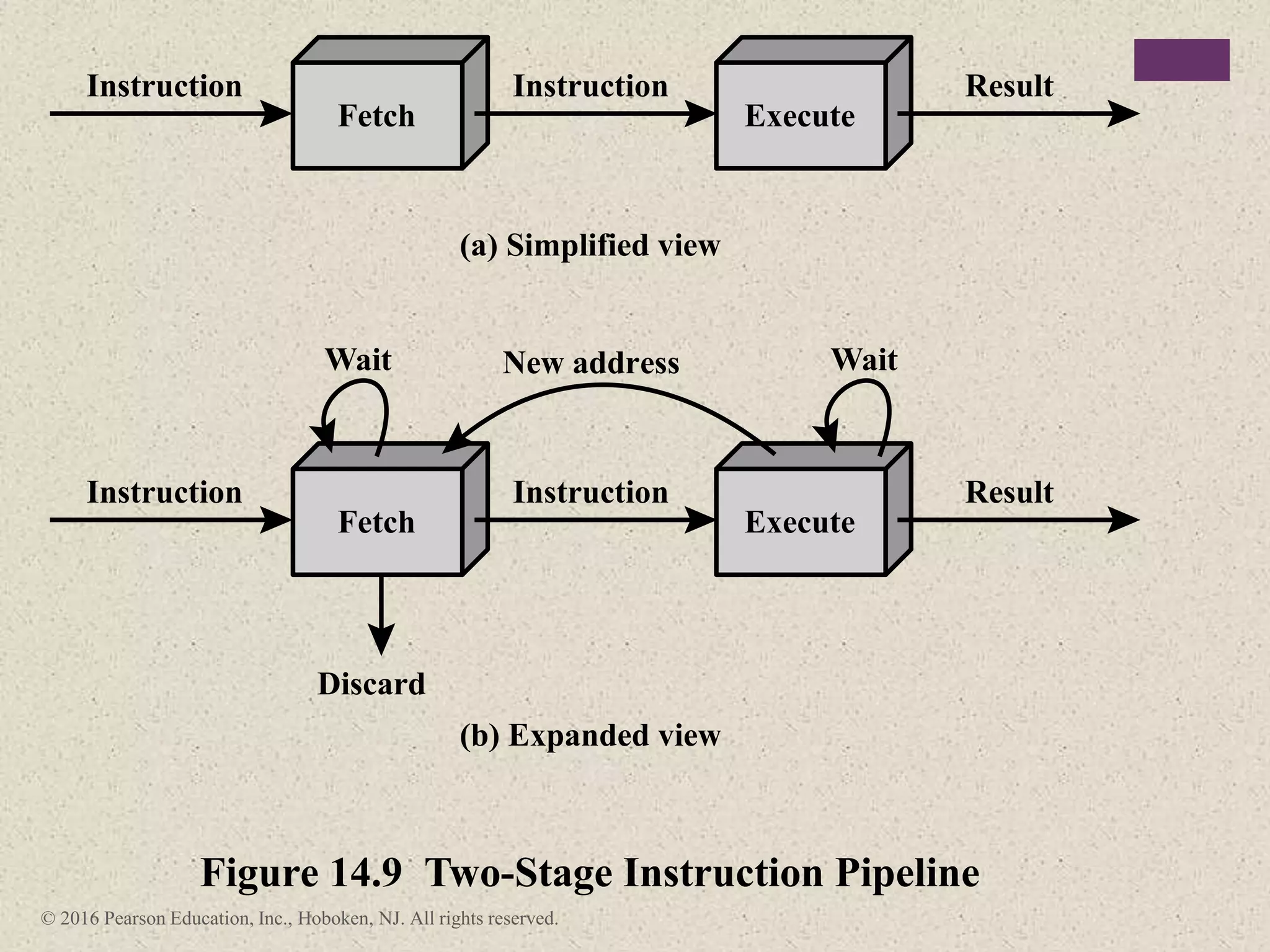
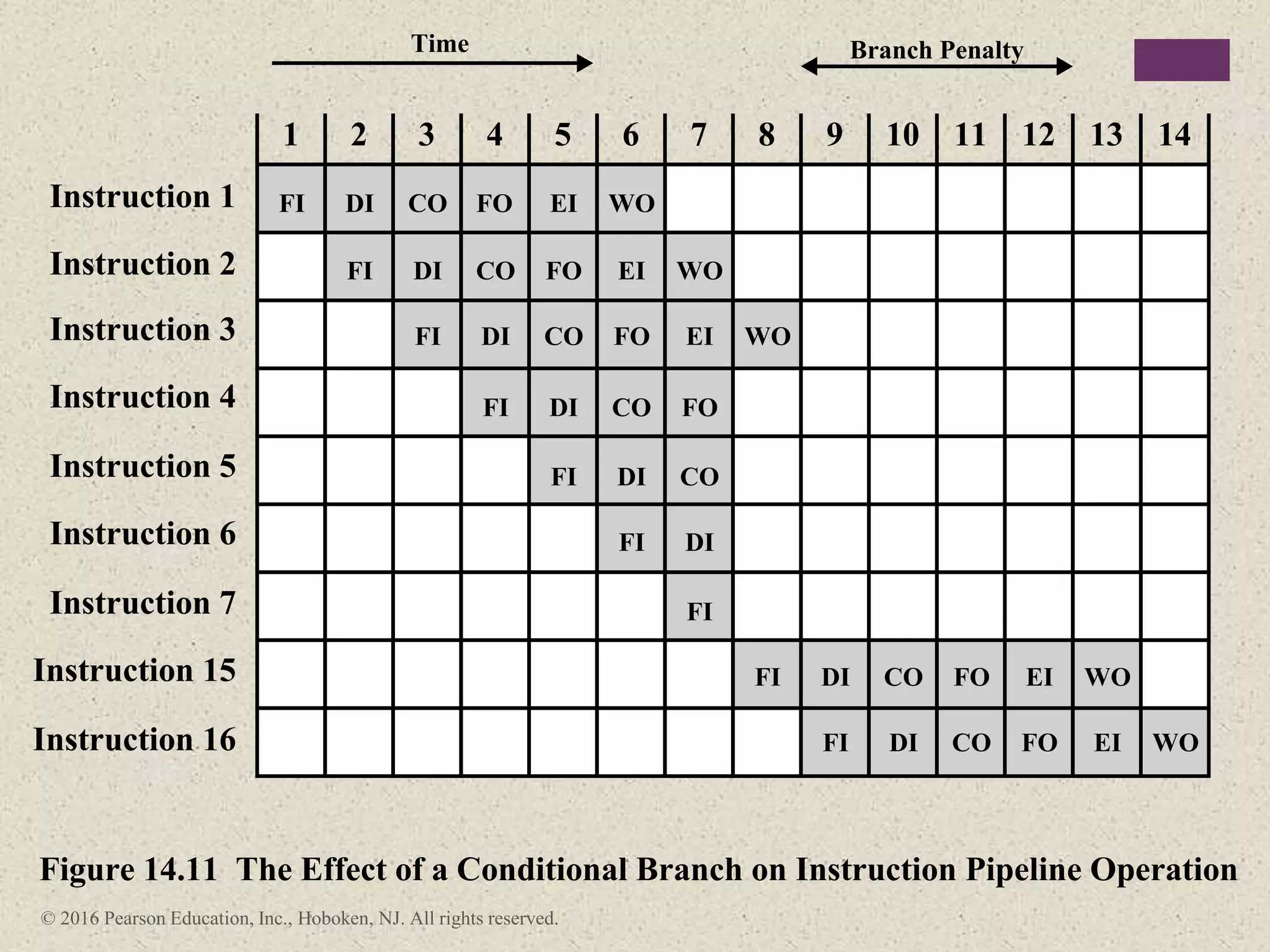
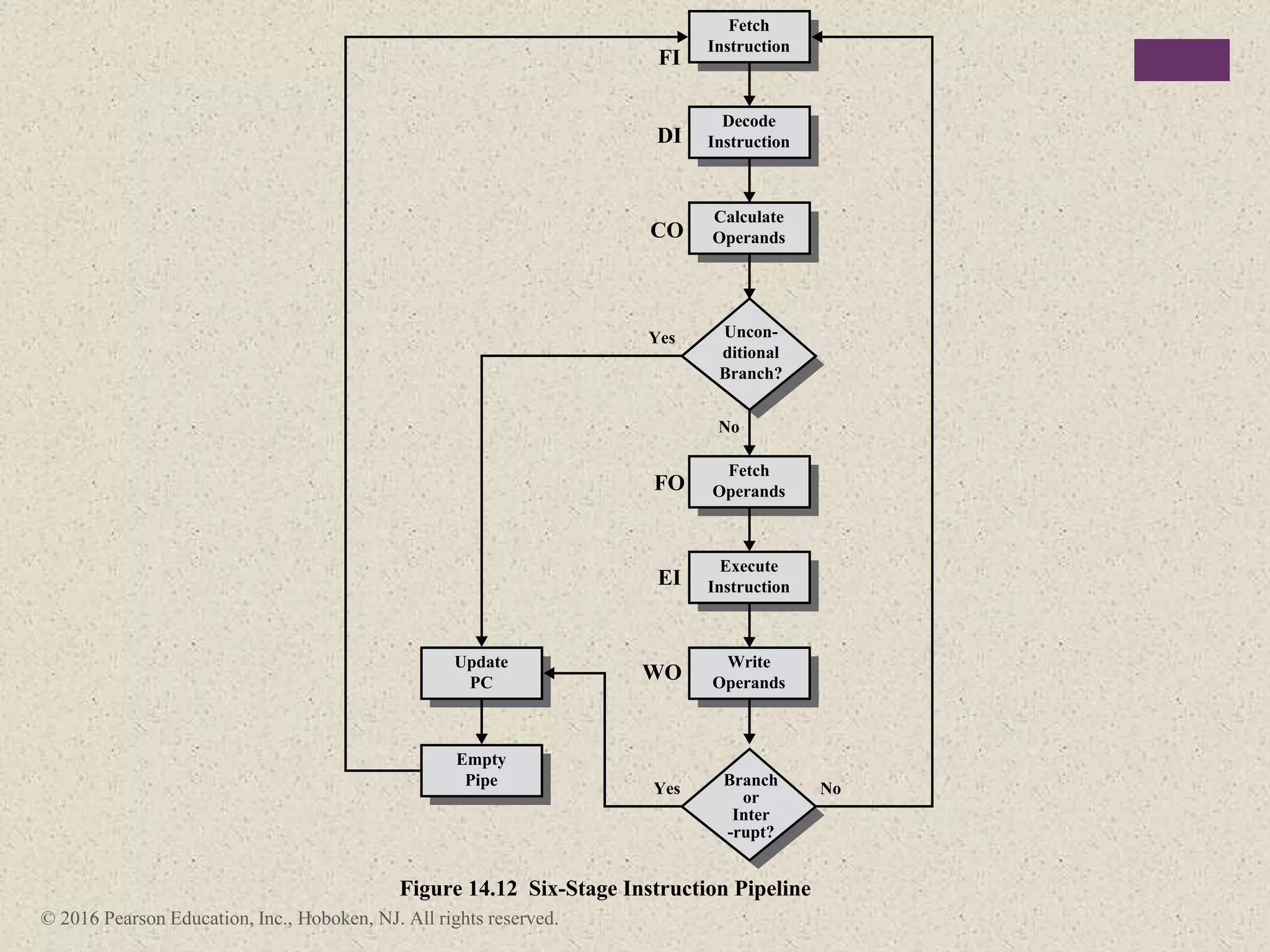
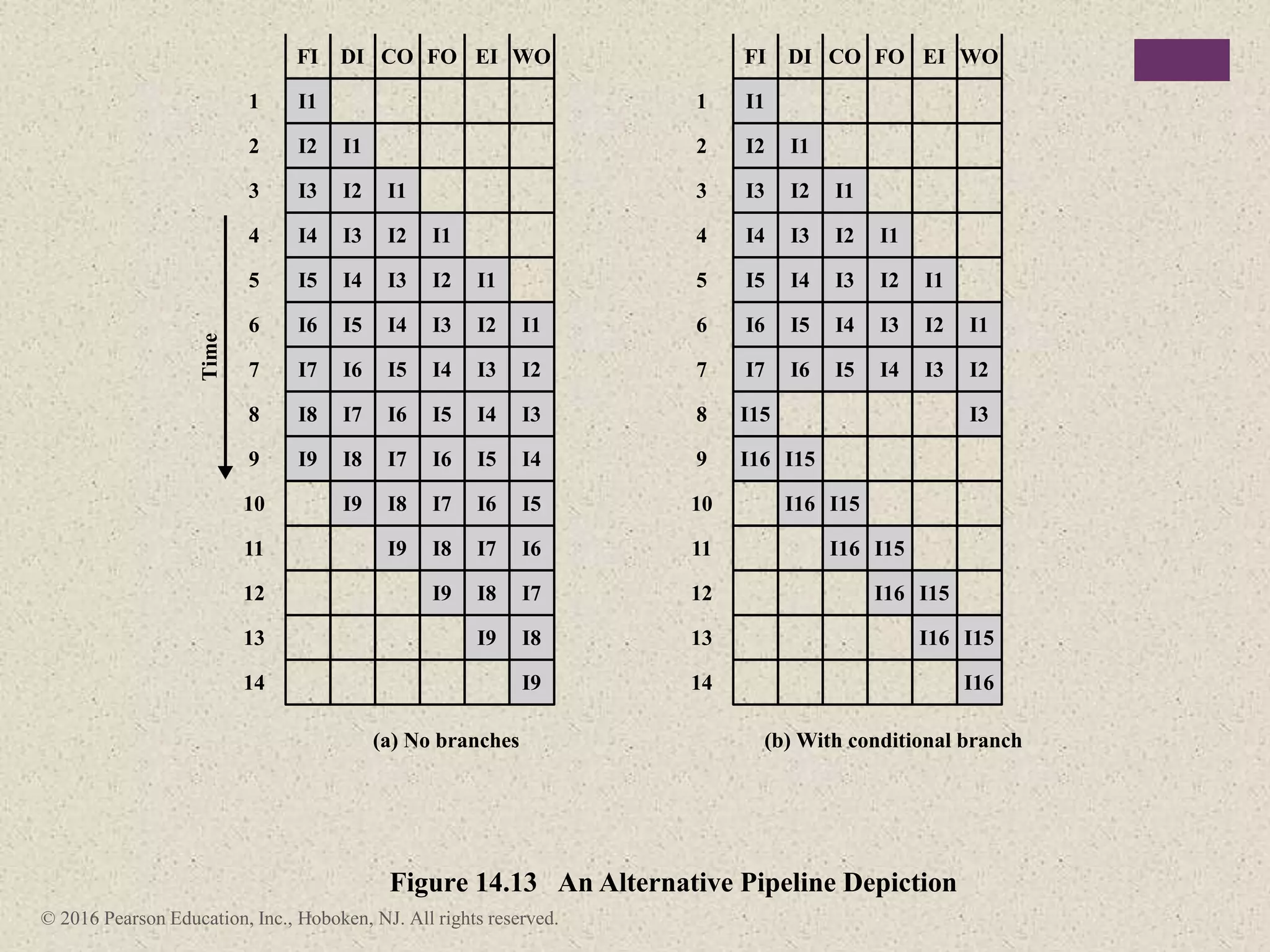
