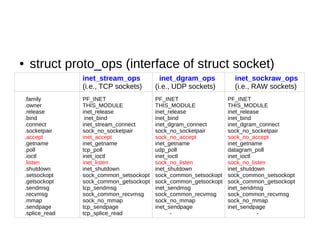
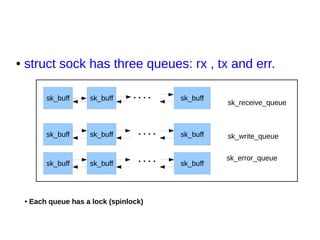
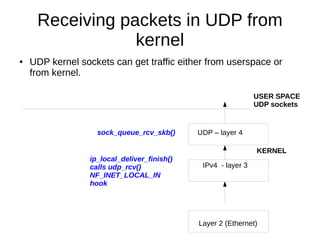
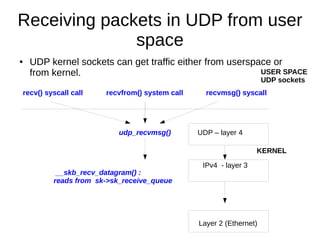
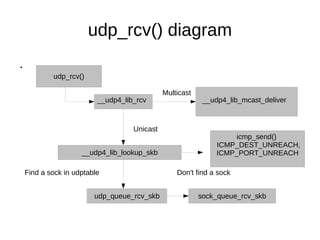
This document provides an overview of sockets in the Linux kernel networking stack. It discusses the socket() system call and how it relates to struct socket and struct sock in the kernel. It covers the different socket types like SOCK_STREAM and SOCK_DGRAM. UDP protocol is explained in detail along with how packets are received via udp_rcv() in the kernel from both userspace and other kernel components. Control messages and UDP errors are also briefly mentioned.







































![Example – udp client
#include <stdio.h>
#include <arpa/inet.h>
#include <sys/socket.h>
#include <string.h>
int main()
{
int s;
struct sockaddr_in target;
int res;
char buf[10];](https://image.slidesharecdn.com/netlec5-221214064510-4ca627a3/85/netLec5-pdf-44-320.jpg)











![● Then, we should add a call to a method like this
for receiving error messages:
int recv_err(int s)
{
int res;
char cbuf[512];
struct iovec iov;
struct msghdr msg;
struct cmsghdr *cmsg;
struct sock_extended_err *e;
struct icmphdr icmph;
struct sockaddr_in target;](https://image.slidesharecdn.com/netlec5-221214064510-4ca627a3/85/netLec5-pdf-57-320.jpg)




























![char rspace[3+4*NROUTES+1];
char buf[10];
target.sin_family = AF_INET;
target.sin_port=htons(999);
inet_aton("194.90.1.5",&target.sin_addr);
strcpy(buf,"message 1:");
s = socket(AF_INET, SOCK_DGRAM, 0);
if (s<0)
perror("socket");
memset(rspace, 0, sizeof(rspace));
rspace[0] = IPOPT_NOP;
rspace[1+IPOPT_OPTVAL] = IPOPT_RR;
rspace[1+IPOPT_OLEN] = sizeof(rspace)-1;](https://image.slidesharecdn.com/netlec5-221214064510-4ca627a3/85/netLec5-pdf-86-320.jpg)
![rspace[1+IPOPT_OFFSET] = IPOPT_MINOFF;
optlen=40;
if (setsockopt(s, IPPROTO_IP, IP_OPTIONS, rspace,
sizeof(rspace))<0)
{
perror("record routen");
exit(2);
}](https://image.slidesharecdn.com/netlec5-221214064510-4ca627a3/85/netLec5-pdf-87-320.jpg)









![Tips
● To find out socket used by a process:
● ls -l /proc/[pid]/fd|grep socket|cut -d: -f3|sed 's/[//;s/]//'
● The number returned is the inode number of the socket.
● Information about these sockets can be obtained from
– netstat -ae
● After starting a process which creates a socket, you can see
that the inode cache was incremented by one by:
● more /proc/slabinfo | grep sock
● sock_inode_cache 476 485 768 5 1 : tunables 0 0
0 : slabdata 97 97 0
● The first number, 476, is the number of active objects.](https://image.slidesharecdn.com/netlec5-221214064510-4ca627a3/85/netLec5-pdf-97-320.jpg)




































































