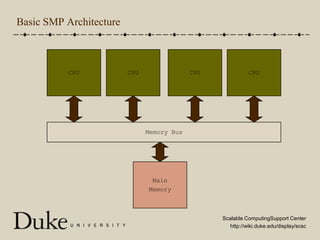
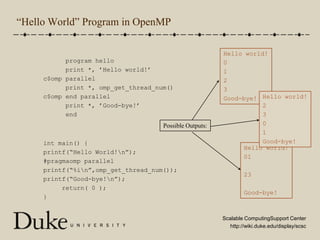
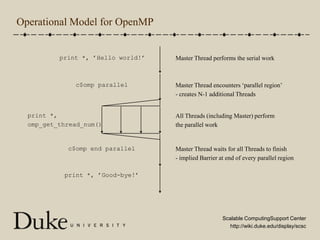
OpenMP is an industry-standard set of compiler directives and library routines that facilitate parallel programming in shared-memory environments, allowing programmers to write parallel code with minimal complexity. It operates by creating multiple threads to execute tasks, while managing synchronization and data sharing challenges, such as race conditions and critical sections. The document provides an overview of OpenMP syntax, parallel constructs, and practical examples, outlining how to compile programs and optimize performance with threads.








![Loop ParallelismLoop-level parallelism is the most common approach to extracting parallel work from a computer programE.g. you probably have lots of loops in your program that iterate over very large arrays:Instead of 1 CPU handling all 1,000,000 entries, we use N threads which each handle (1,000,000/N) entries do i = 1, 1000000 y(i) = alpha*x(i) + y(i) enddofor(i=0;i<1000000;i++) { y[i] = alpha*x[i] + y[i]}c$omp parallel do do i = 1, 1000000 y(i) = alpha*x(i) + y(i) enddoc$omp end parallel#pragma omp parallel forfor(i=0;i<1000000;i++) { y[i] = alpha*x[i] + y[i]}](https://image.slidesharecdn.com/openmpnoanim-12799113531705-phpapp02/85/Intro-to-OpenMP-12-320.jpg)
![Loop Parallelism, cont’dc$omp parallel do do i = 1, 1000000 y(i) = alpha*x(i) + y(i) enddoc$omp end parallel#pragma omp parallel forfor(i=0;i<1000000;i++) { y[i] = alpha*x[i] + y[i]}The compiler inserts code to compute the loop bounds for each threadFor 10 threads, thread 0 works on i = 1 to 100,000; thread 1 works on 100,001 to 200,000, etc.Since this is a shared memory environment, every thread can “see” all data items in all arrays … so we don’t have to coordinate each thread’s loop bounds with it’s portion of each arrayThis often makes it easier to program in OpenMP than MPI](https://image.slidesharecdn.com/openmpnoanim-12799113531705-phpapp02/85/Intro-to-OpenMP-13-320.jpg)




![A More Complex Loop do i = 1, 100 do j = 1, 100x = (i-1)/100y = (j-1)/100d(i,j) = mandelbrot(x,y)enddoenddofor(i=0;i<100;i++) { for(j=0;j<100;j++) { x = i/100; y = j/100; d[i][j] = mandelbrot(x,y); }}Now, there is a function call inside the inner-most loop](https://image.slidesharecdn.com/openmpnoanim-12799113531705-phpapp02/85/Intro-to-OpenMP-18-320.jpg)
![A More Complex Loop, cont’dc$omp parallel do do i = 1, 100 do j = 1, 100x = (i-1)/100y = (j-1)/100d(i,j) = mandelbrot(x,y)enddoenddoc$omp end parallel#pragma omp parallel forfor(i=0;i<100;i++) { for(j=0;j<100;j++) { x = i/100; y = j/100; d[i][j] = mandelbrot(x,y); }}Any problems? (what is the value of ‘x’?)](https://image.slidesharecdn.com/openmpnoanim-12799113531705-phpapp02/85/Intro-to-OpenMP-19-320.jpg)

