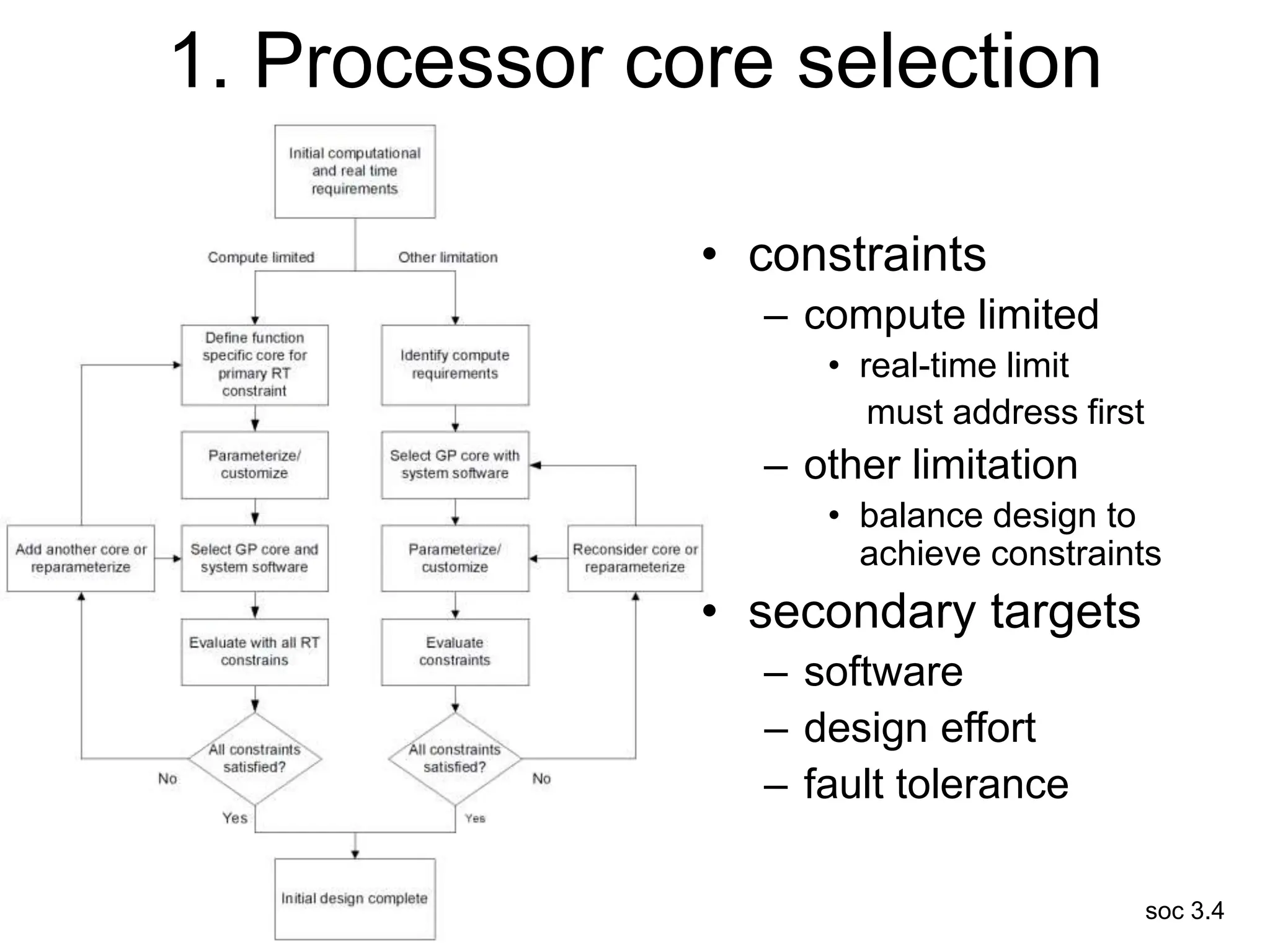
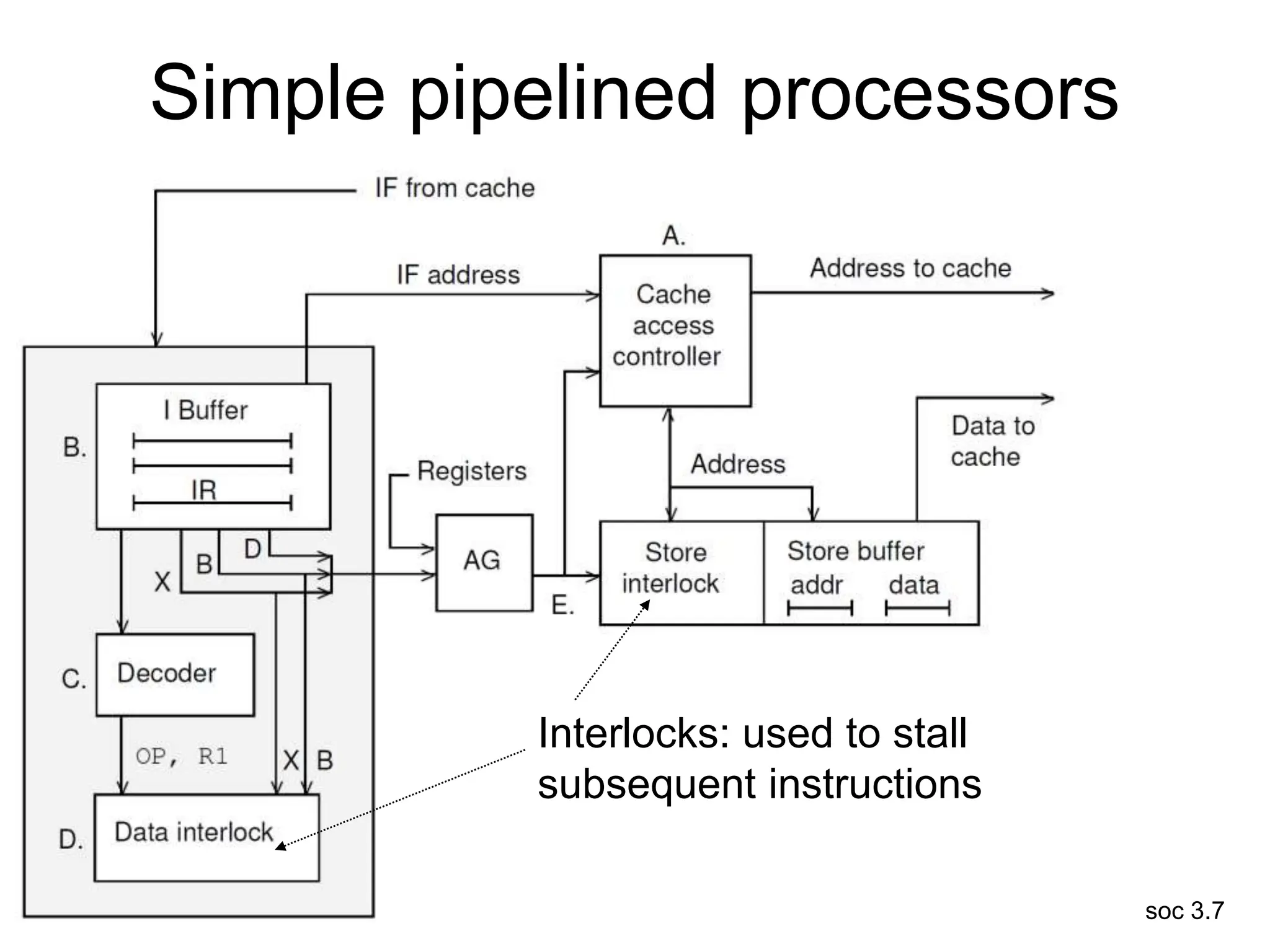
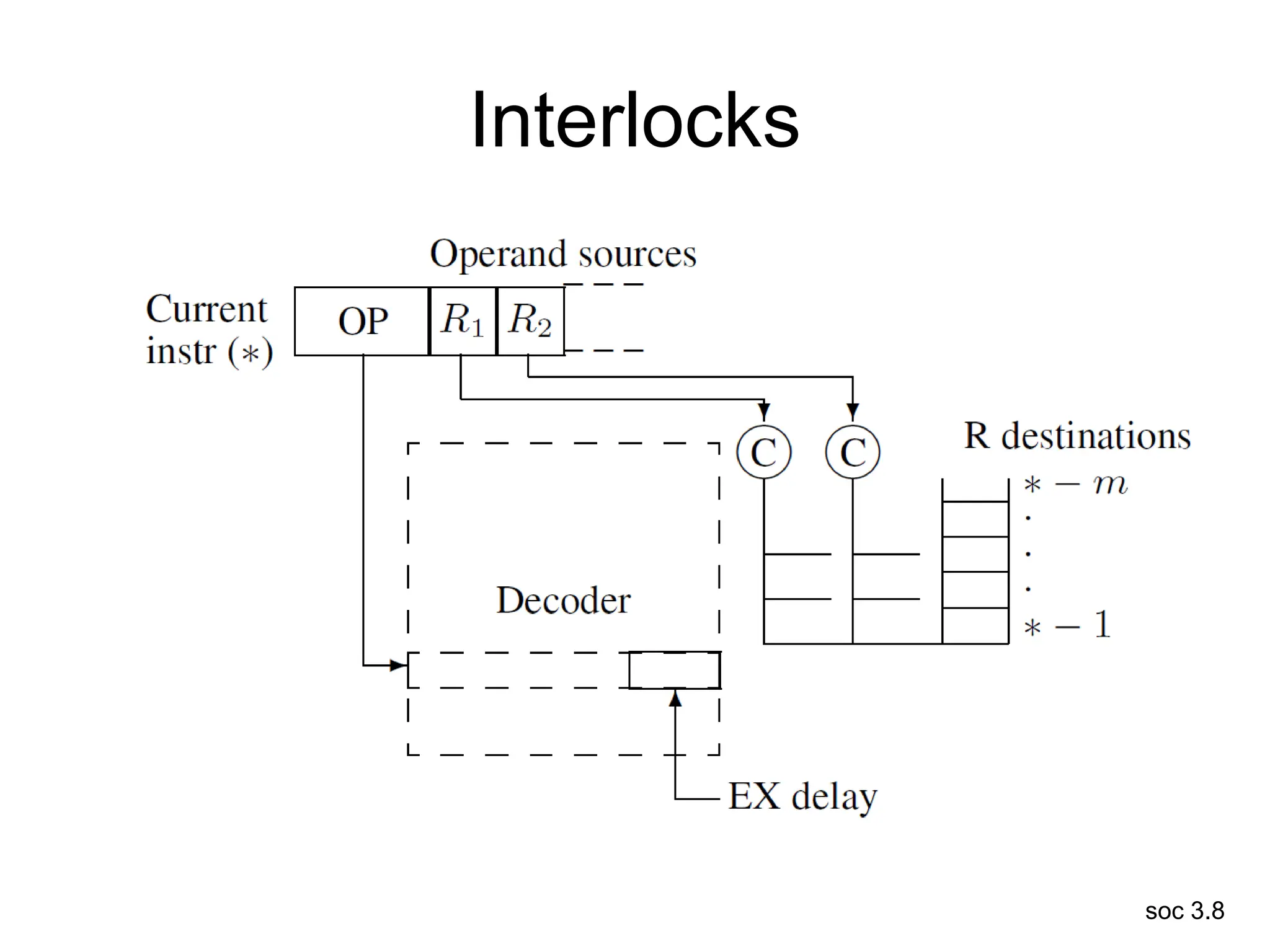
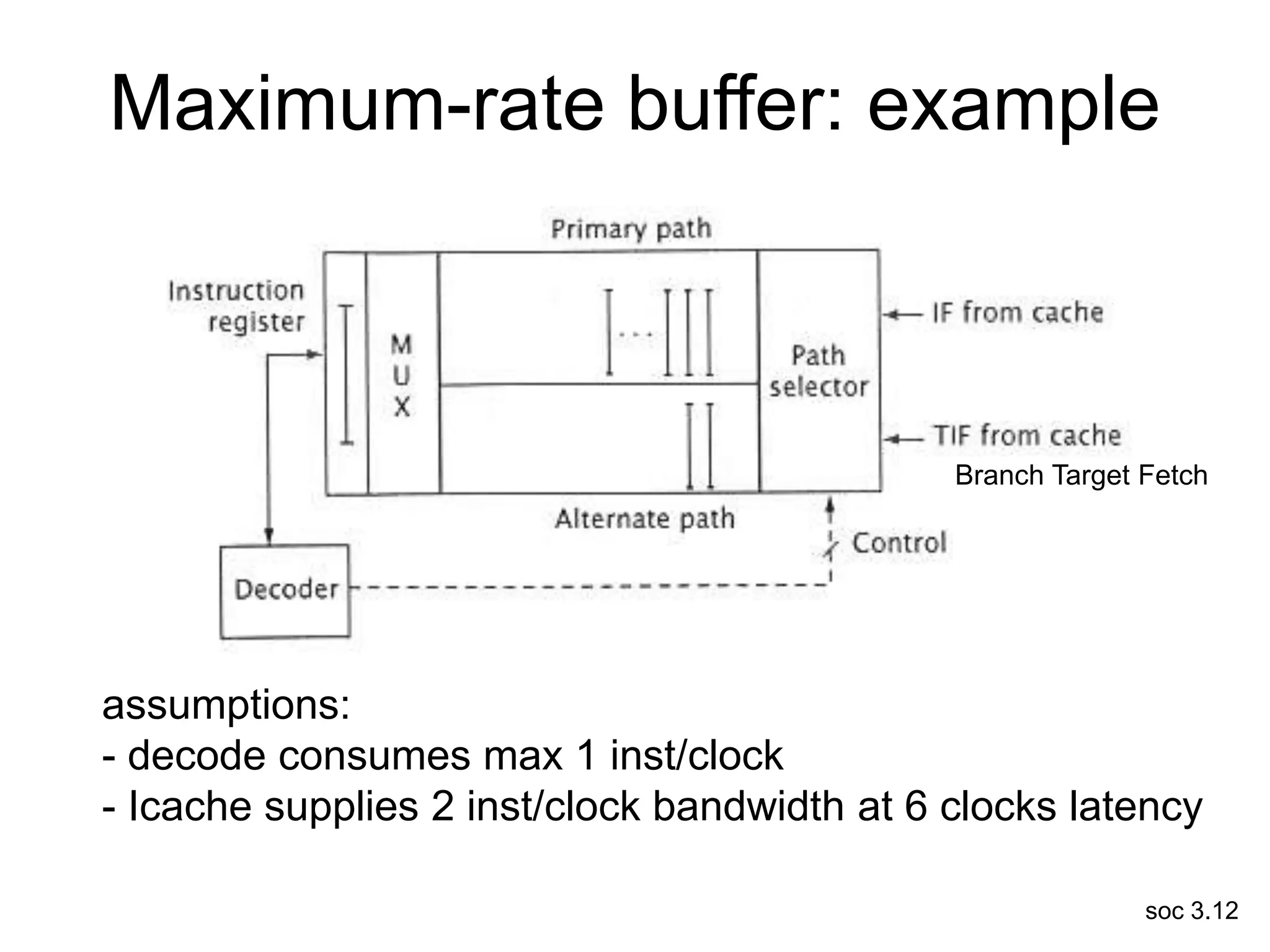
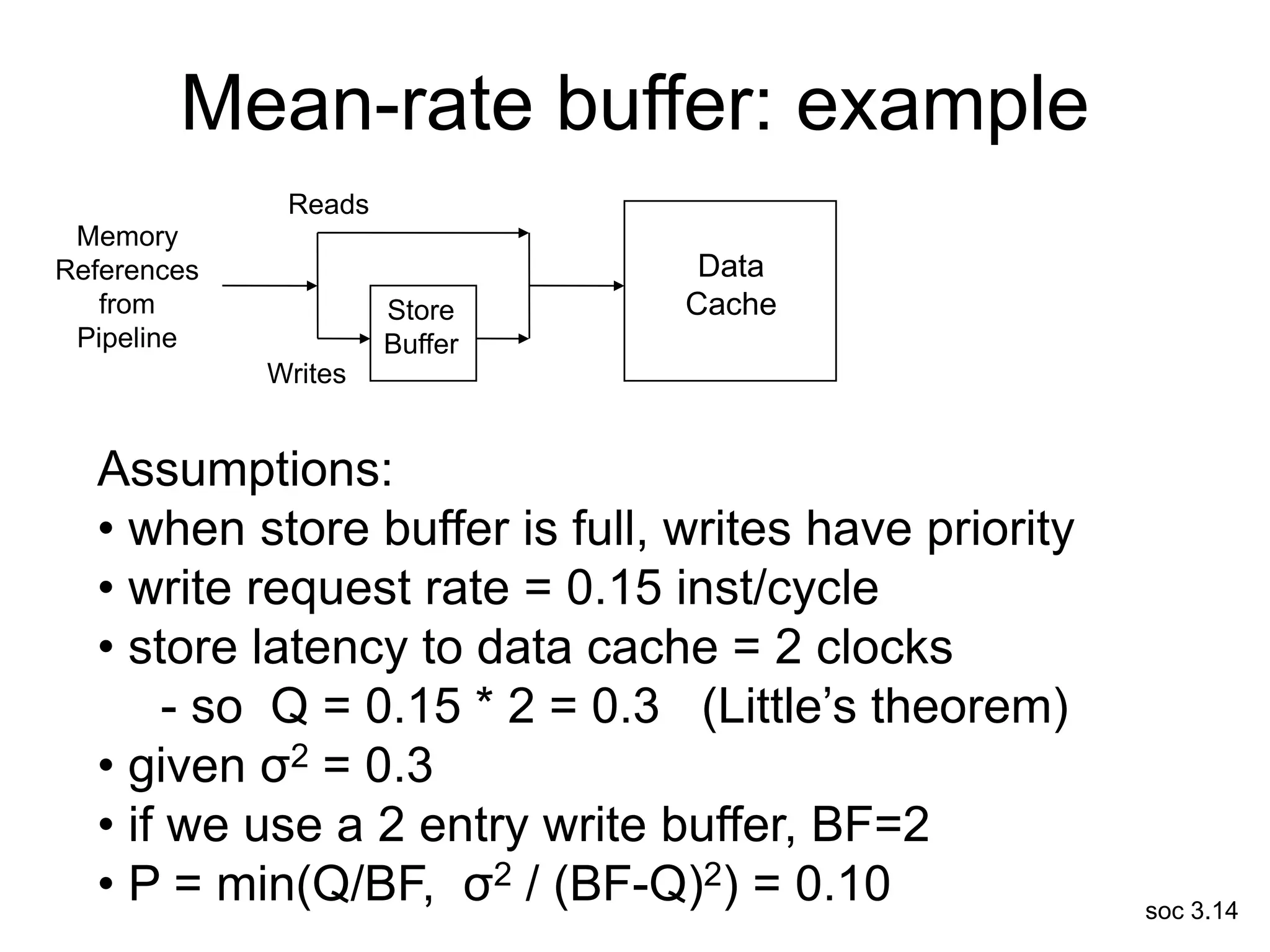
