Downloaded 18 times













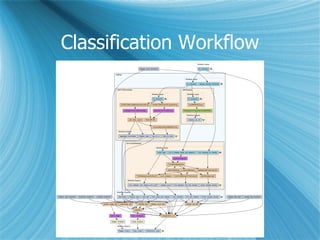






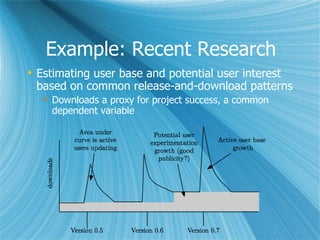
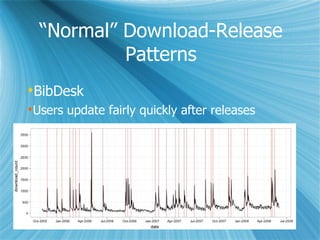
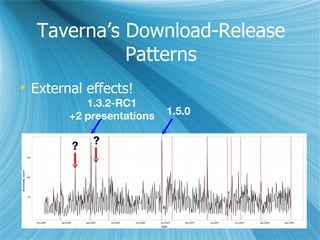



This document discusses a project on collaborative data analysis using Taverna workflows to replicate and extend prior research on free/libre open source software (FLOSS). It outlines the approach to utilizing various shared data sources, the design of workflows, and the strategies for ensuring effective collaboration among contributors with diverse skill sets. The authors emphasize the importance of transparency, modularity, and tool usability while addressing challenges in data handling and interdisciplinary collaboration.























































