![Private vs. Shared Variables, cont’dOpenMP allows the programmer to specify if additional variables need to be Private to each ThreadThis is specified as a “clause” to the c$omp or #pragma line:c$omp parallel do private(j,x,y) do i = 1, 100 do j = 1, 100 x = (i-1)/100 y = (j-1)/100 d(i,j) = mandelbrot(x,y) enddo enddoc$omp end parallel#pragma omp parallel for \ private(j,x,y)for(i=0;i<100;i++) { for(j=0;j<100;j++) { x = i/100; y = j/100; d[i][j] = mandelbrot(x,y); }}](https://image.slidesharecdn.com/openmpnoanim-12799113531705-phpapp02/85/Intro-to-OpenMP-22-320.jpg)

![Mixing Shared and Private VariablesWhat if we want to accumulate the total count from all of the mandelbrot() calculations? total = 0c$omp parallel do private(j,x,y) do i = 1, 100 do j = 1, 100 x = (i-1)/100 y = (j-1)/100 d(i,j) = mandelbrot(x,y) total = total + d(i,j) enddo enddoc$omp end paralleltotal = 0;#pragma omp parallel for \ private(j,x,y)for(i=0;i<100;i++) { for(j=0;j<100;j++) { x = i/100; y = j/100; d[i][j] = mandelbrot(x,y); total += d[i][j]; }}We want ‘total’ to be shared (not private) … which is the default](https://image.slidesharecdn.com/openmpnoanim-12799113531705-phpapp02/85/Intro-to-OpenMP-24-320.jpg)

![Synchronization … Critical SectionsOpenMP allows user-defined Critical SectionsOnly ONE THREAD at a time is allowed in a Critical SectionNote that Critical Sections imply SERIAL computationPARALLEL performance will likely be reduced! total = 0c$omp parallel do private(j,x,y) do i = 1, 100 do j = 1, 100x = (i-1)/100y = (j-1)/100d(i,j) = mandelbrot(x,y)c$omp critical total = total + d(i,j)c$omp end criticalenddoenddoc$omp end paralleltotal = 0;#pragma omp parallel for \ private(j,x,y)for(i=0;i<100;i++) { for(j=0;j<100;j++) { x = i/100; y = j/100; d[i][j] = mandelbrot(x,y);#pragma omp critical total += d[i][j]; }}](https://image.slidesharecdn.com/openmpnoanim-12799113531705-phpapp02/85/Intro-to-OpenMP-26-320.jpg)




![“Very Small” Critical SectionsIn some cases, we may use critical reasons to provide locks on small increments to a global counter, or other “small” computationWe don’t really care what the value is, we just want to increment itWhat we really want is an ‘atomic’ update of that global variableThis uses unique hardware features on the CPU, so it is very fastBut there is a limit to what can be done#pragma omp parallel for for(i=0;i<1000000;i++) {#pragma omp atomic sum += a[i]; }c$omp parallel do do i = 1, 1000000c$omp atomic sum = sum + a(i)enddoc$omp end parallel](https://image.slidesharecdn.com/openmpnoanim-12799113531705-phpapp02/85/Intro-to-OpenMP-31-320.jpg)

![Synchronization … Reduction OperationsWhere Critical Sections can be any arbitrary piece of code, OpenMP also allows for optimized routines for certain standard operationsAccumulate across all Threads, Min across all Threads, etc.Called a “Reduction” Operation total = 0c$omp parallel do private(j,x,y)c$omp+ reduction(+:total) do i = 1, 100 do j = 1, 100x = (i-1)/100y = (j-1)/100d(i,j) = mandelbrot(x,y) total = total + d(i,j)enddoenddoc$omp end paralleltotal = 0;#pragmaomp parallel for \private(j,x,y) \reduction(+:total)for(i=0;i<100;i++) {for(j=0;j<100;j++) {x = i/100;y = j/100;d[i][j] = mandelbrot(x,y); total += d[i][j]; }}](https://image.slidesharecdn.com/openmpnoanim-12799113531705-phpapp02/85/Intro-to-OpenMP-33-320.jpg)