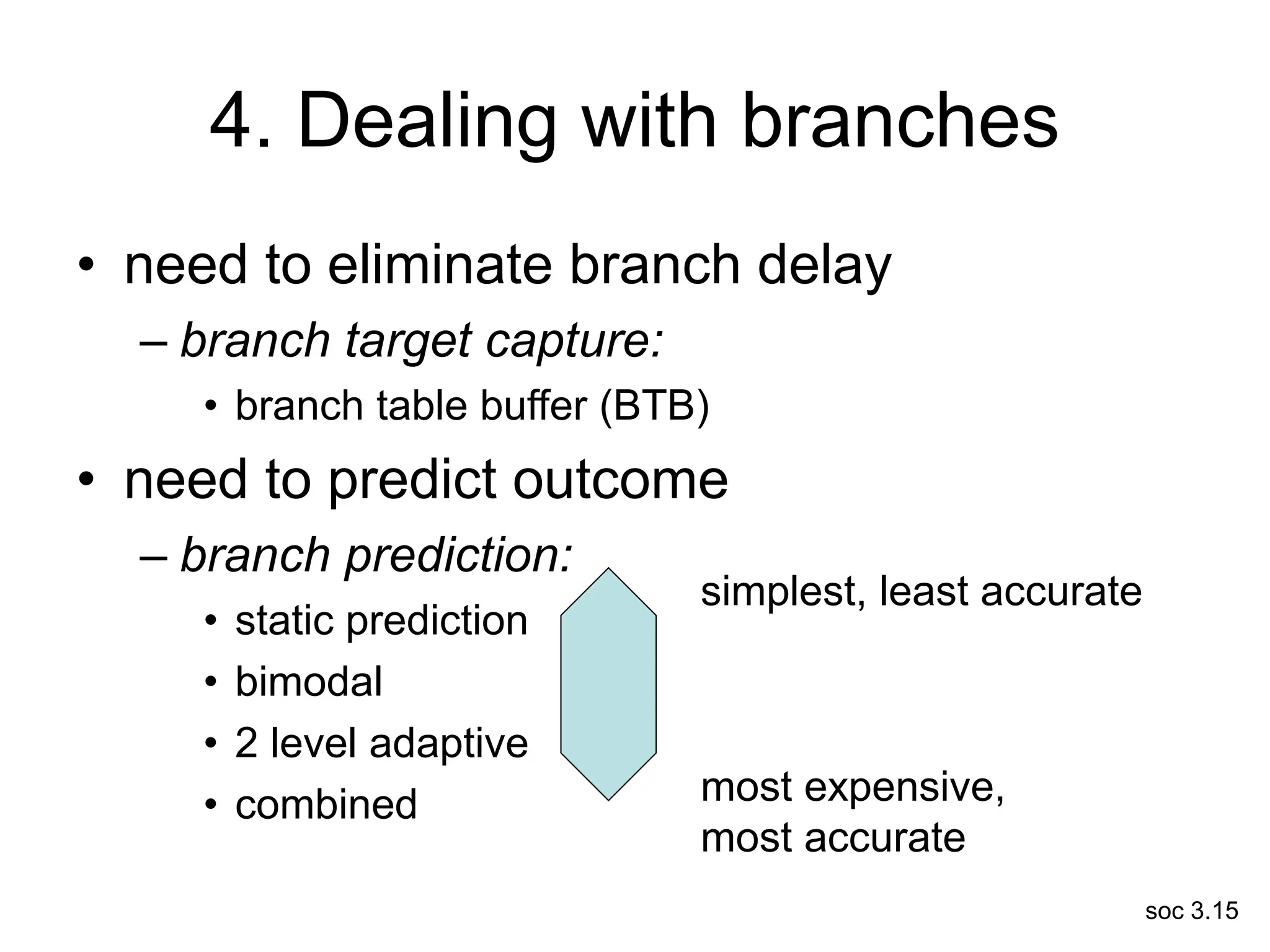
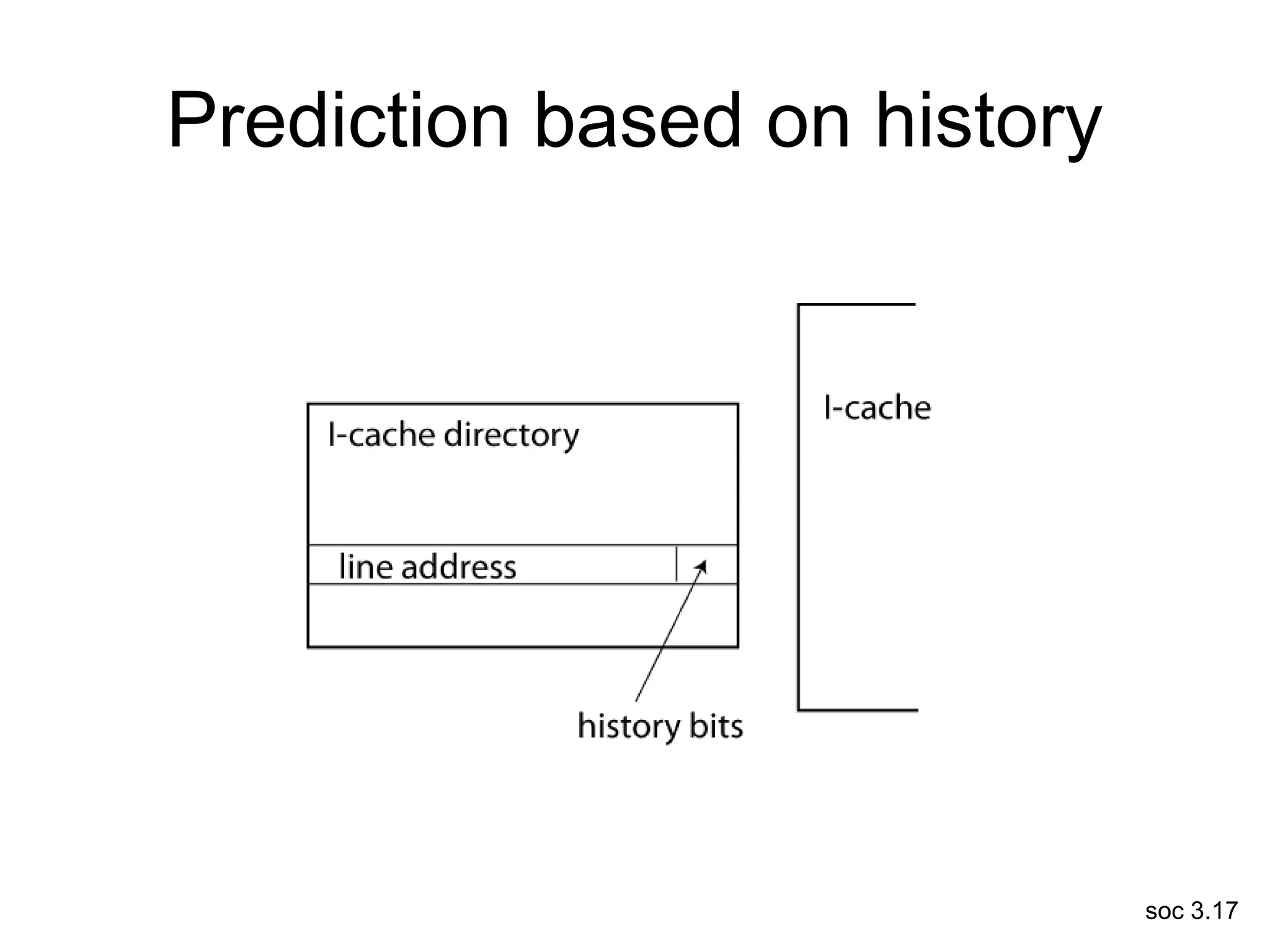
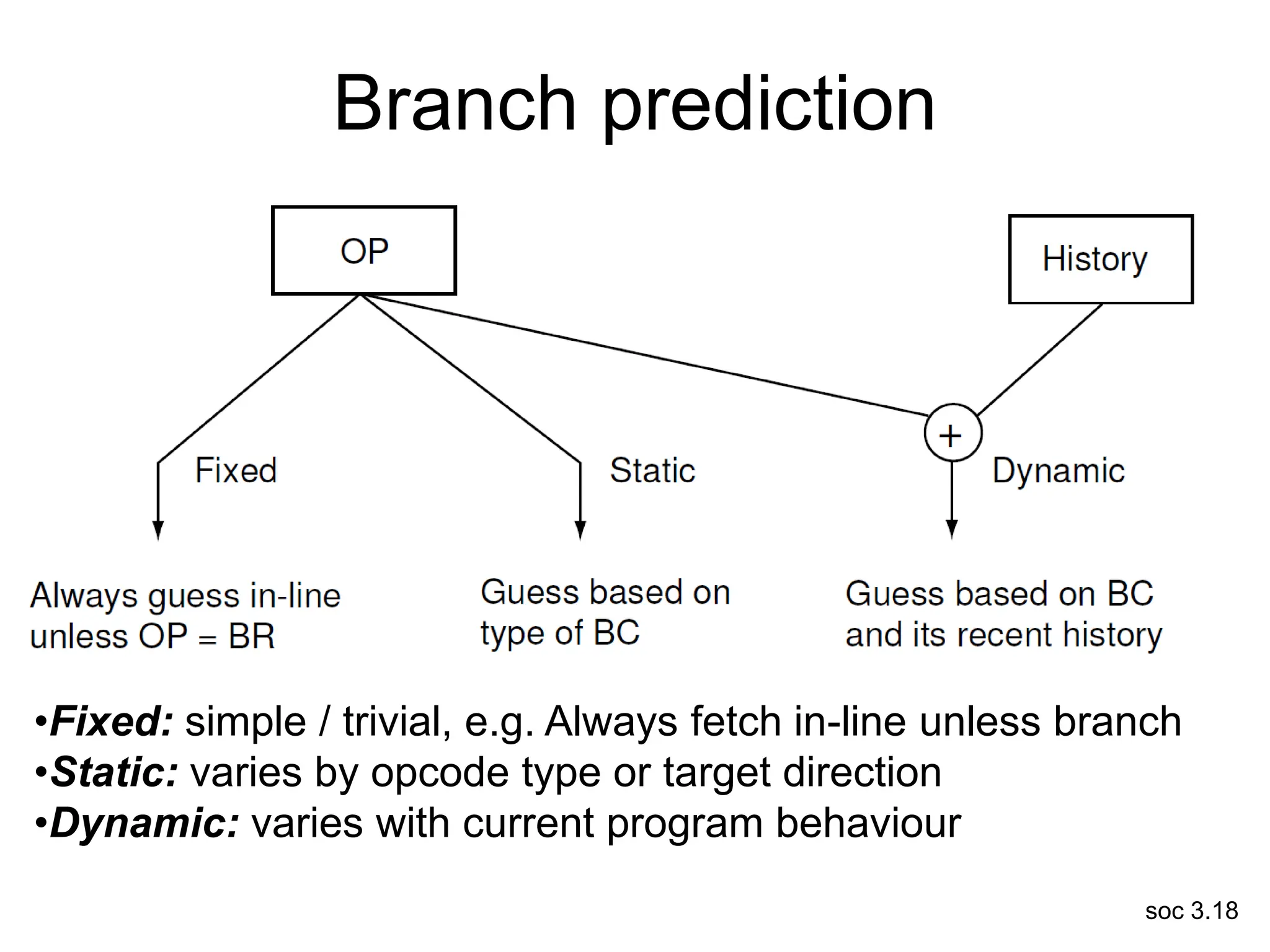
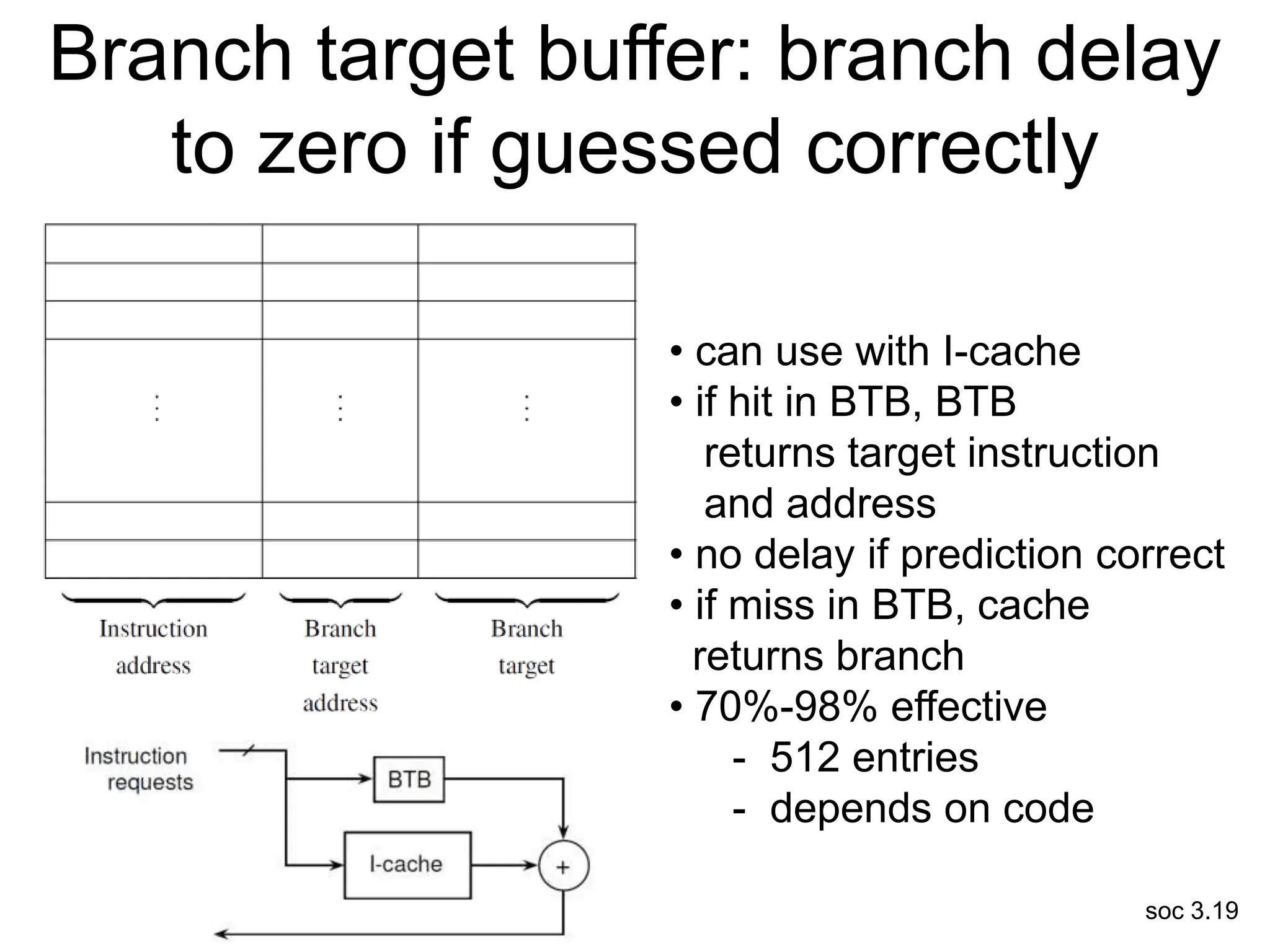
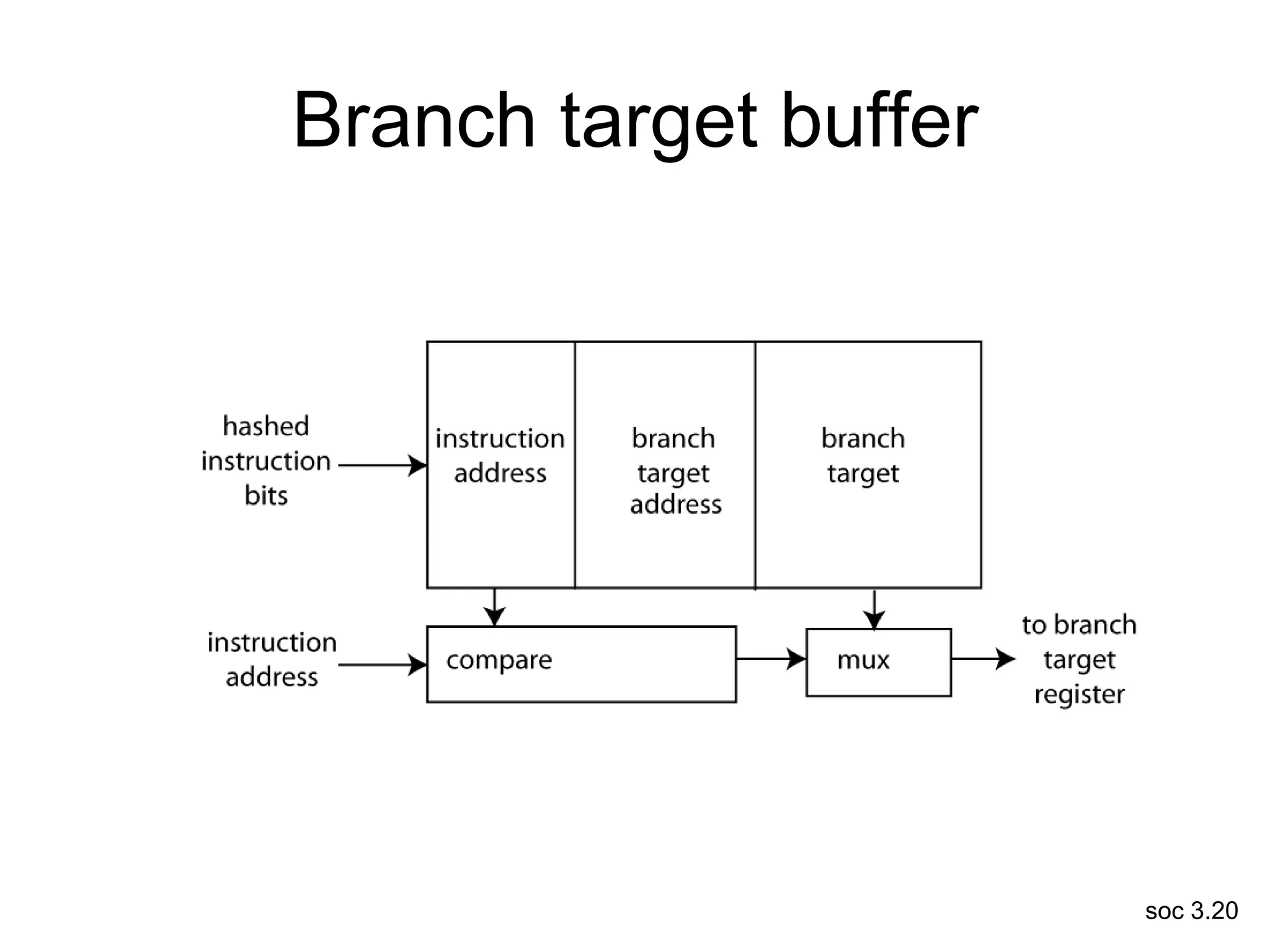
