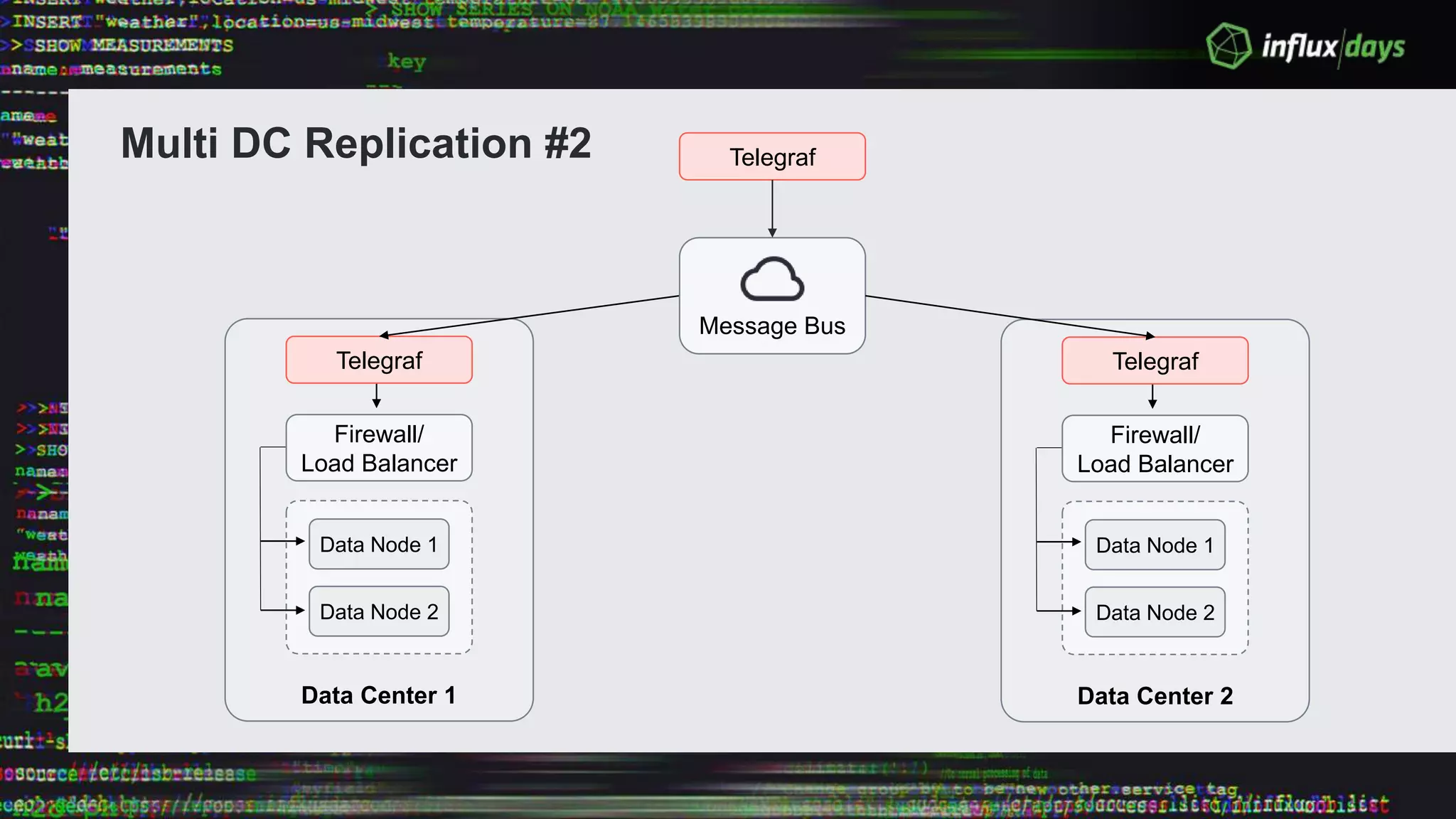
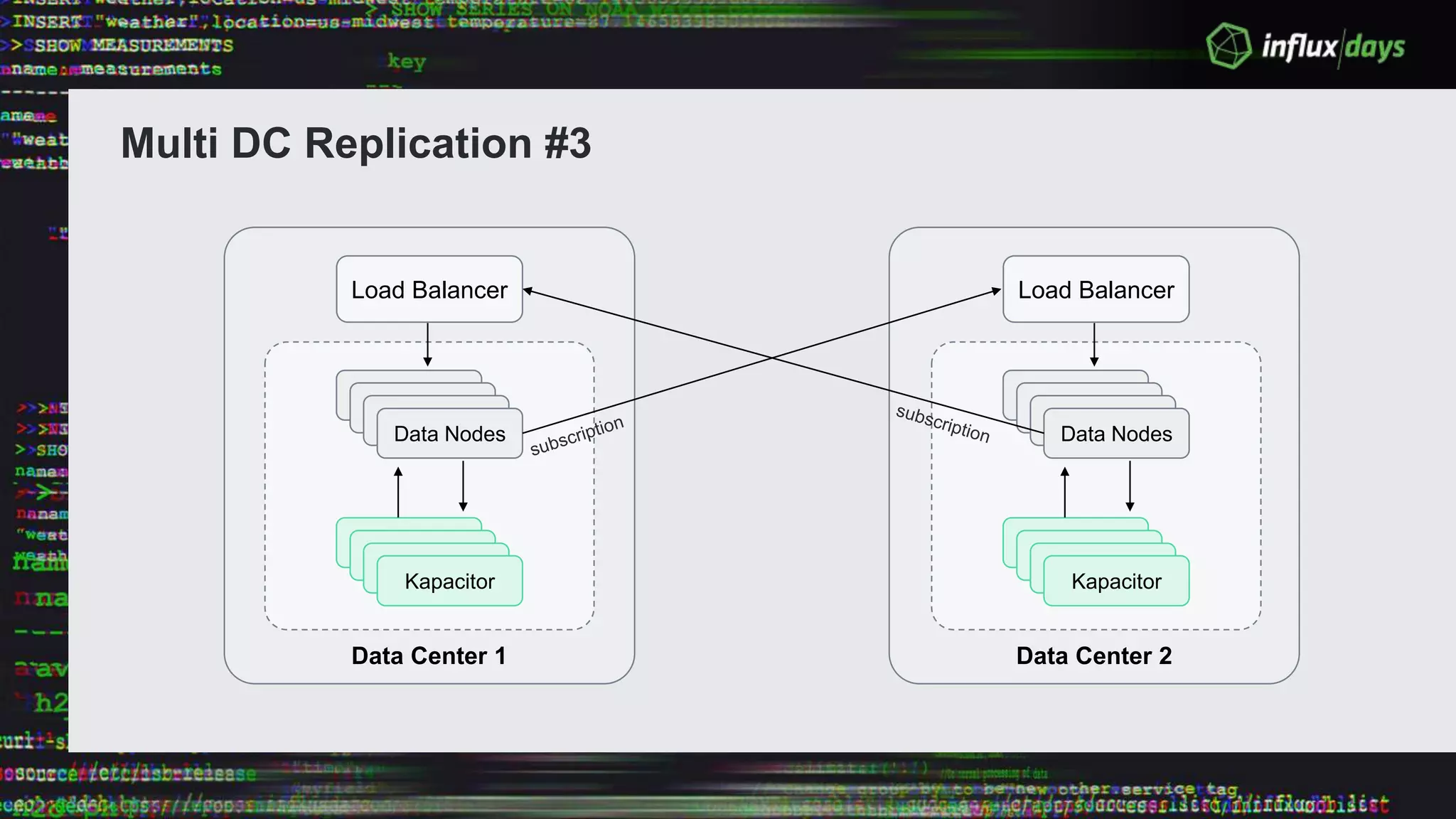
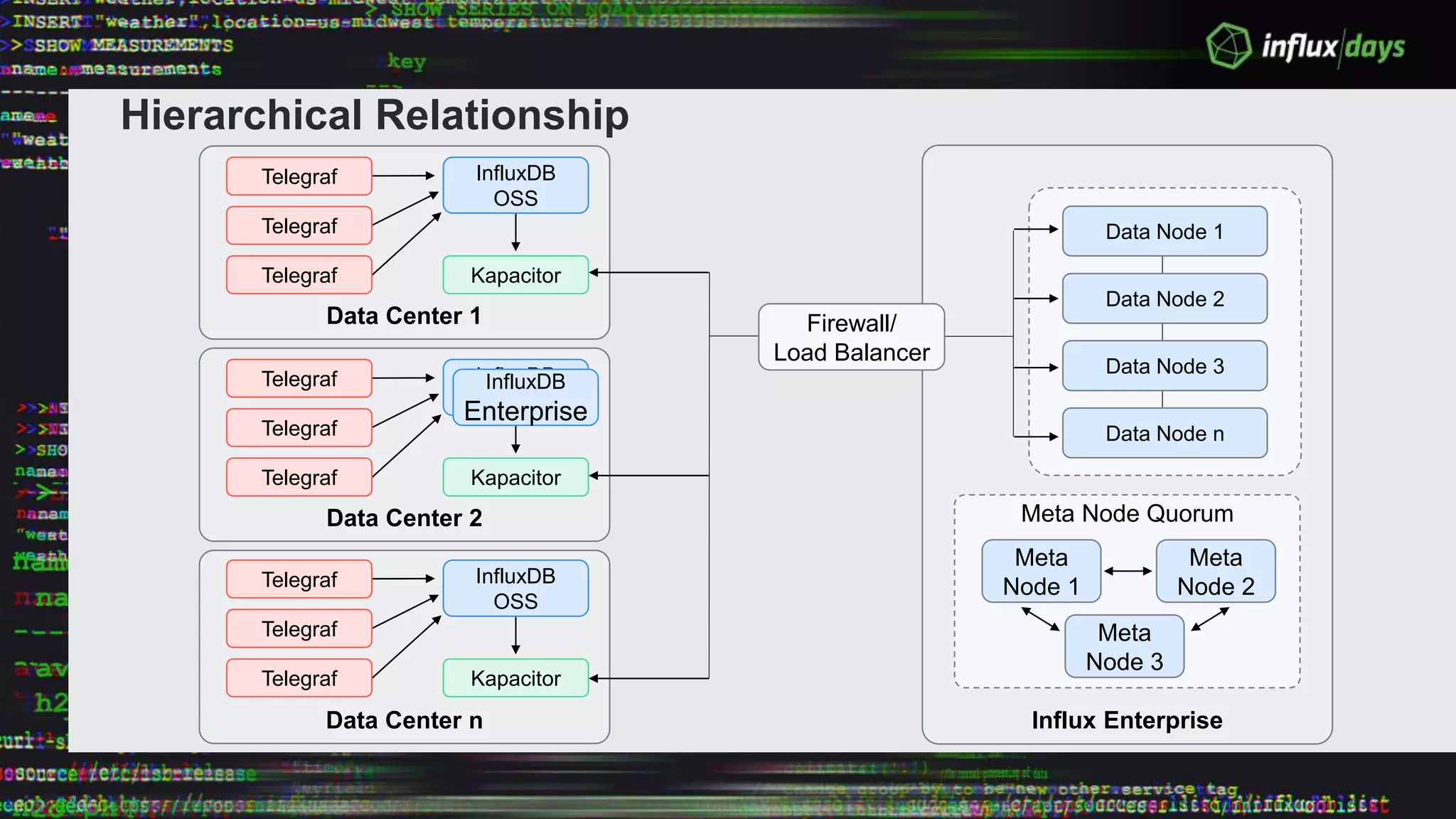
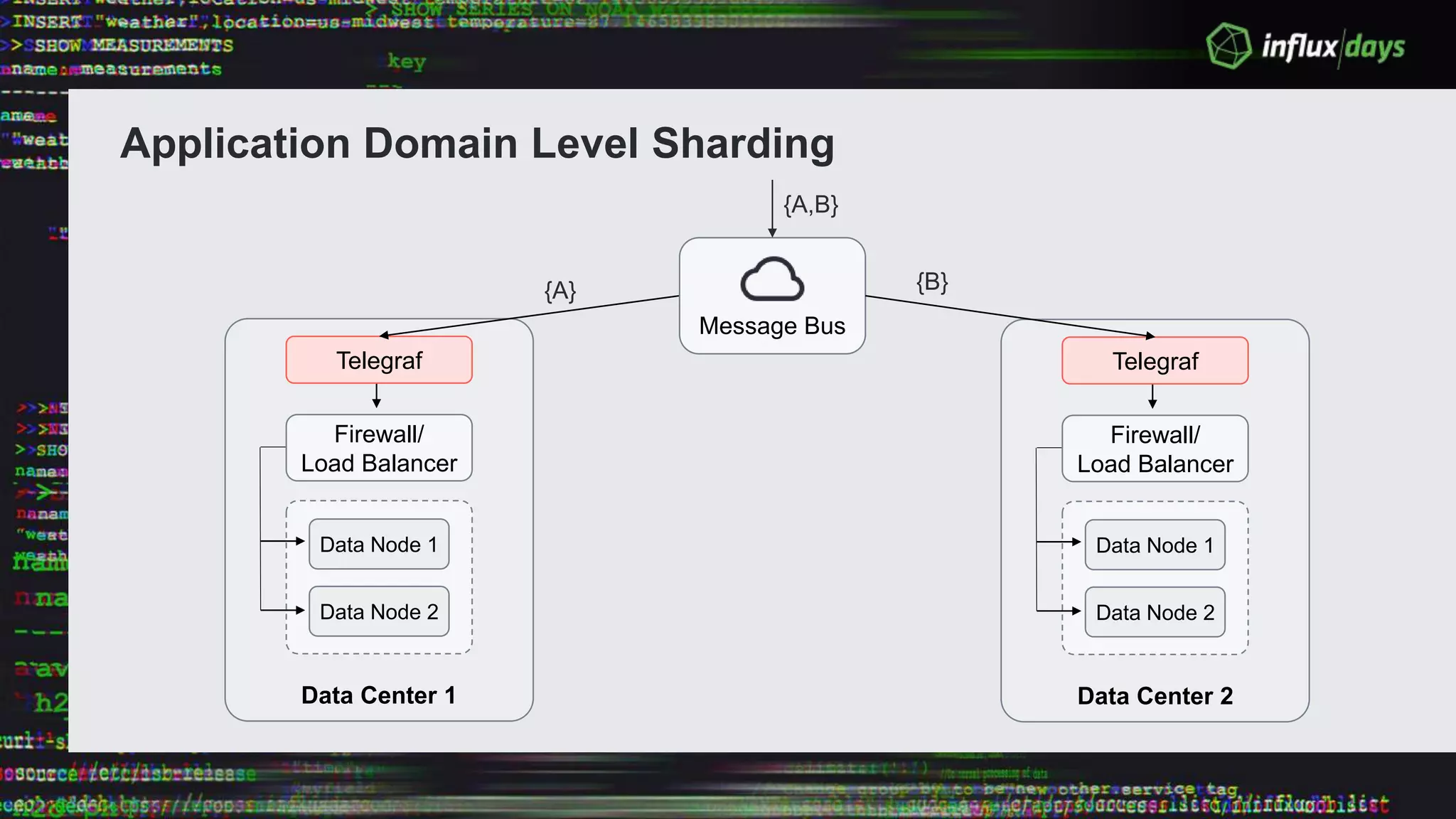
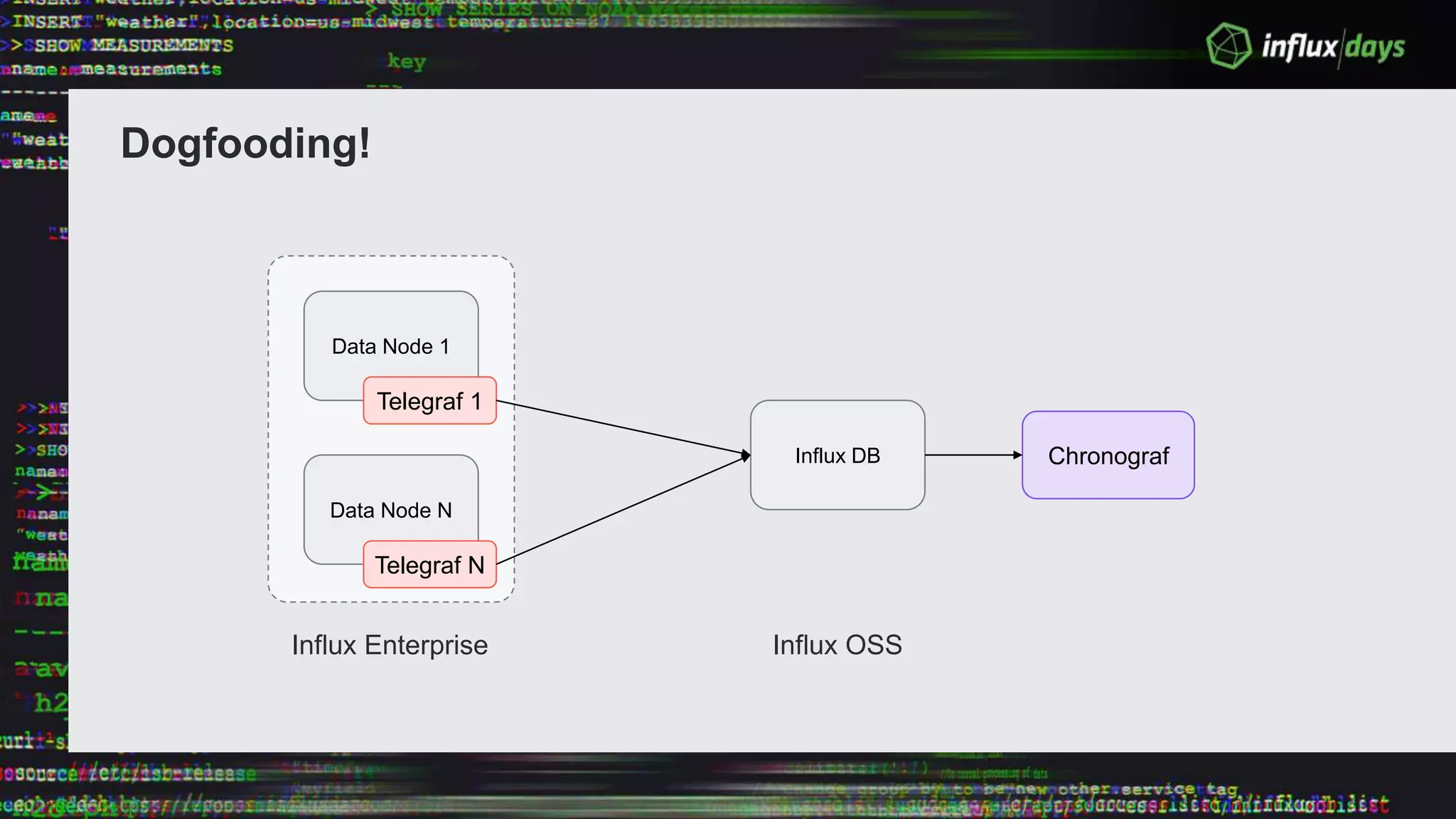

The document outlines the agenda for a workshop on the new practitioners track, including sessions on installing the Tick stack, writing queries, and optimizing InfluxEnterprise. It details the architecture of InfluxEnterprise clusters, including the roles of meta and data nodes, considerations for horizontal scalability, and deployment strategies across