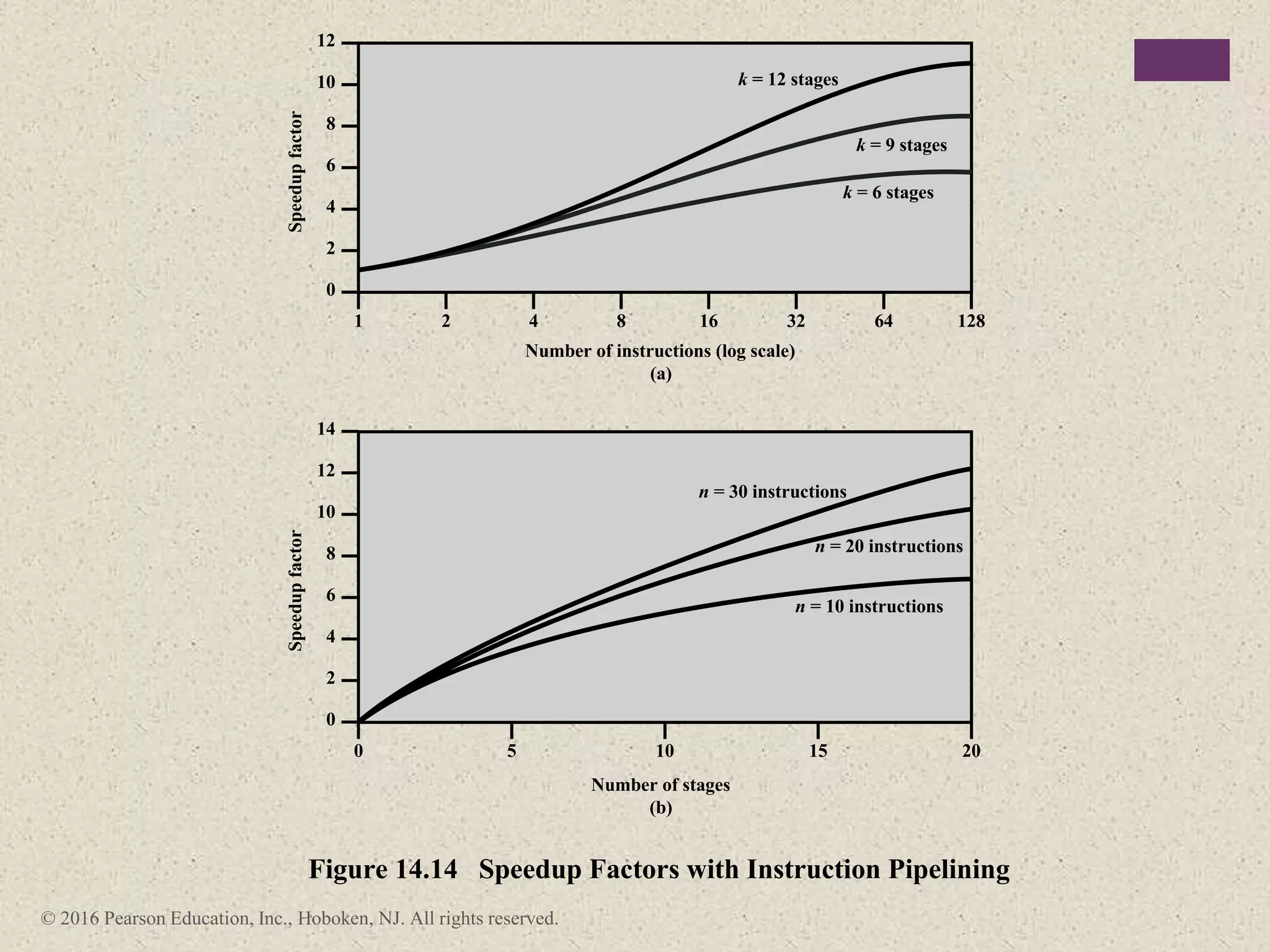
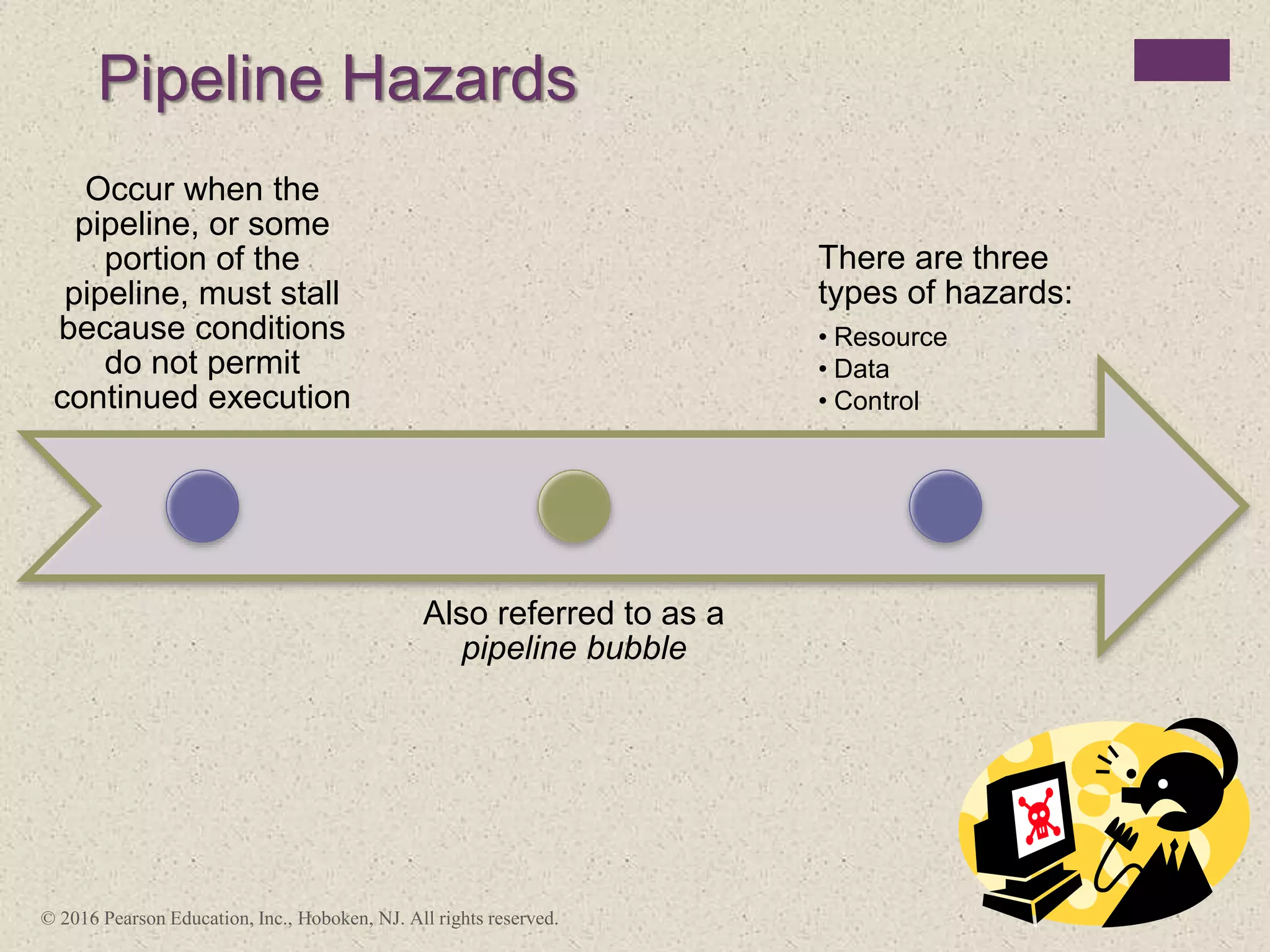
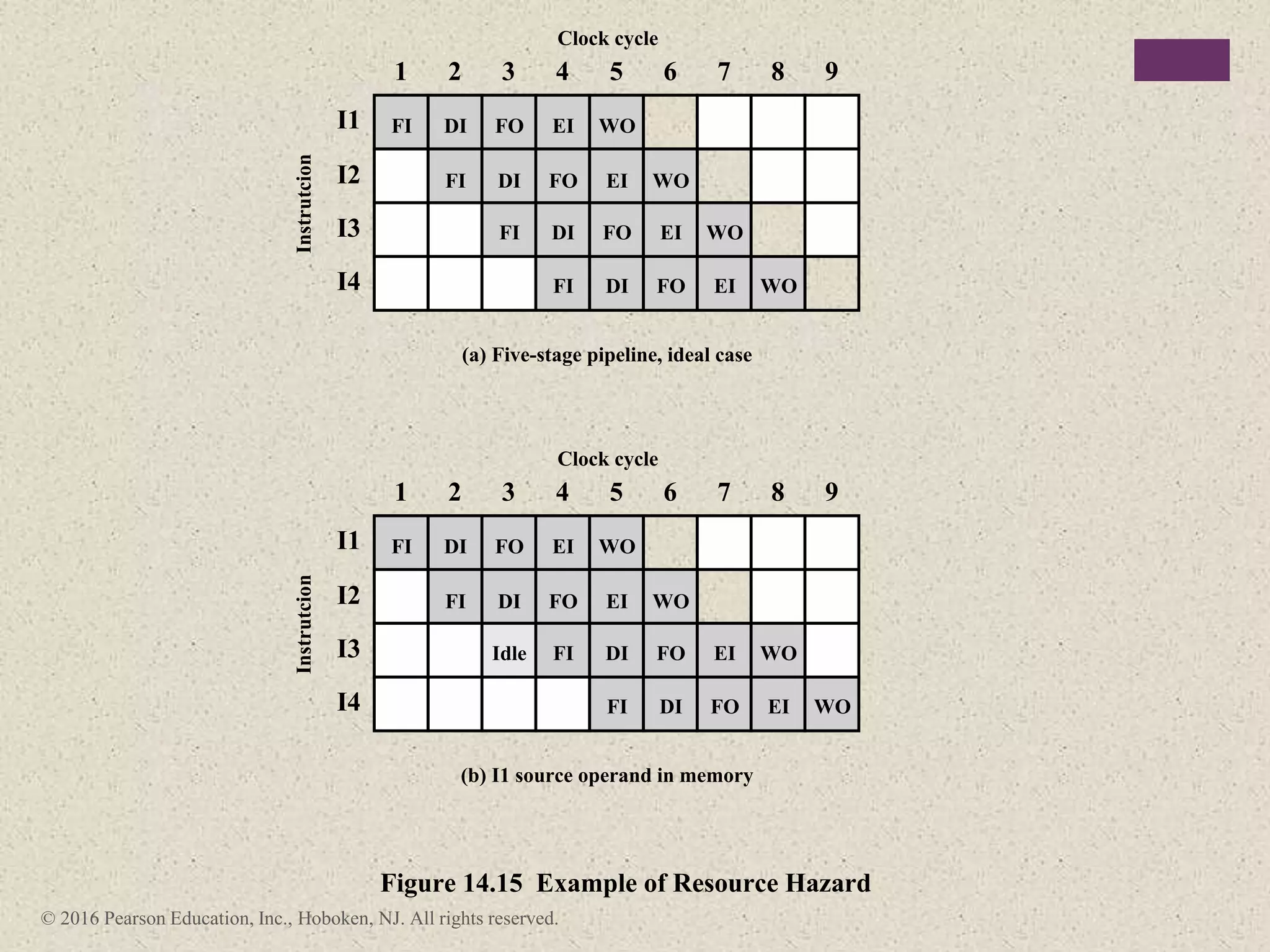