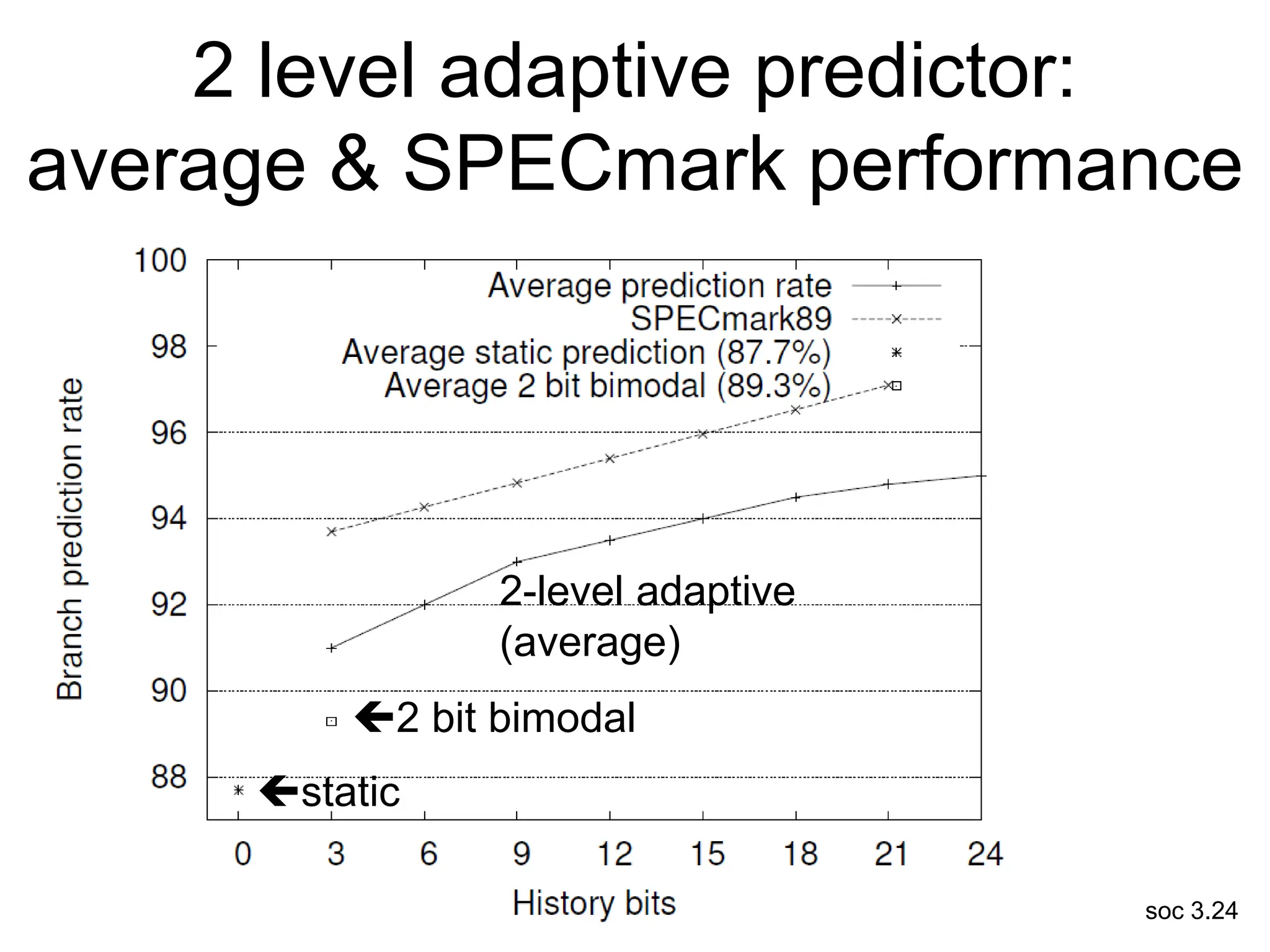
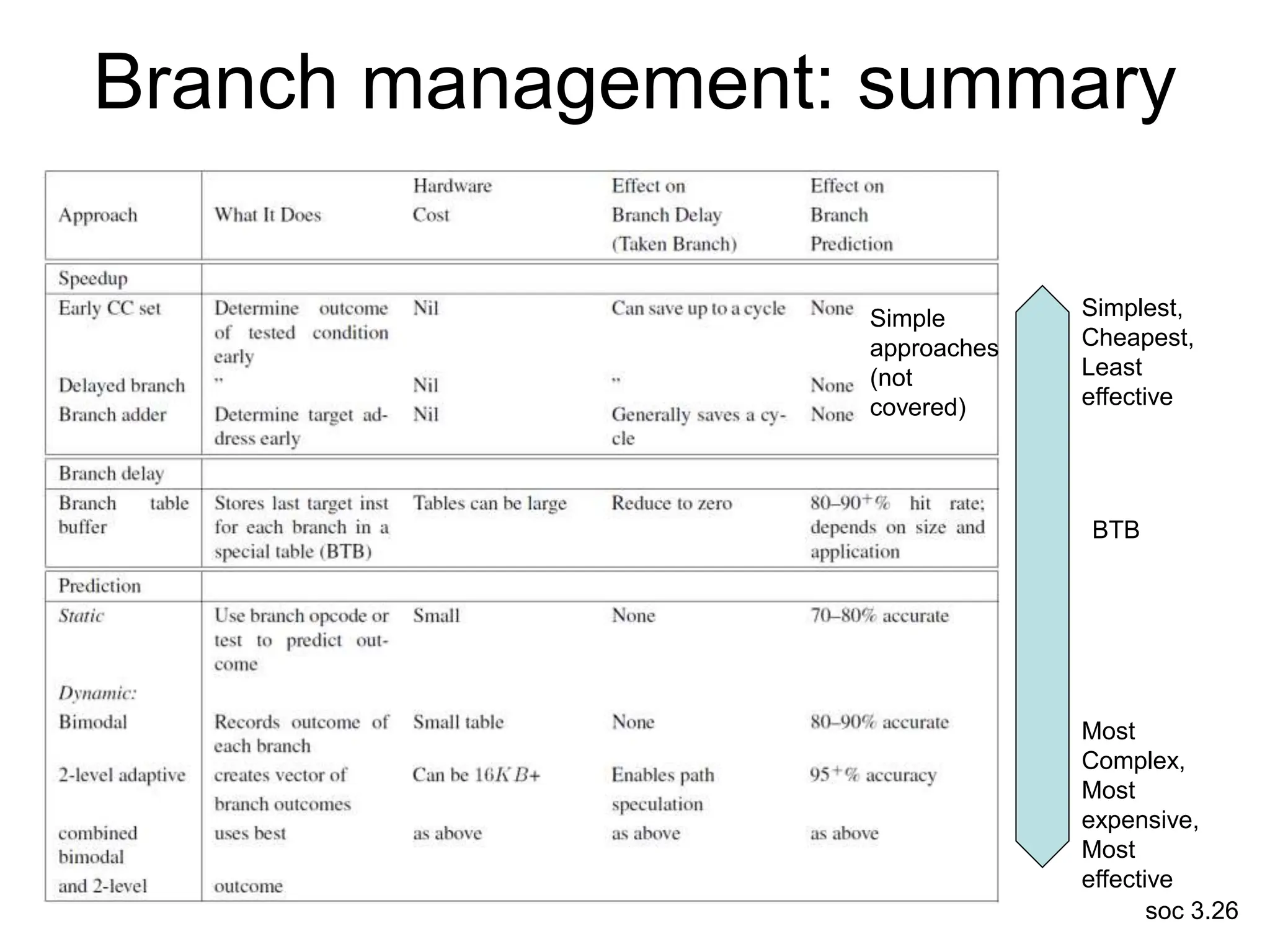
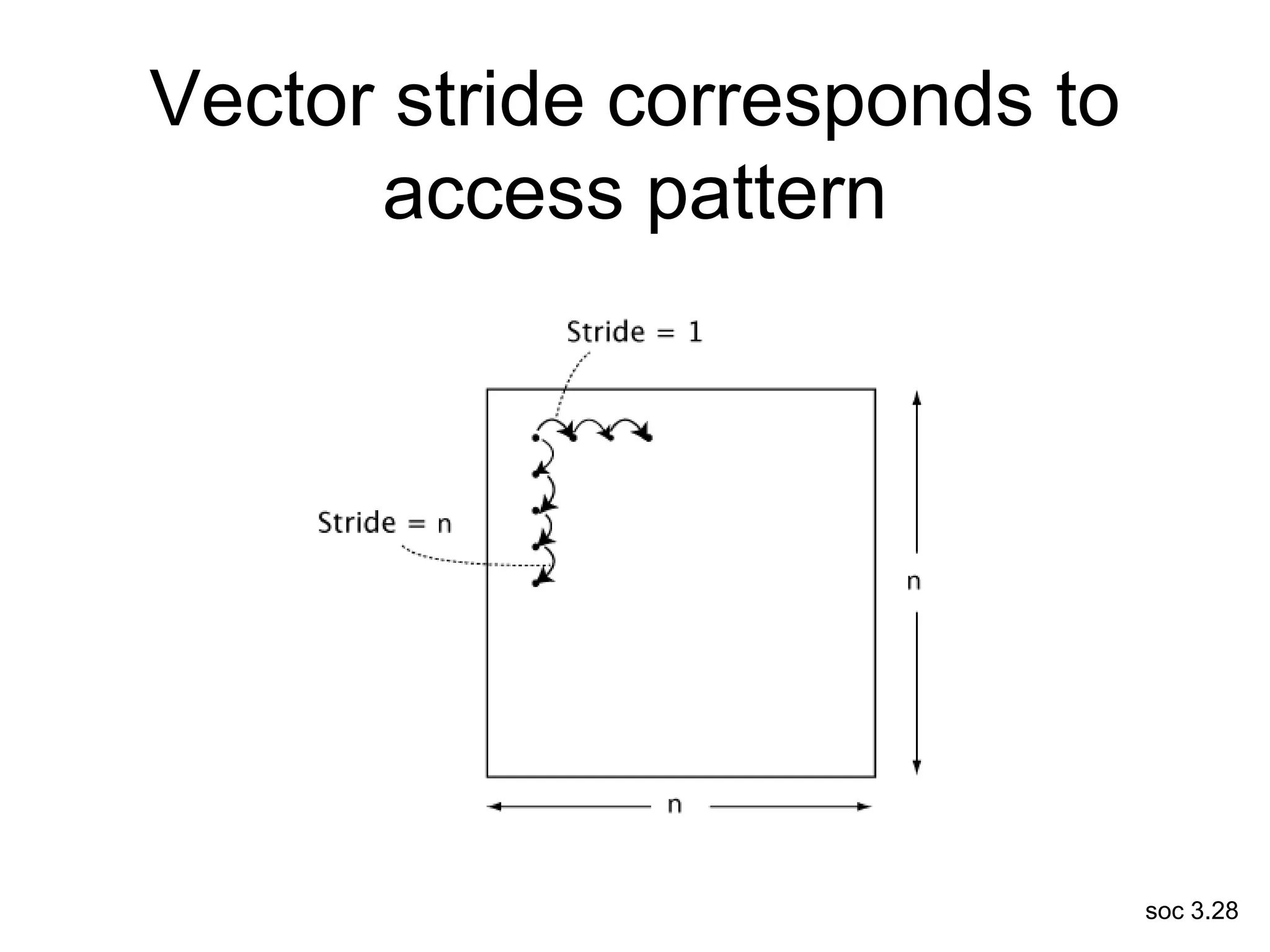
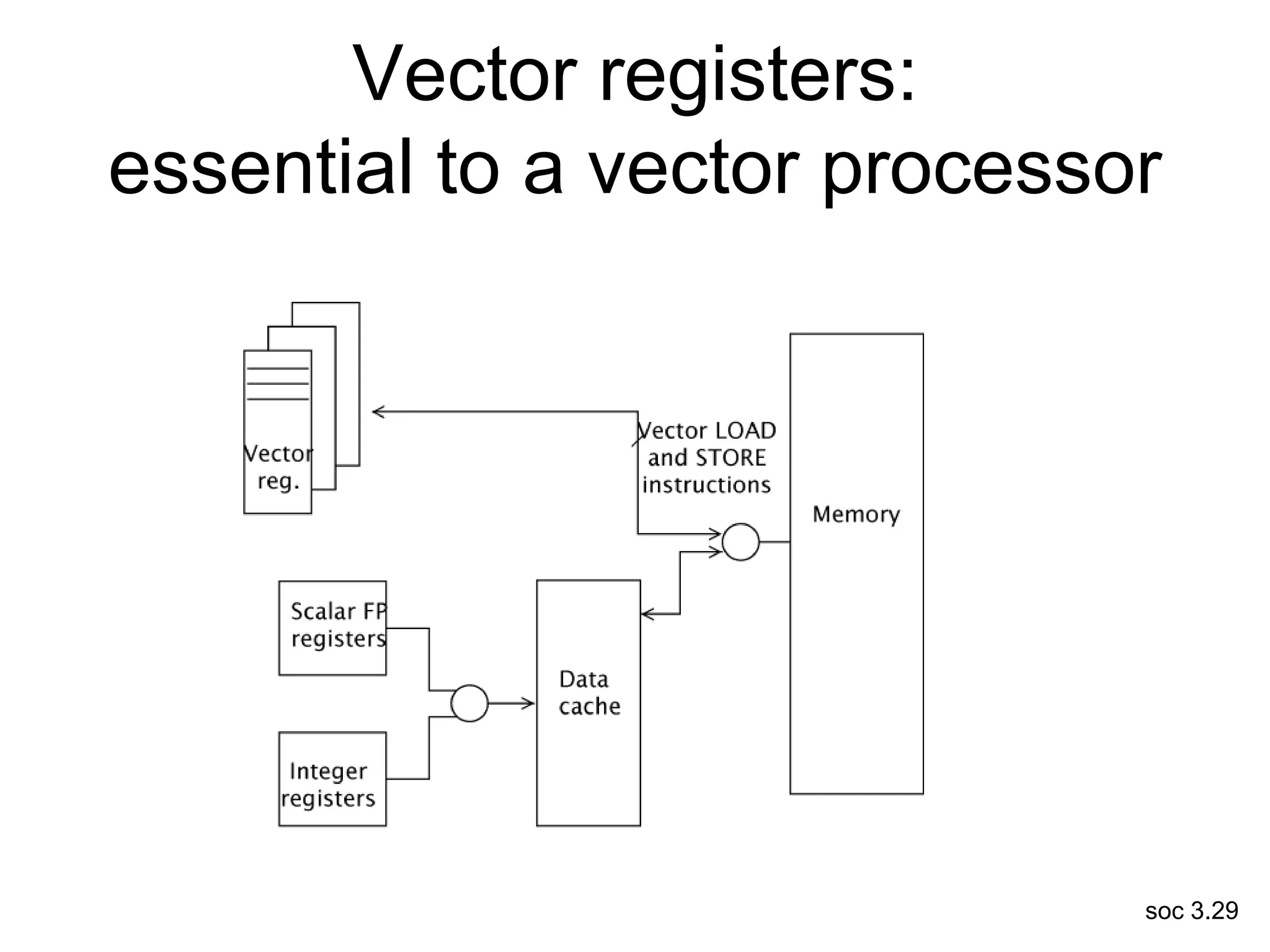