multiple data centers. Additionally, it discusses high availability measures and the importance of replication factors for data integrity.




































![Maksim Vazhenin [Dell Technologies] | InfluxDB for Storage System Monitoring ...](https://cdn.slidesharecdn.com/ss_thumbnails/influxdbforstoragesystemmonitoring-210430174441-thumbnail.jpg?width=640&height=640&fit=bounds)




![Michael Hall [InfluxData] | Become an InfluxDB Pro in 20 Minutes | InfluxDays...](https://cdn.slidesharecdn.com/ss_thumbnails/becomeaninfluxdbproin20minutesreviewed-221020212209-7ac7ea3f-thumbnail.jpg?width=640&height=640&fit=bounds)

![Charles Mahler [InfluxData] | Use Case: Networking Monitoring | InfluxDays 2022](https://cdn.slidesharecdn.com/ss_thumbnails/networkmonitoringusecaseoverviewcharles-221020212537-fda46bca-thumbnail.jpg?width=640&height=640&fit=bounds)



![Gilmore, Palani [InfluxData] | Use Case: Monitoring / Observability | InfluxD...](https://cdn.slidesharecdn.com/ss_thumbnails/usecasemonitoringobservabilityreviewed-221020212958-9acef1d5-thumbnail.jpg?width=640&height=640&fit=bounds)