![OpenMP and Function Calls total = 0c$omp parallel do private(j,x,y) do i = 1, 100 do j = 1, 100 x = (i-1)/100 y = (j-1)/100 d(i,j) = mandelbrot(x,y)c$omp critical total = total + d(i,j)c$omp end critical enddo enddoc$omp end paralleltotal = 0;#pragma omp parallel for \ private(j,x,y)for(i=0;i<100;i++) { for(j=0;j<100;j++) { x = i/100; y = j/100; d[i][j] = mandelbrot(x,y);#pragma omp critical total += d[i][j]; }}What happens inside the mandelbrot() function?Are variables defined inside mandelbrot() private or shared?](https://image.slidesharecdn.com/openmpnoanim-12799113531705-phpapp02/85/Intro-to-OpenMP-38-320.jpg)









![Basic TipsOpenMP is built for large-loop parallelism with little synchronizationIf your loops require tight synchronization, you may have a hard time programming it in OpenMPIt is sometimes easier to have a single (outer) OpenMP parallel-for loop which makes function calls to a “worker” routine This kind of loopcan be pipelinedfor(i=0;i<N;i++) { a[i] = 0.5*( a[i-1] + b[i] );}c$omp parallel do private(x) do i=1,N x = i*0.1 call DoWork( x ) enddo](https://image.slidesharecdn.com/openmpnoanim-12799113531705-phpapp02/85/Intro-to-OpenMP-49-320.jpg)
![One “Big” Parallel Region vs. Several Smaller Onesc$omp parallel do do i = 1, N y(i) = alpha*x(i) + y(i) enddoc$omp end parallel . . .c$omp parallel do do i = 1, N z(i) = beta*y(i) + z(i) enddoc$omp end parallel#pragma omp parallel forfor(i=0;i<N;i++) { y[i] = alpha*x[i] + y[i]}. . .#pragma omp parallel forfor(i=0;i<N;i++) { z[i] = beta*y[i] + z[i];}Each parallel region has an implied barrier (high cost)](https://image.slidesharecdn.com/openmpnoanim-12799113531705-phpapp02/85/Intro-to-OpenMP-50-320.jpg)
![One “Big” Parallel Region, cont’dc$omp parallel c$omp do do i = 1, N y(i) = alpha*x(i) + y(i) enddoc$omp enddo . . .c$omp do do i = 1, N z(i) = beta*y(i) + z(i) enddoc$omp enddoc$omp end parallel#pragma omp parallel{#pragma omp for for(i=0;i<N;i++) { y[i] = alpha*x[i] + y[i] }. . .#pragma omp for for(i=0;i<N;i++) { z[i] = beta*y[i] + z[i]; }} /* end of parallel region */This is still a parallel section](https://image.slidesharecdn.com/openmpnoanim-12799113531705-phpapp02/85/Intro-to-OpenMP-51-320.jpg)



![Small Loops, cont’dc$omp parallel do if(N>1000) do i = 1, Ny(i) = alpha*x(i) + y(i)enddoc$omp end parallel#pragma omp parallel for \ if(N>1000)for(i=0;i<N;i++) { y[i] = alpha*x[i] + y[i]}Where you should put this cut-off is entirely machine-dependent](https://image.slidesharecdn.com/openmpnoanim-12799113531705-phpapp02/85/Intro-to-OpenMP-55-320.jpg)










![Static Scheduling, cont’dc$omp parallel do schedule(static) do i = 1, 1000000 y(i) = alpha*x(i) + y(i) enddoc$omp end parallel#pragmaomp parallel for schedule(static)for(i=0;i<1000000;i++) {y[i] = alpha*x[i] + y[i]}If the per-iteration work-load is variable, or you are sharing the CPUs with many other users,then a dynamic scheduling algorithm (the default) may be better](https://image.slidesharecdn.com/openmpnoanim-12799113531705-phpapp02/85/Intro-to-OpenMP-66-320.jpg)


![Alternative Approach to OpenMP, cont’ddatasize = 1000000#pragmaomp parallel private(i,self_thr,num_thr,istart,ifinish) {self_thr = omp_get_thread_num();num_thr = omp_get_num_threads();istart = (self_thr-1)*(datasize/num_thr);ifinish = istart + (datasize/num_thr);for(i=istart;i<ifinish;i++) {y[i] = alpha*x[i] + y[i]; } }](https://image.slidesharecdn.com/openmpnoanim-12799113531705-phpapp02/85/Intro-to-OpenMP-69-320.jpg)