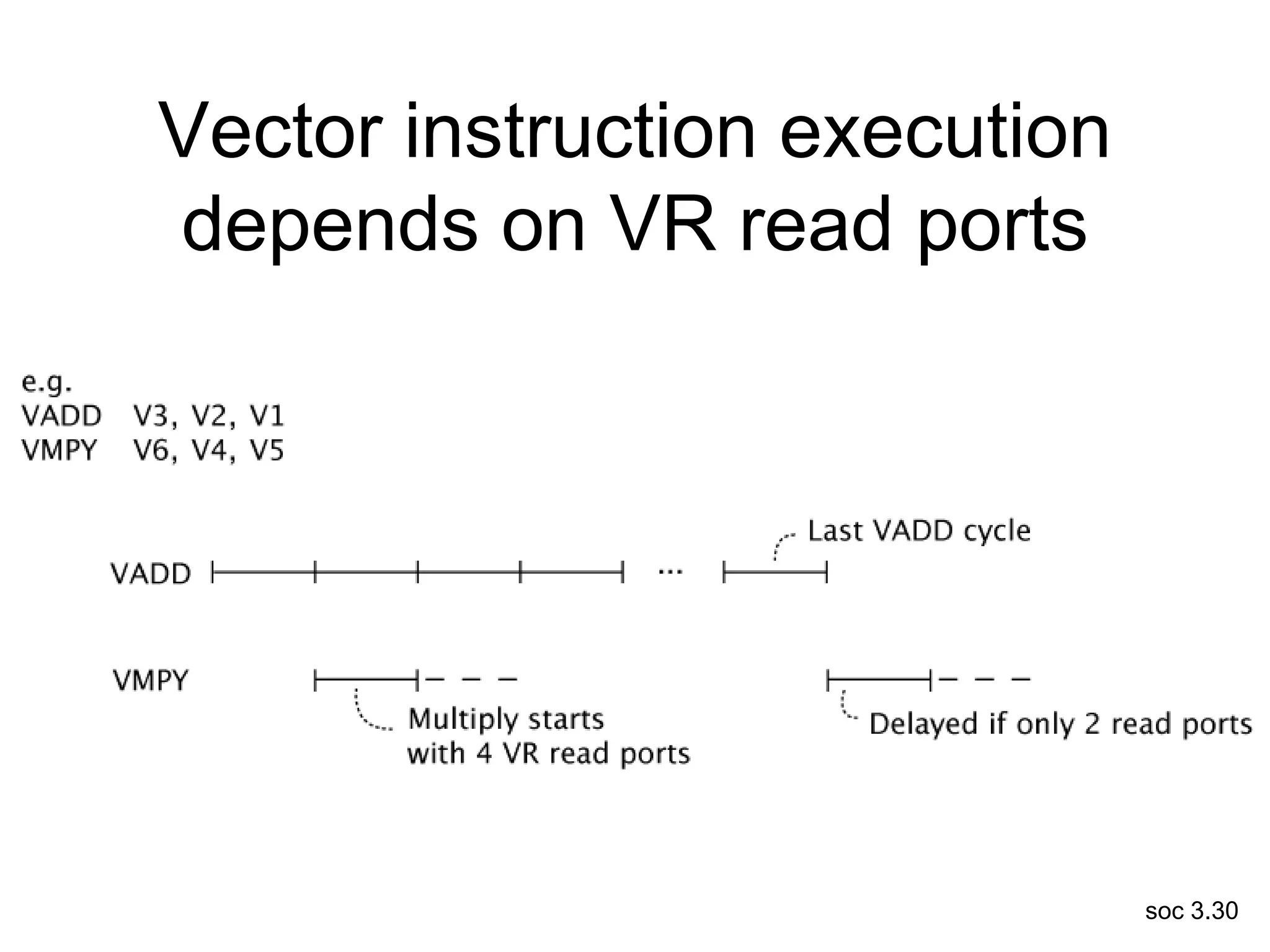
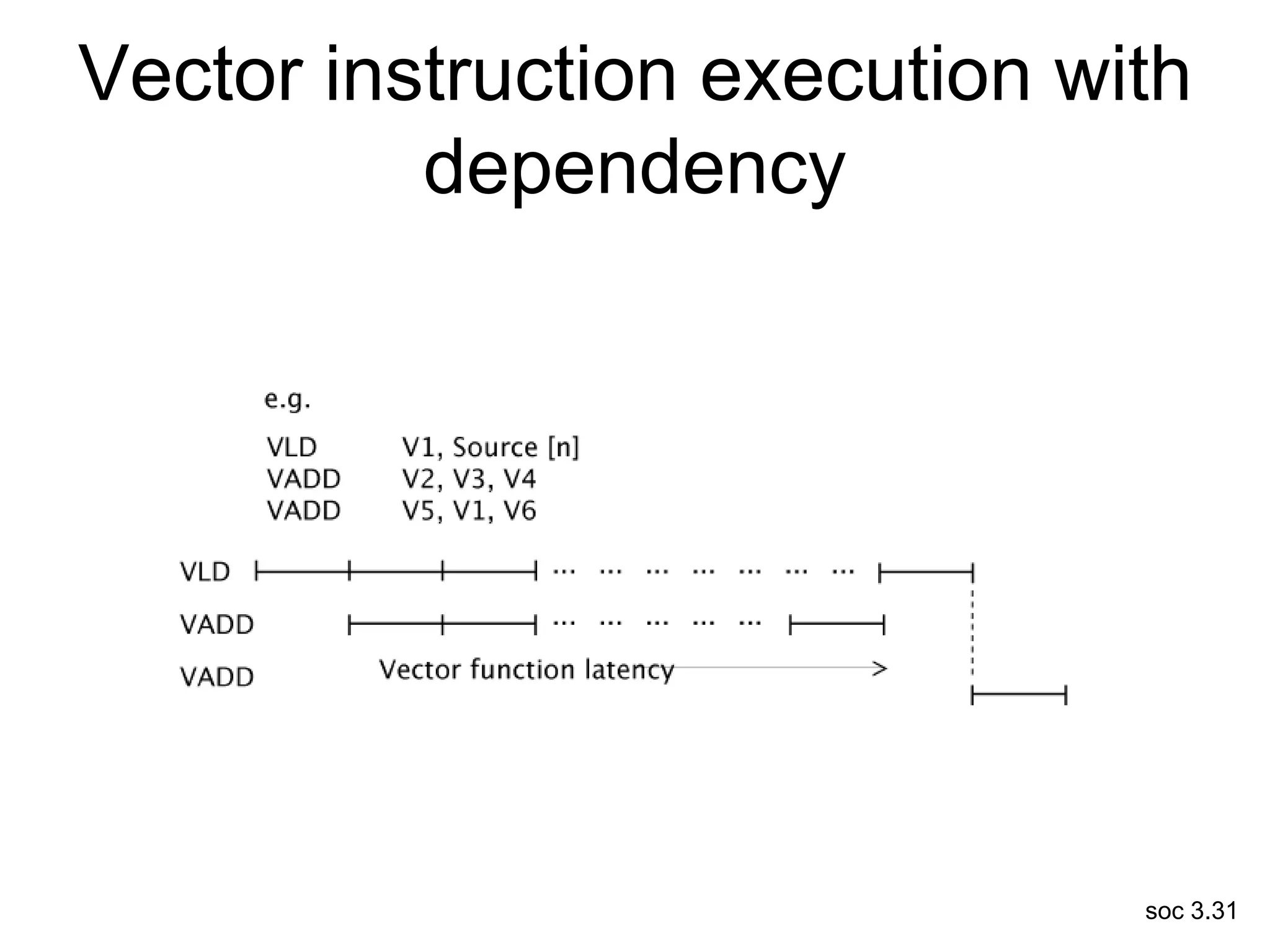
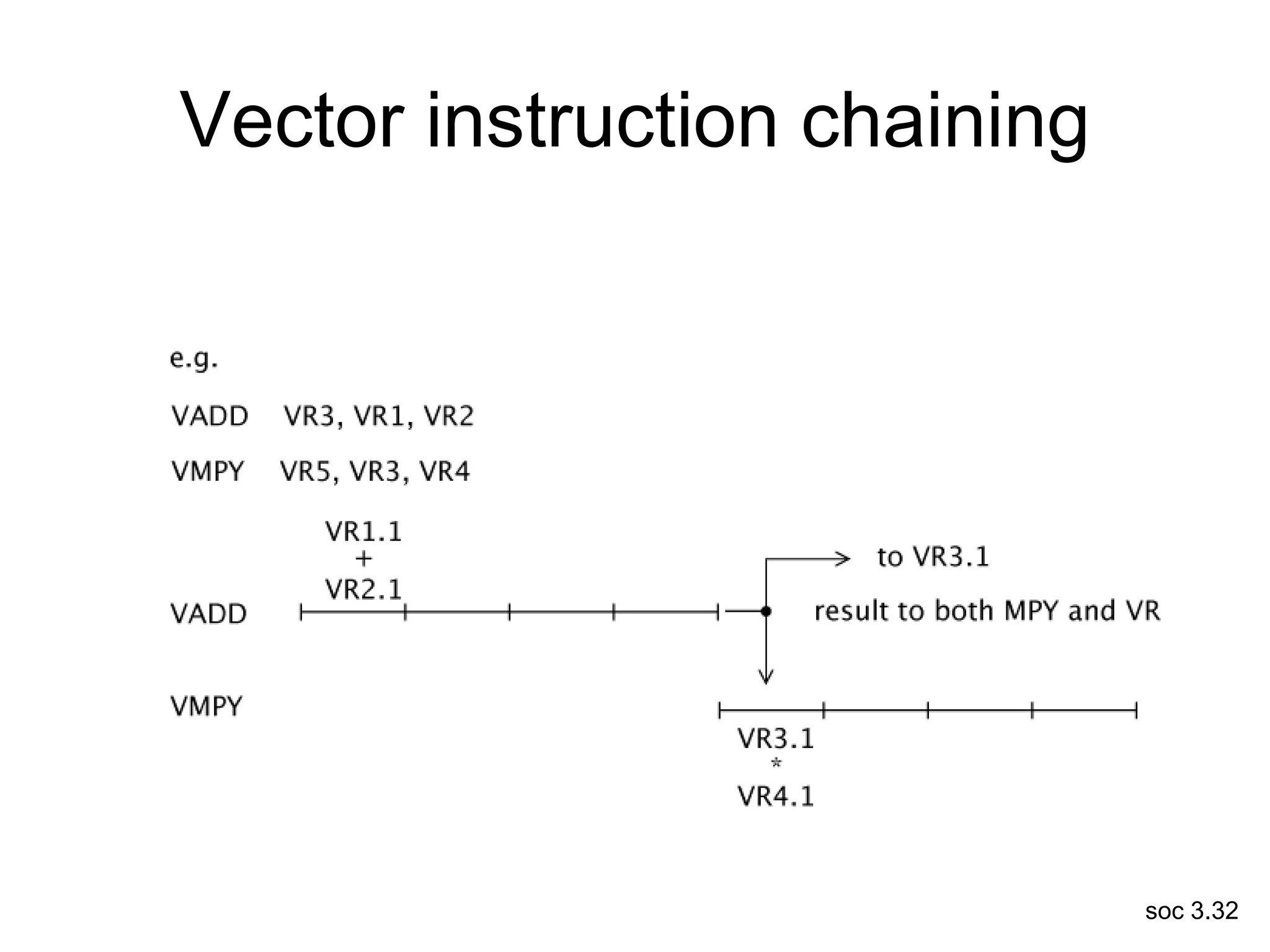
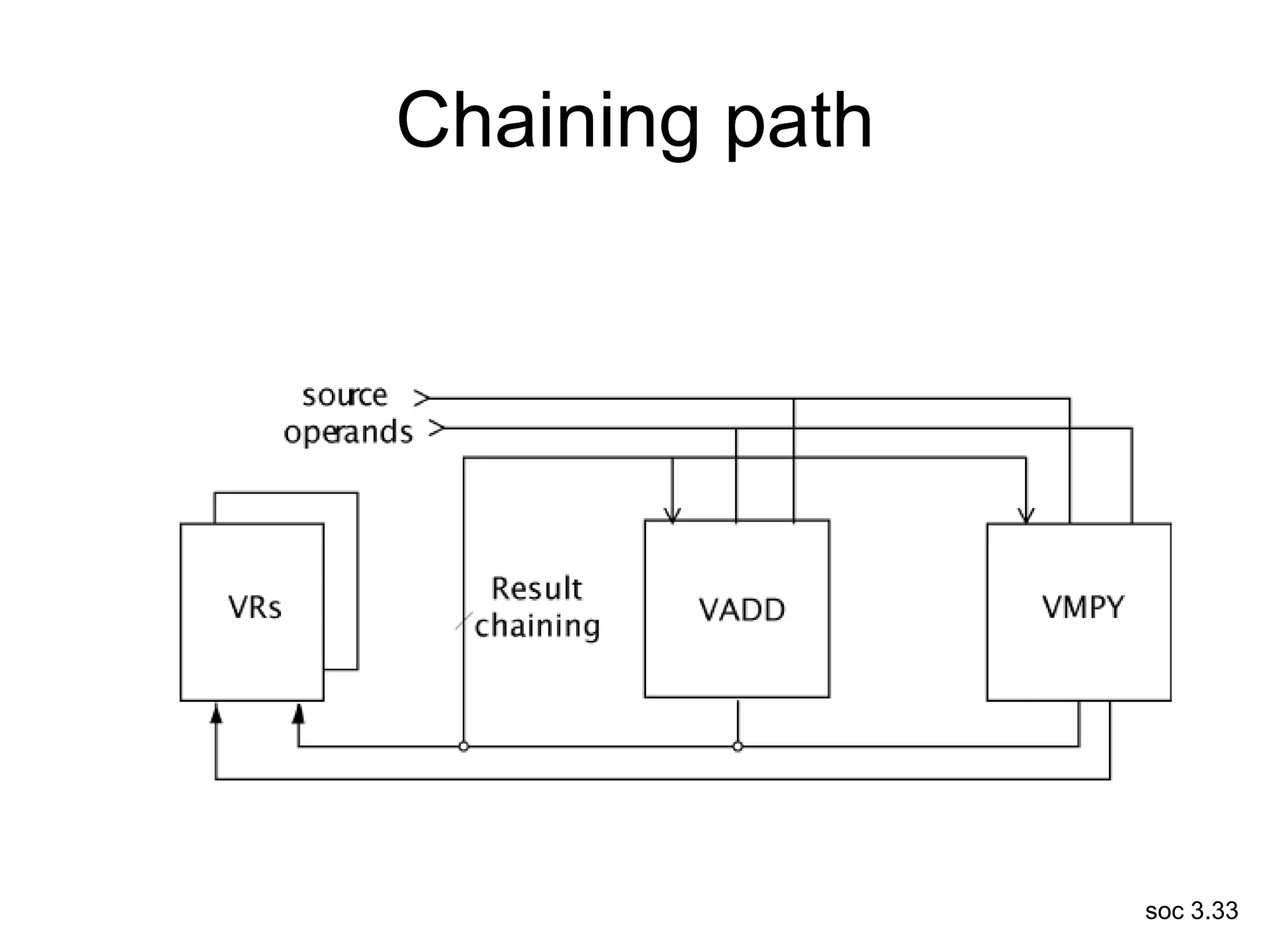
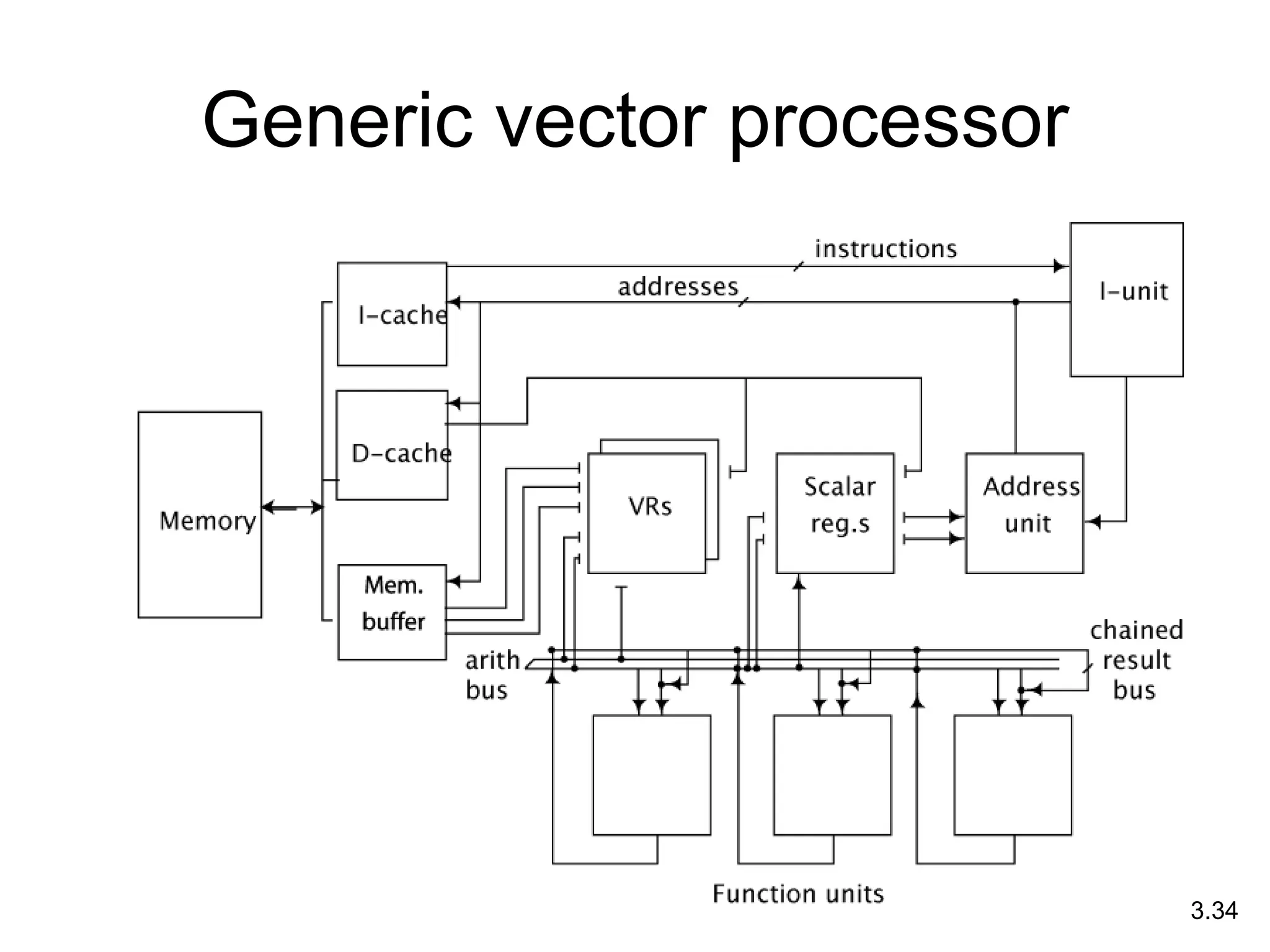