![Ward Bowman [PTC] | ThingWorx Long-Term Data Storage with InfluxDB | InfluxDa...](https://cdn.slidesharecdn.com/ss_thumbnails/influxdays-221027185325-5d2f430b-thumbnail.jpg?width=640&height=640&fit=bounds)















![Steinkamp, Clifford [InfluxData] | Welcome to InfluxDays 2022 - Day 2 | Influ...](https://cdn.slidesharecdn.com/ss_thumbnails/influxdays2022welcometoday2-221020215815-c8463942-thumbnail.jpg?width=640&height=640&fit=bounds)
![Steinkamp, Clifford [InfluxData] | Closing Thoughts Day 1 | InfluxDays 2022](https://cdn.slidesharecdn.com/ss_thumbnails/influxdays2022closingthoughtsday1-221020215301-f8040e1f-thumbnail.jpg?width=640&height=640&fit=bounds)
![Steinkamp, Clifford [InfluxData] | Closing Thoughts | InfluxDays 2022](https://cdn.slidesharecdn.com/ss_thumbnails/influxdays2022closingthoughtsday2-221020220104-abde55ea-thumbnail.jpg?width=640&height=640&fit=bounds)
![Scott Anderson [InfluxData] | New & Upcoming Flux Features | InfluxDays 2022](https://cdn.slidesharecdn.com/ss_thumbnails/influxdays2022-fluxupdates-scott-221021210238-9d323cba-thumbnail.jpg?width=640&height=640&fit=bounds)



