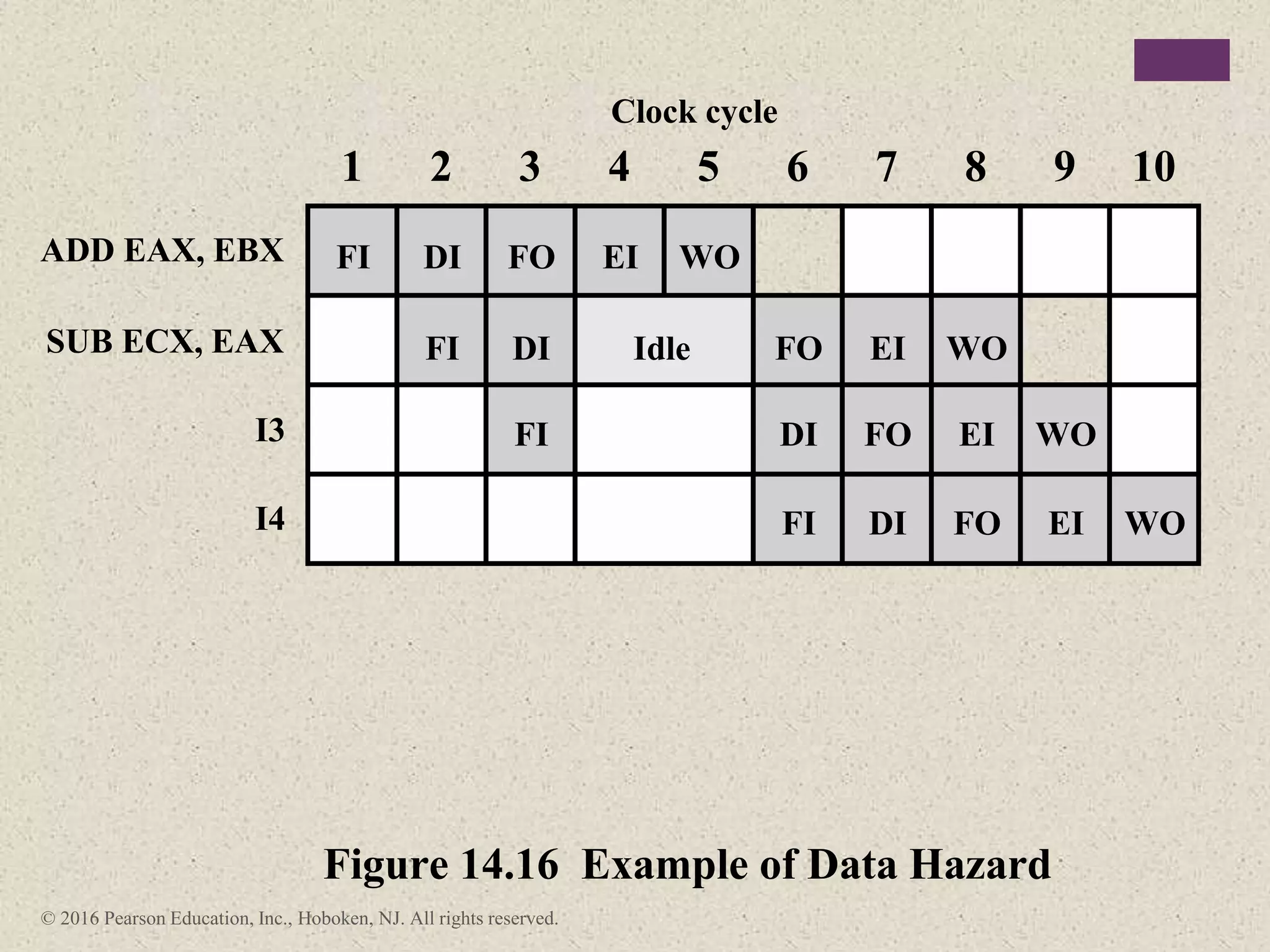
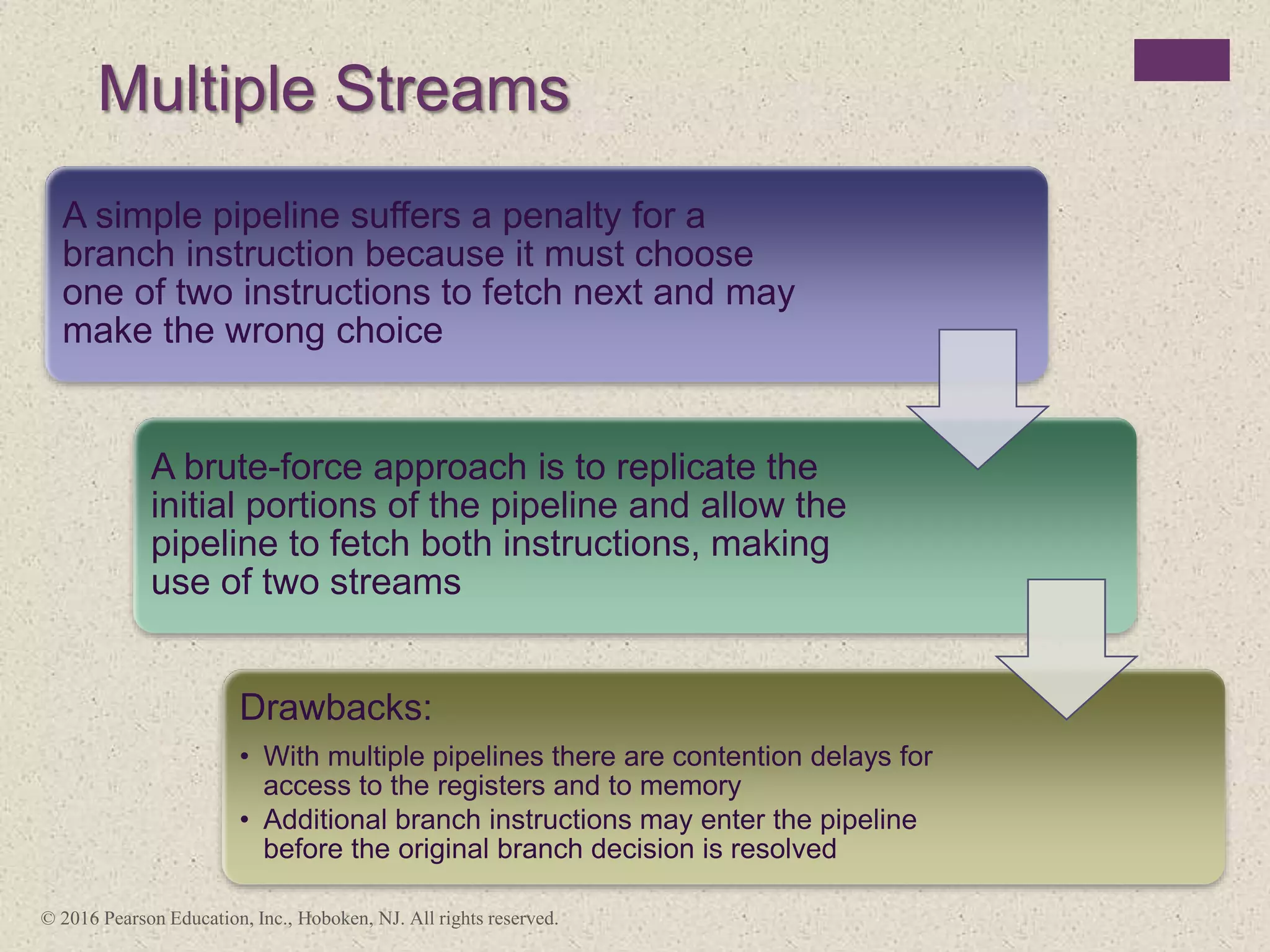
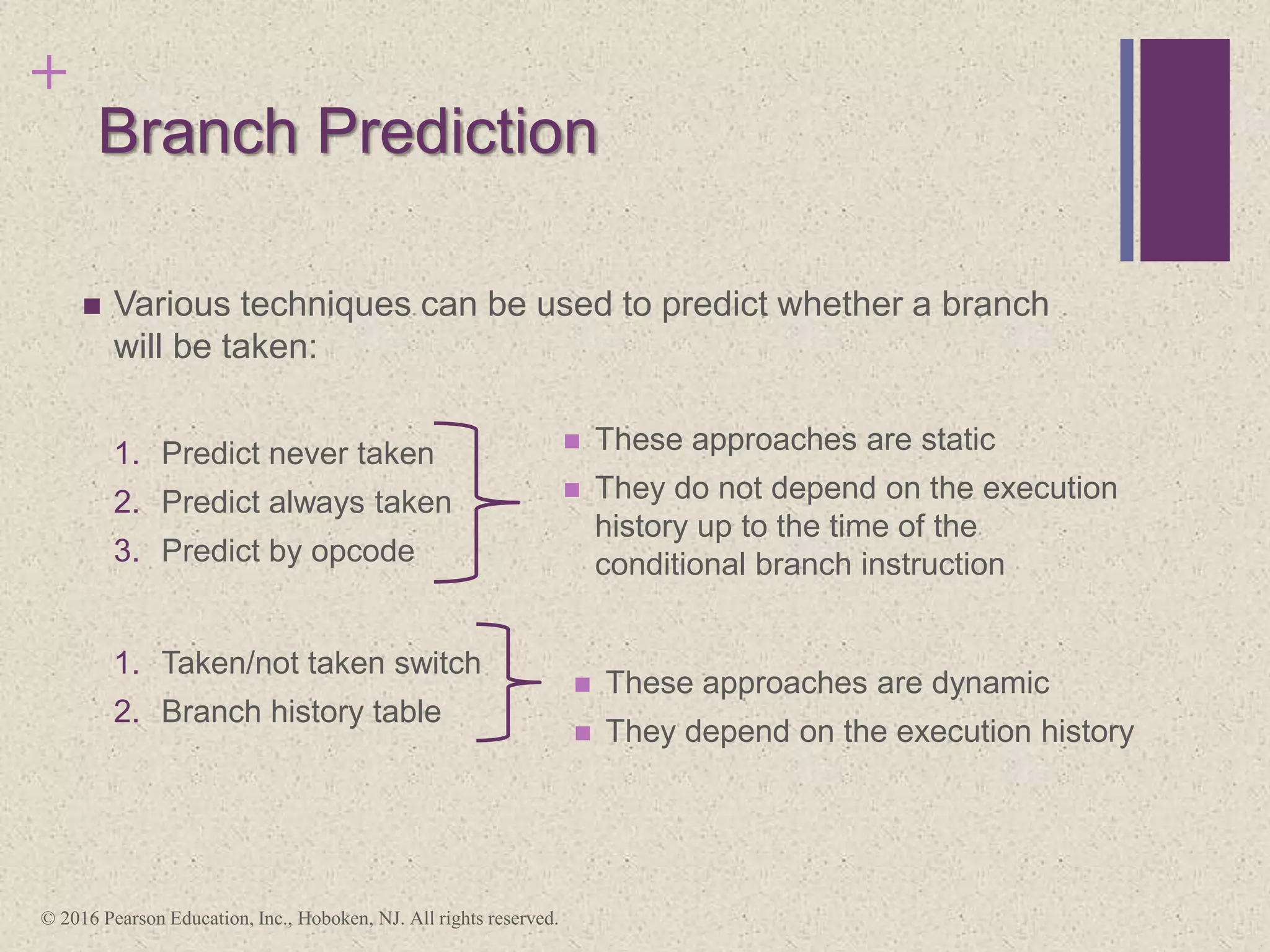
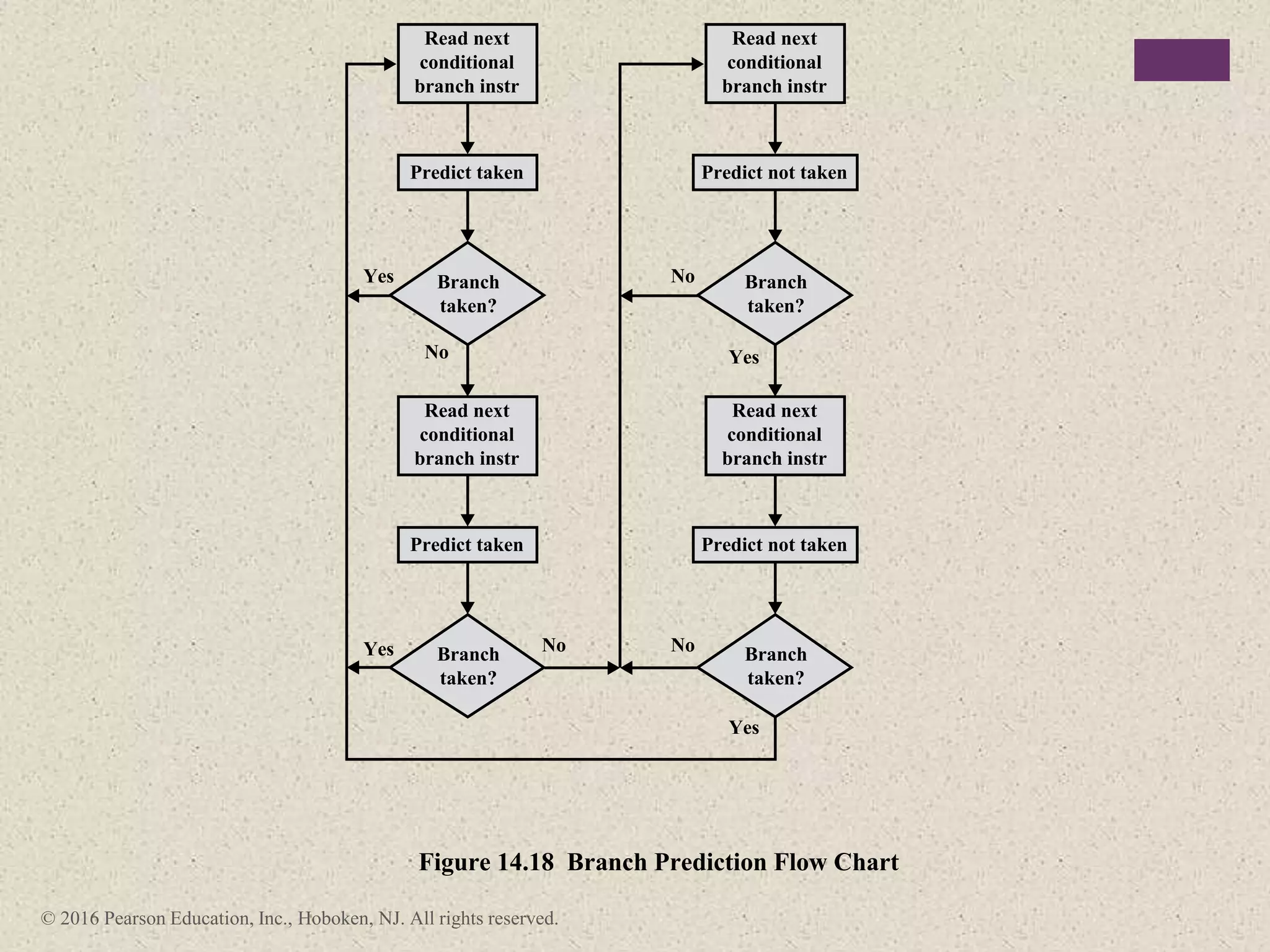