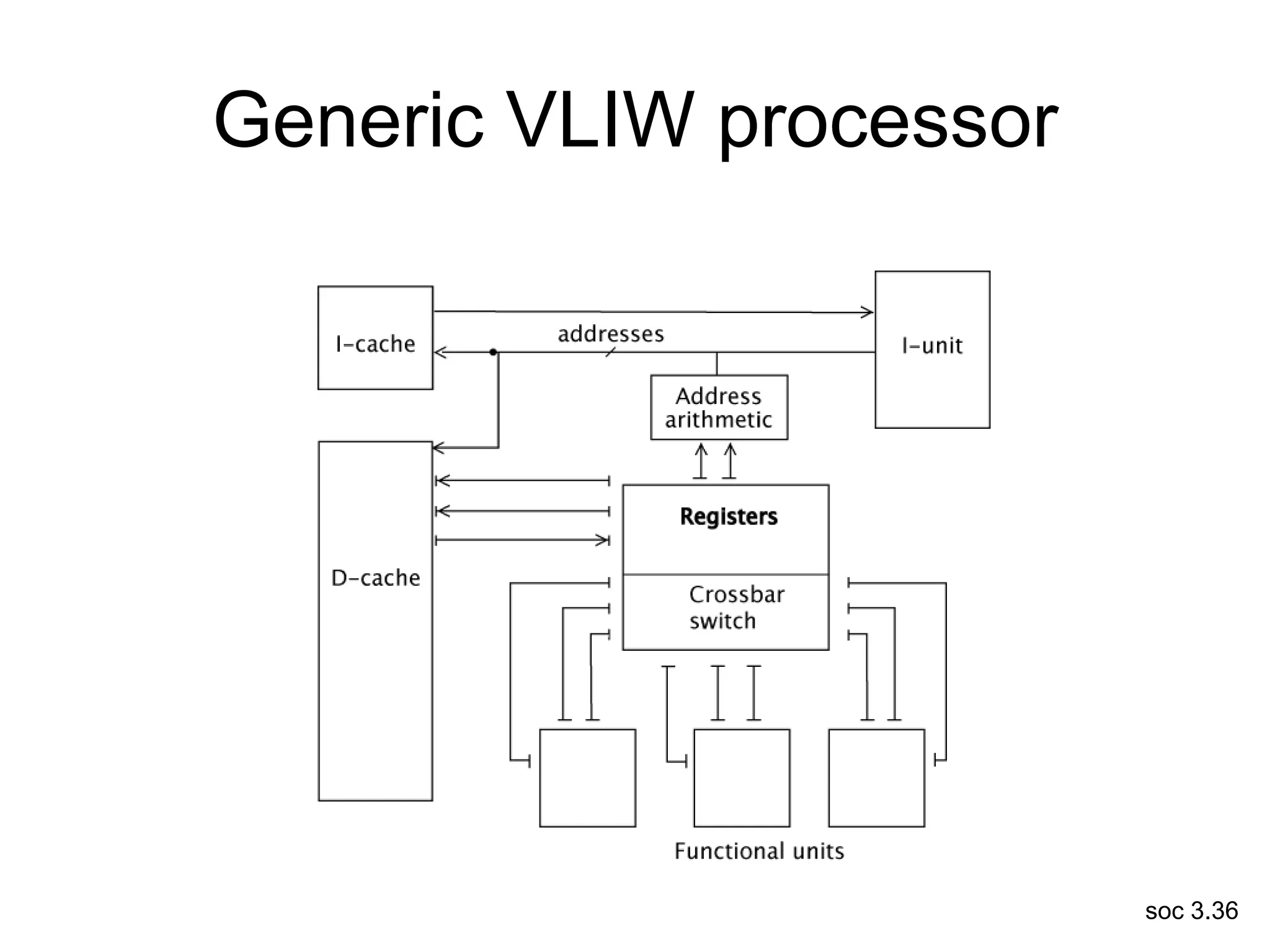
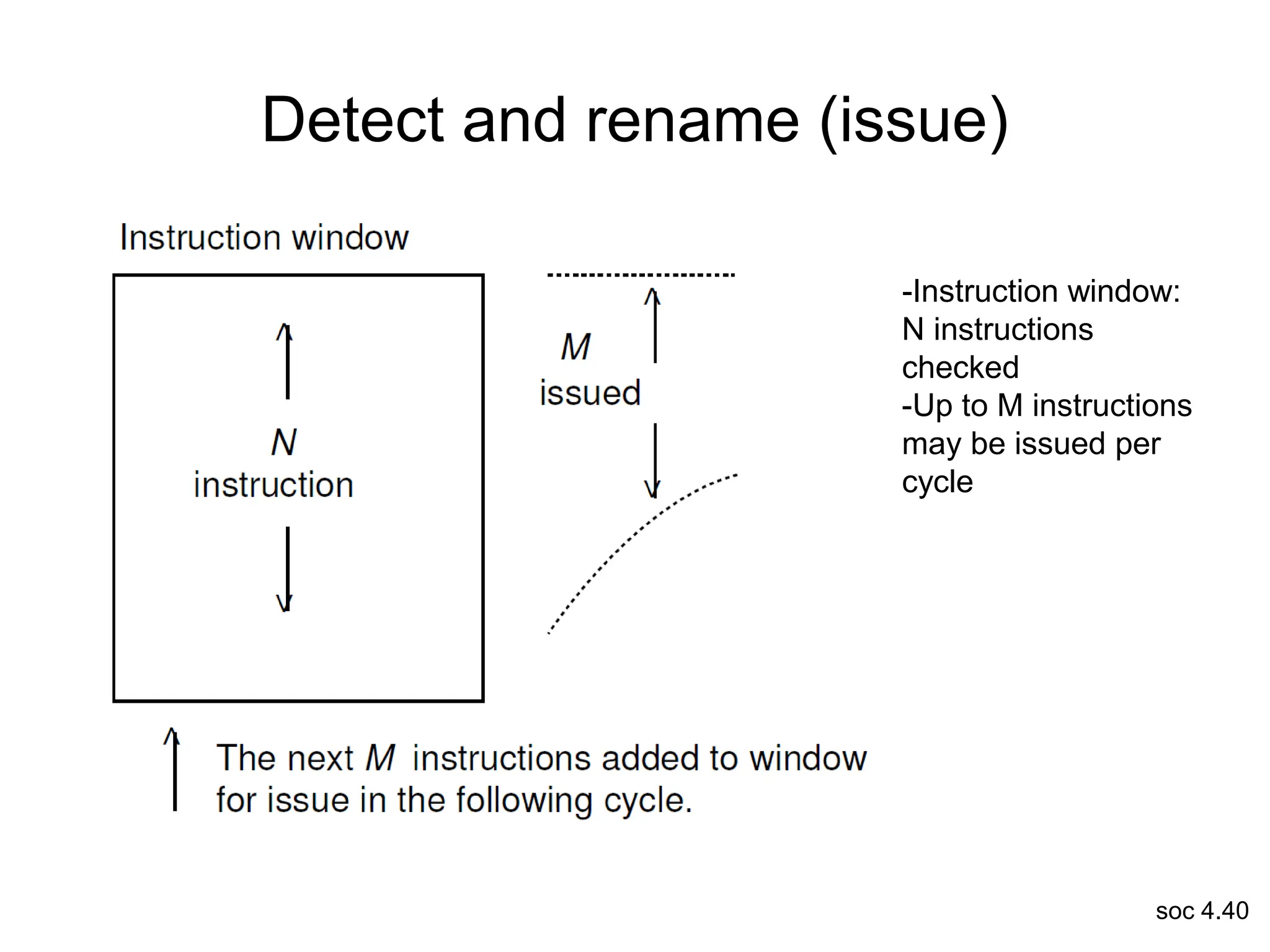
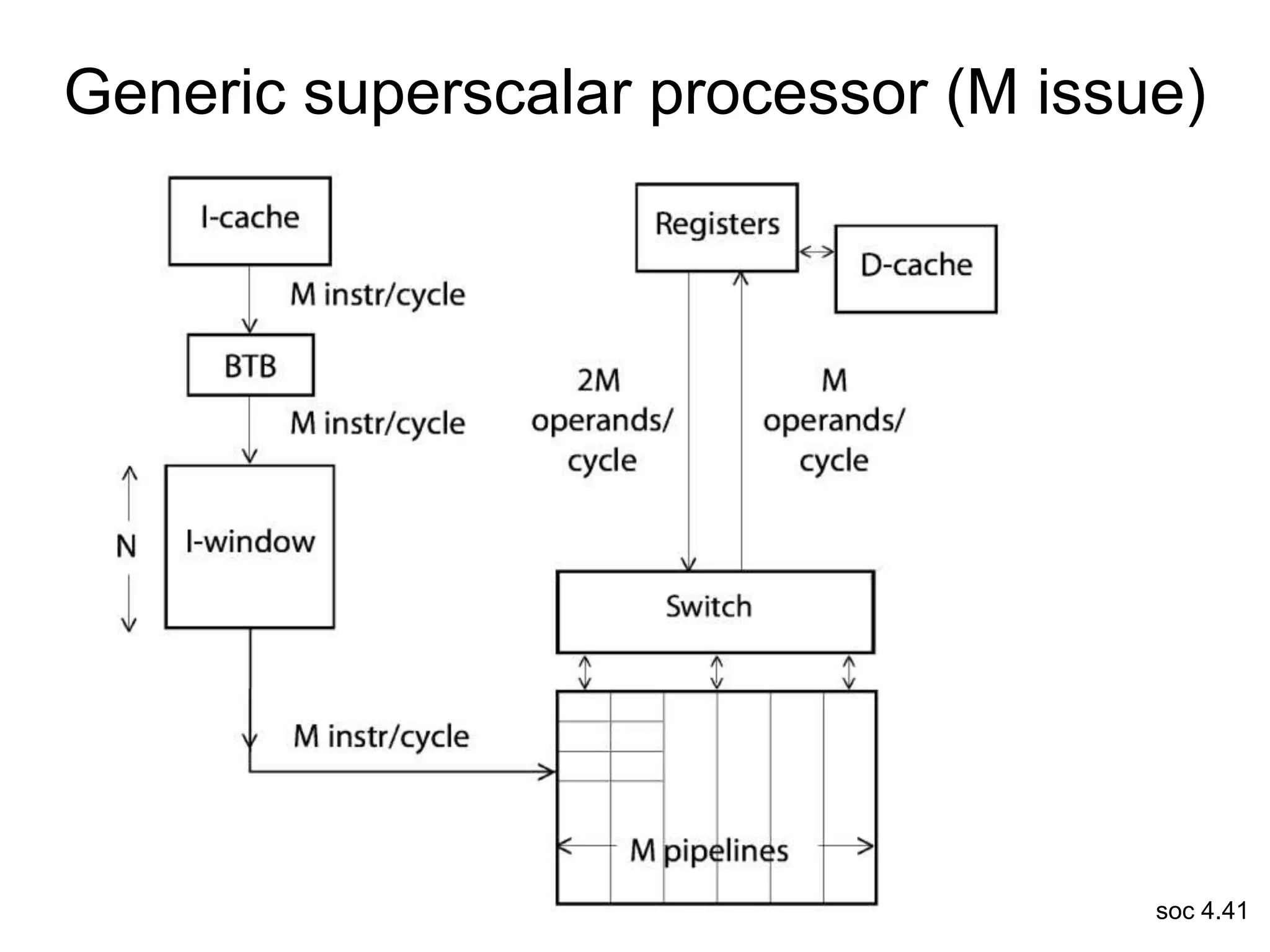
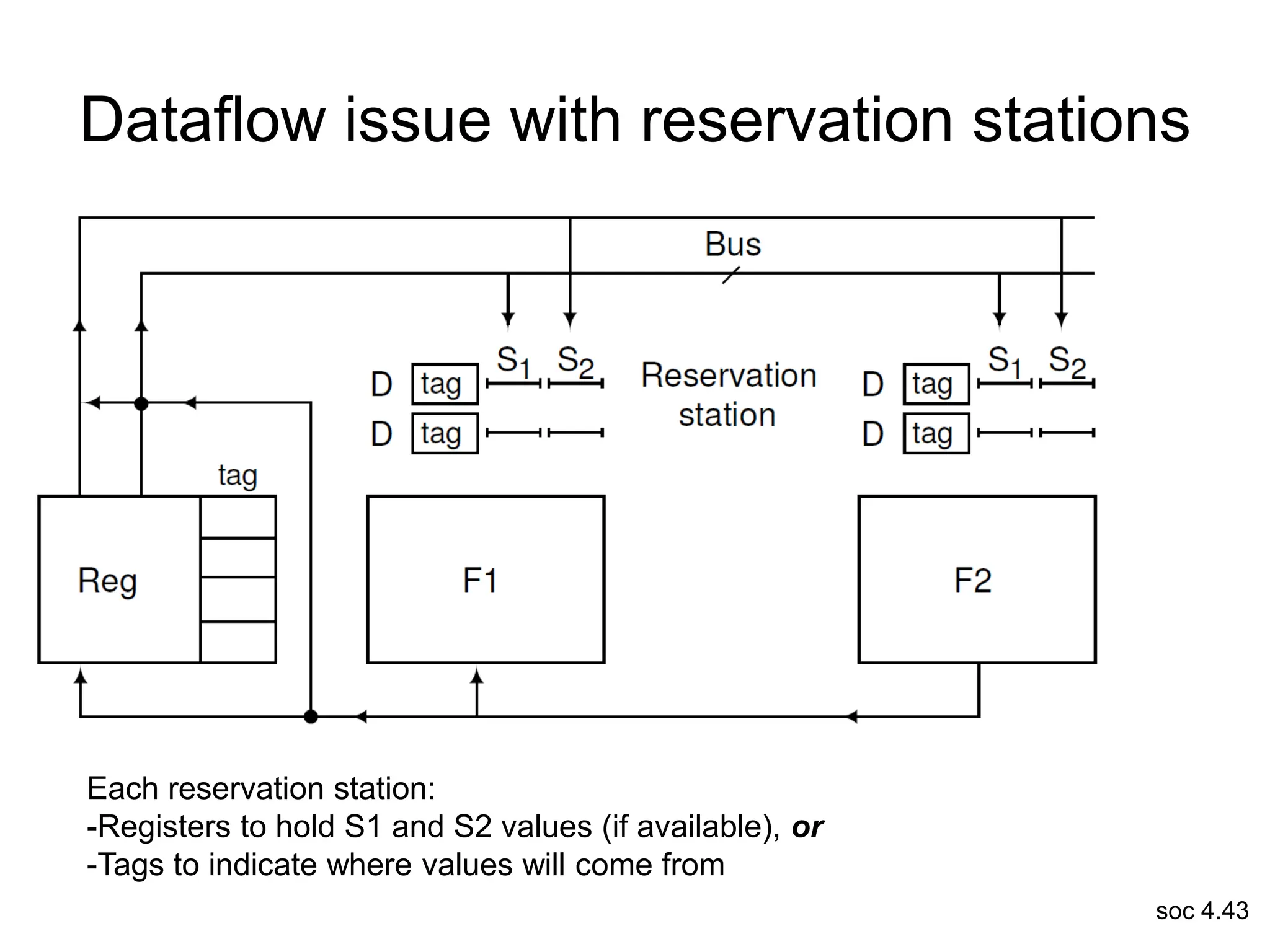
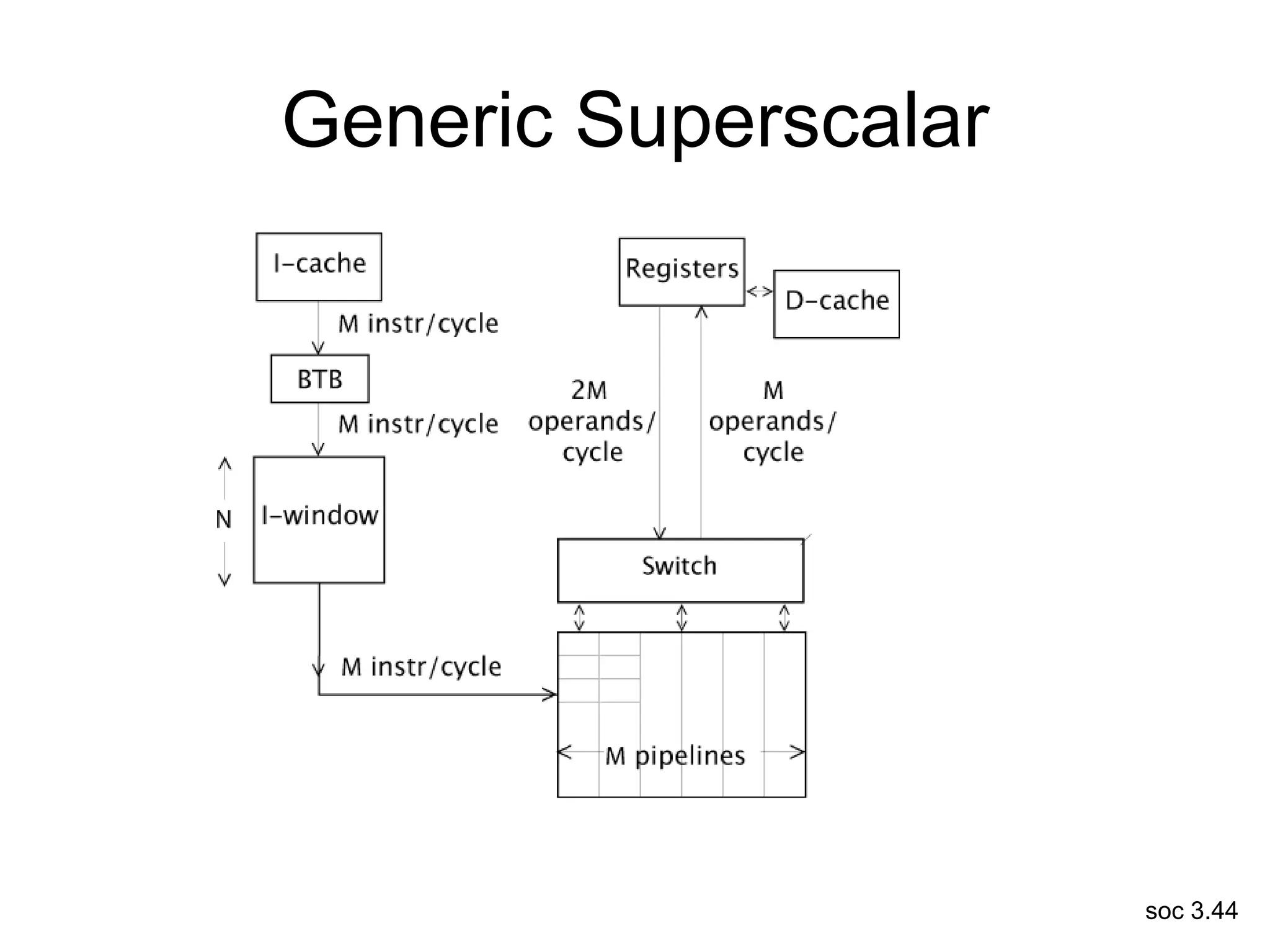
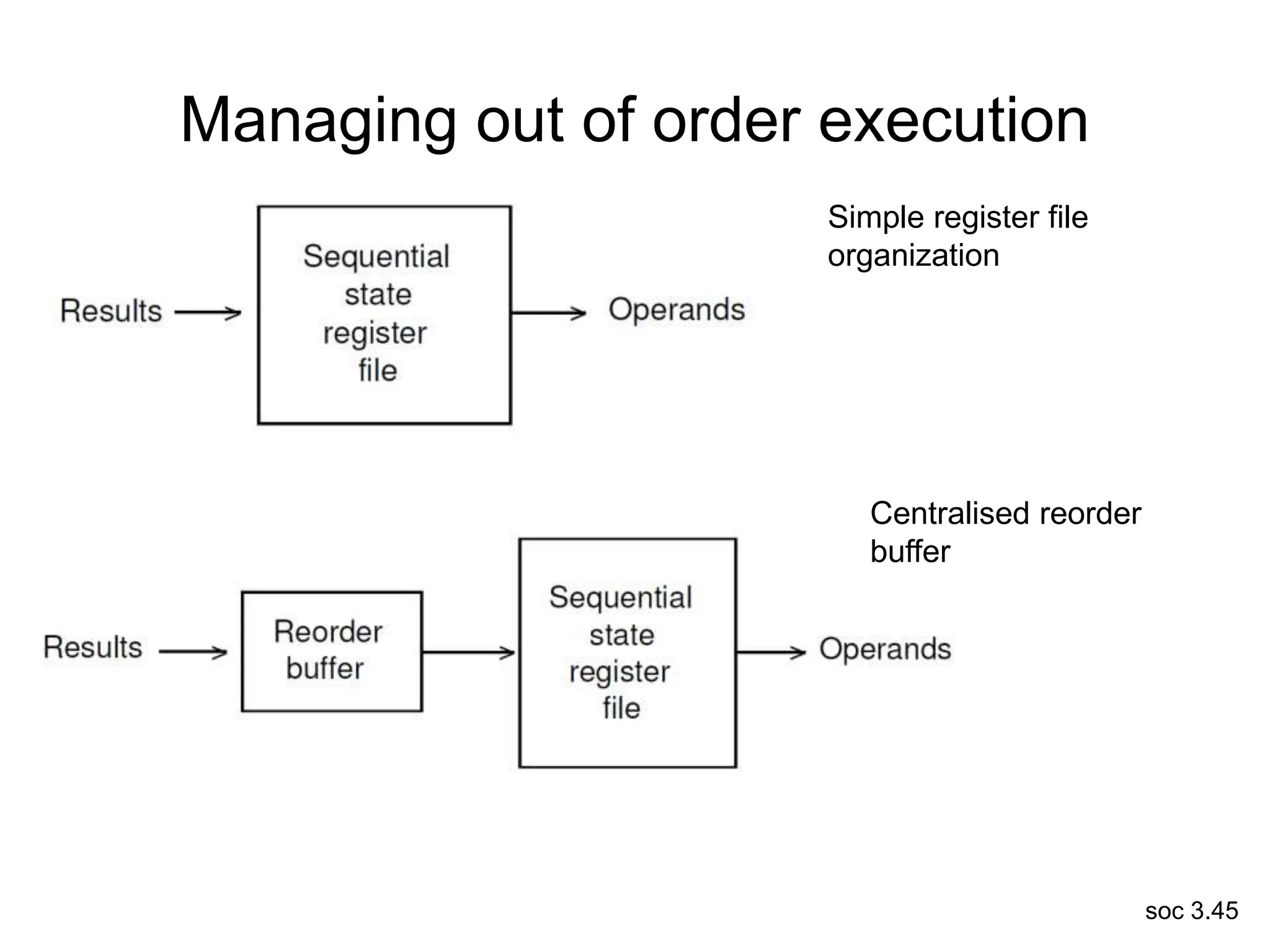
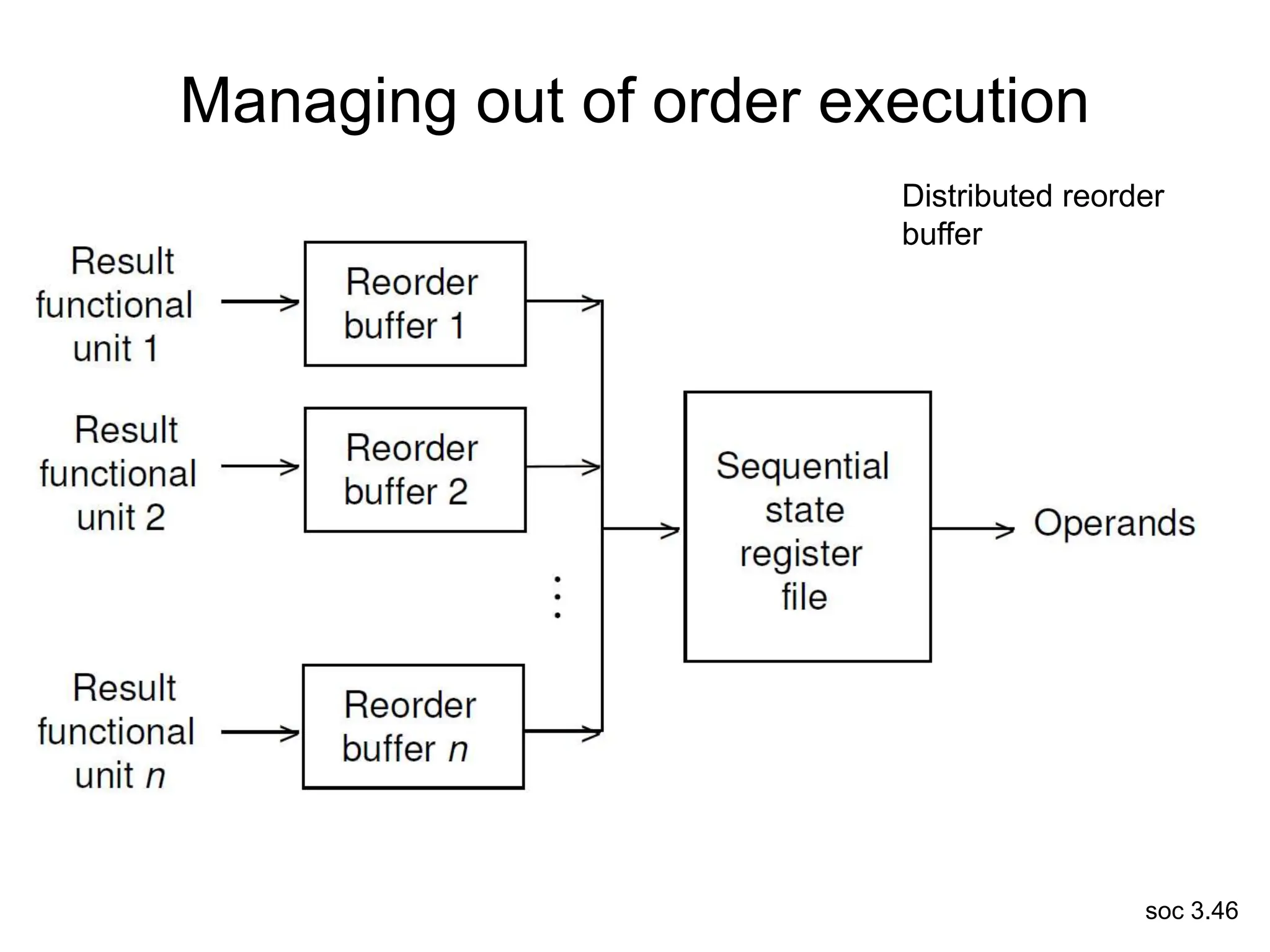
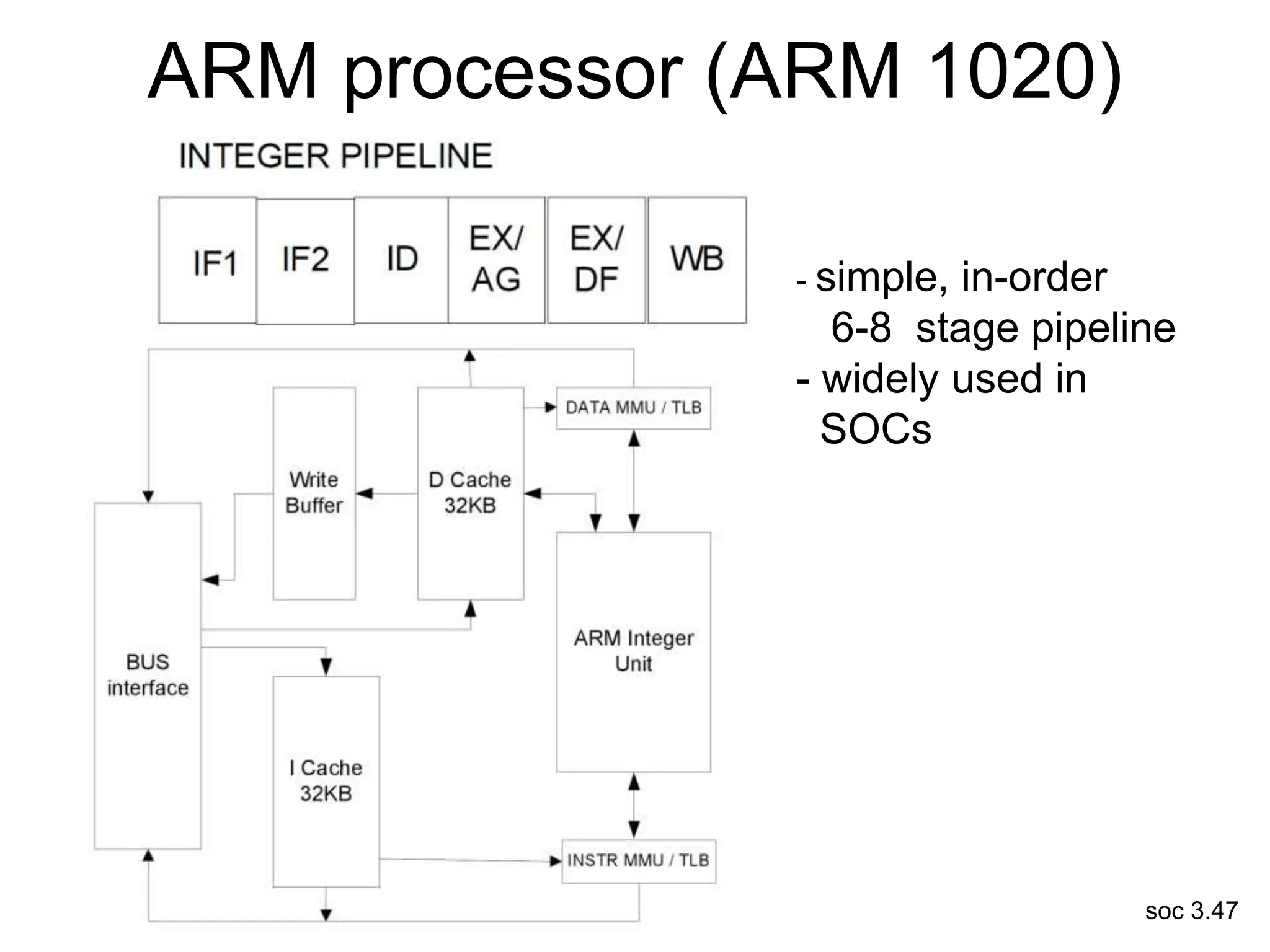
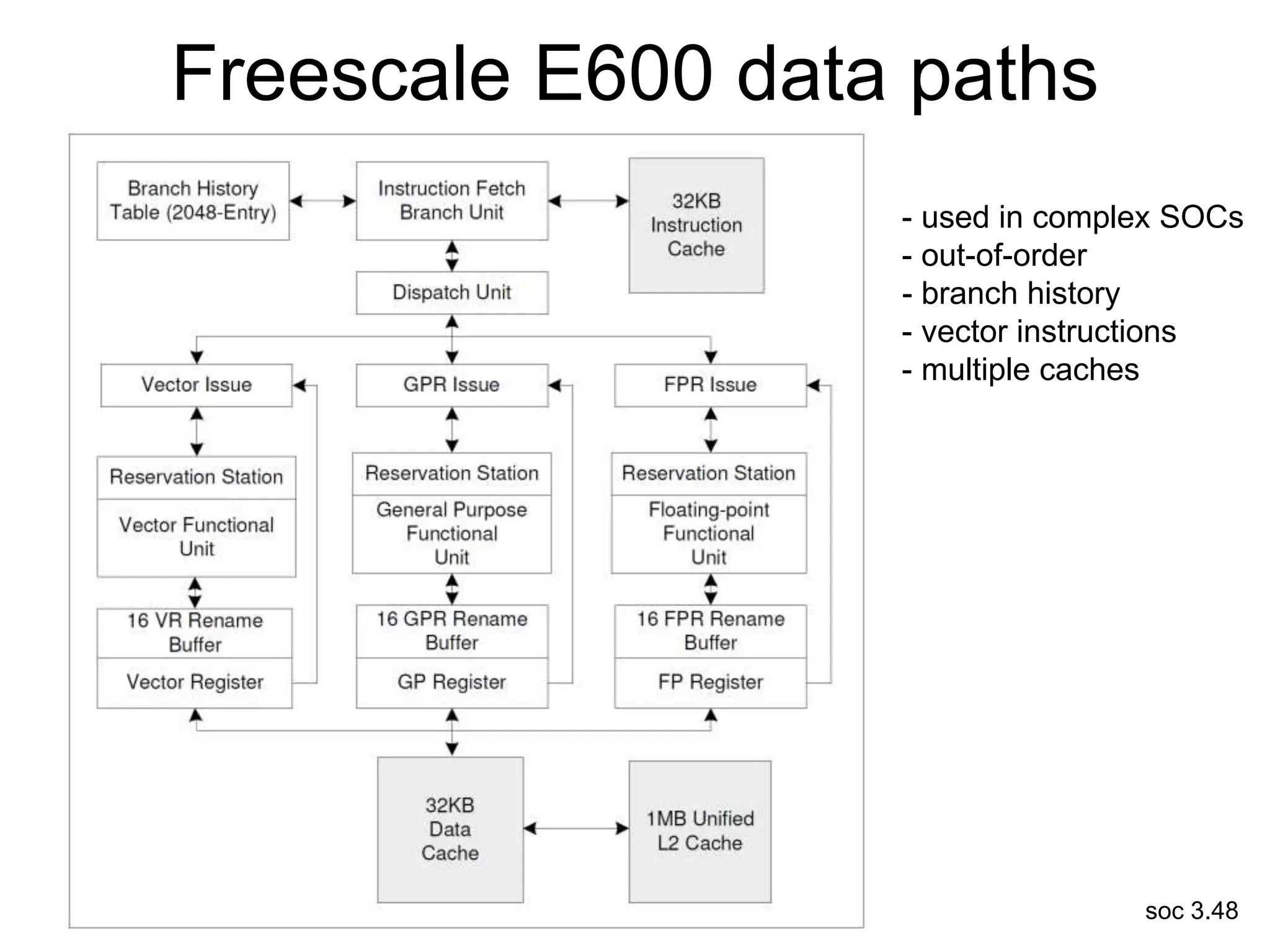
This document discusses processor design, including selecting a processor core, designing the processor pipeline, buffer design, and dealing with branches. It describes in-order pipelines, techniques for branch prediction like branch target buffers and dynamic prediction, and buffer sizing approaches for maximum and mean rates. More robust processors like vector, VLIW, and superscalar designs are also summarized.