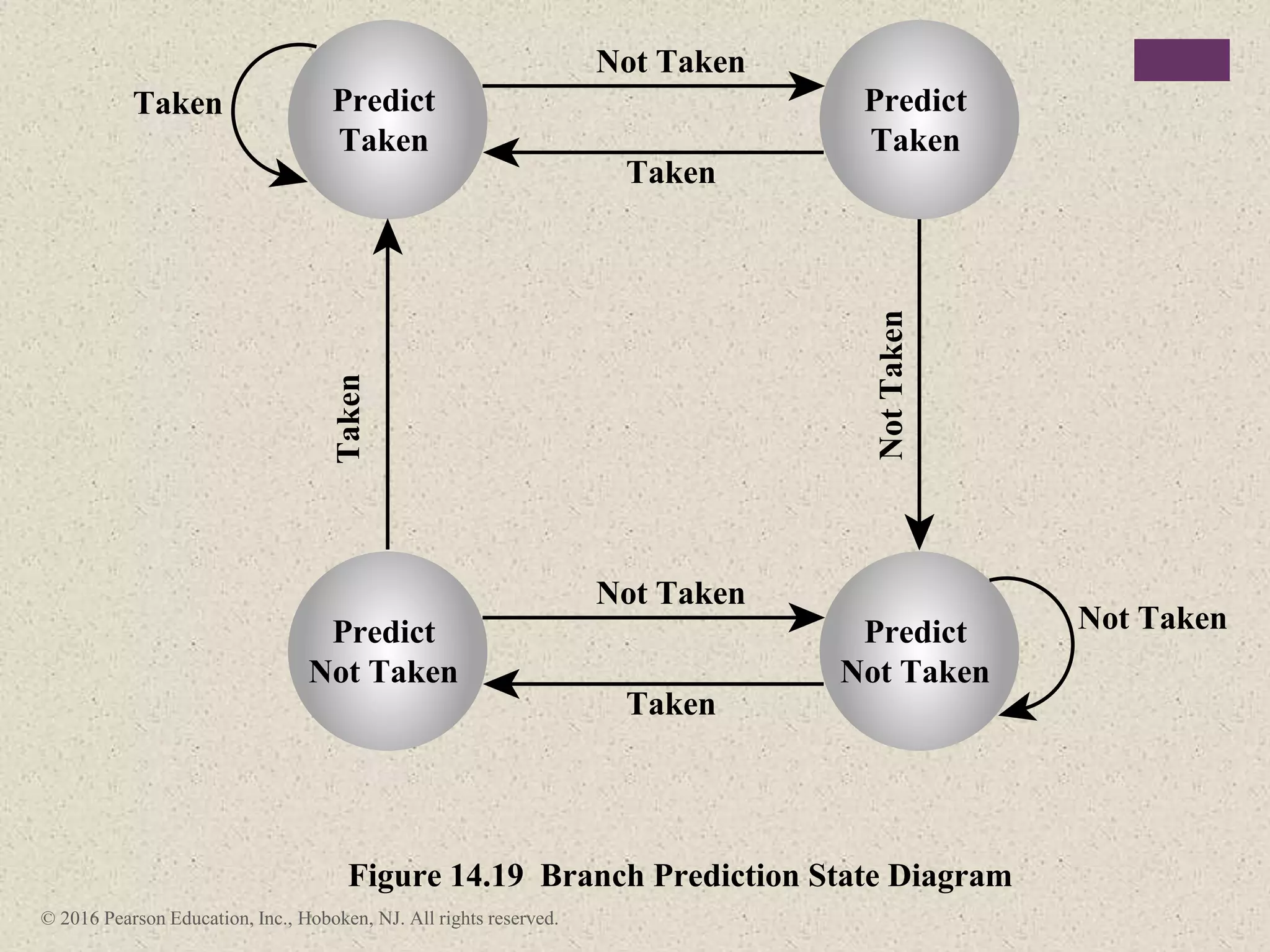
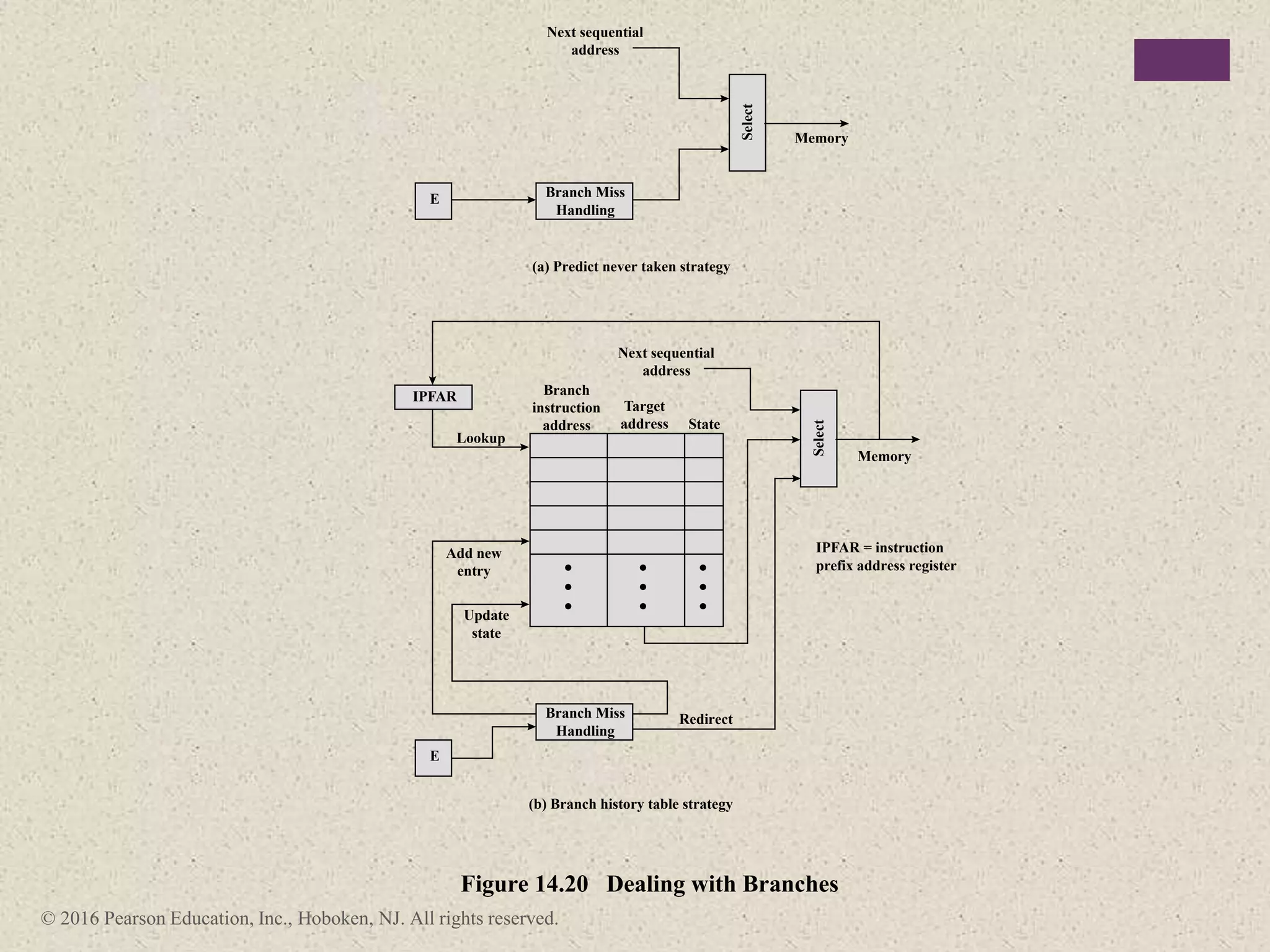
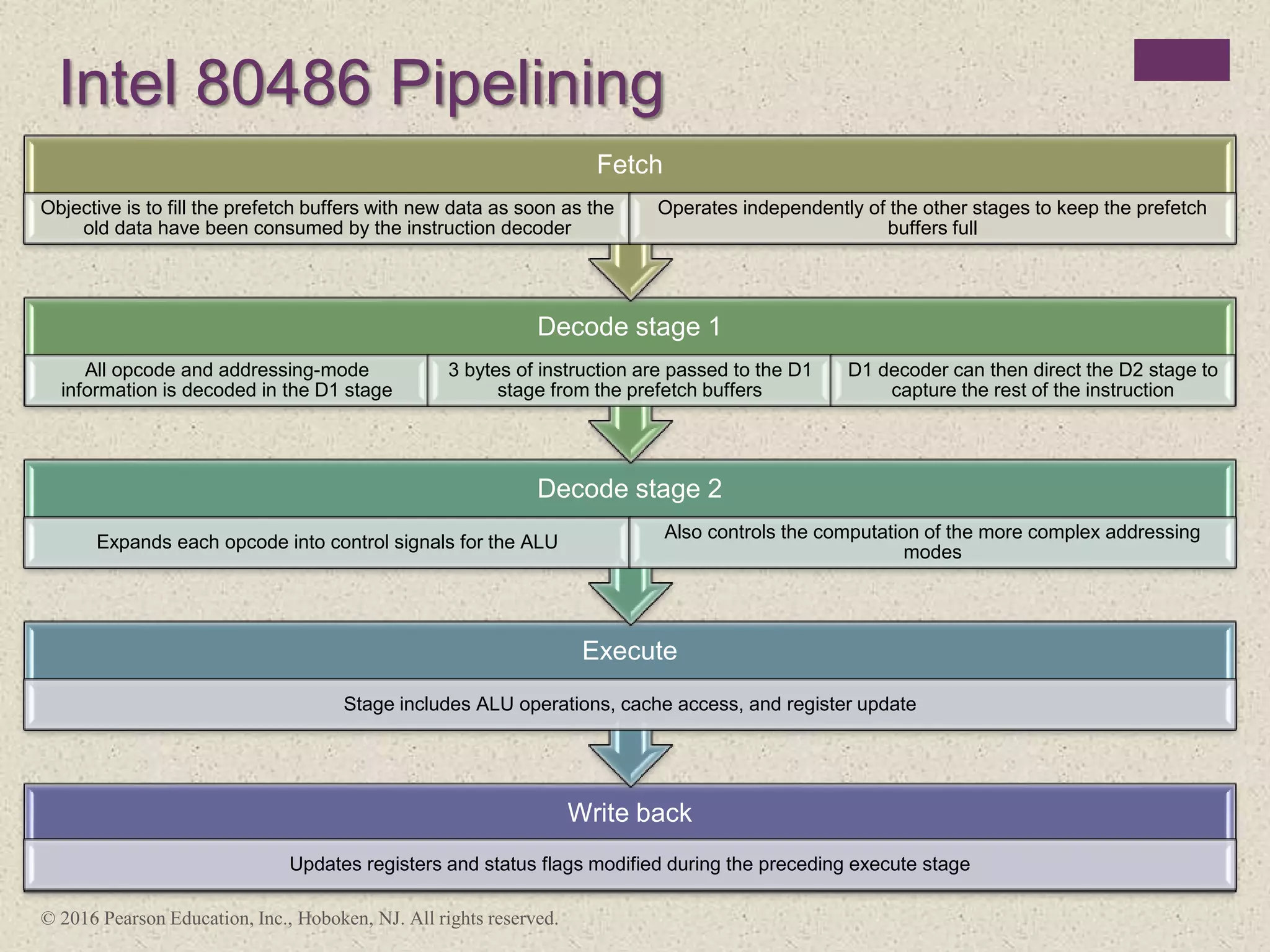
The document discusses instruction pipelining strategies for improving processor performance. It describes how pipelining works by overlapping the execution of multiple instructions by breaking down the instruction execution process into discrete stages. This allows new instructions to enter the pipeline before previous instructions have finished executing. The document outlines several techniques for dealing with pipeline hazards such as resource conflicts, data dependencies, and branches including branch prediction algorithms. It provides examples of how different processors implement pipelining.