Download to read offline








![Specifying Parallel Regions
• Fortran !
$OMP PARALLEL [clause [clause…]]
! Block
of code executed by all threads
!$OMP END PARALLEL
• C and C++
#pragma omp parallel [clause [clause...]]
{
/* Block executed by all threads */](https://image.slidesharecdn.com/e06x5kxtreabmxjigvr6-signature-f43061a7db8d94aa9e293b85d96a2faeff7cf3535bbf93f2b2ff71999b5d49ab-poli-160324134237/85/Nbvtalkataitamimageprocessingconf-9-320.jpg)








![Scheduling
• Scheduling assigns the iterations of a
parallel loop to the team threads
• The directives [parallel] do and
[parallel] for take the clause
schedule(type [,chunk])
• The optional chunk is a loop-invariant
positive integer specifying the number
of contiguous iterations assigned to a
thread](https://image.slidesharecdn.com/e06x5kxtreabmxjigvr6-signature-f43061a7db8d94aa9e293b85d96a2faeff7cf3535bbf93f2b2ff71999b5d49ab-poli-160324134237/85/Nbvtalkataitamimageprocessingconf-19-320.jpg)




![Work Sharing Constructs
A motivating example
for(i=0;I<N;i++) { a[i] = a[i] + b[i];}
#pragma omp parallel
{
int id, i, Nthrds, istart, iend;
id = omp_get_thread_num();
Nthrds = omp_get_num_threads();
istart = id * N / Nthrds;
iend = (id+1) * N / Nthrds;
for(i=istart;I<iend;i++) {a[i]=a[i]+b[i];}
}
#pragma omp parallel
#pragma omp for schedule(static)
for(i=0;I<N;i++) { a[i]=a[i]+b[i];}
OpenMP
parallel region
and a work-
Sequential
code
OpenMP
Parallel Region
OpenMP Parallel
Region and a
work-sharing for
construct](https://image.slidesharecdn.com/e06x5kxtreabmxjigvr6-signature-f43061a7db8d94aa9e293b85d96a2faeff7cf3535bbf93f2b2ff71999b5d49ab-poli-160324134237/85/Nbvtalkataitamimageprocessingconf-24-320.jpg)
![Work-sharing ConstructWork-sharing Construct
Threads are assigned an
independent set of
iterations
Threads must wait at the
end of work-sharing
construct
#pragma omp parallel
#pragma omp for
Implicit barrier
i = 1
i = 2
i = 3
i = 4
i = 5
i = 6
i = 7
i = 8
i = 9
i = 10
i = 11
i = 12
#pragma omp parallel
#pragma omp for
for(i = 1, i < 13, i++)
c[i] = a[i] + b[i]](https://image.slidesharecdn.com/e06x5kxtreabmxjigvr6-signature-f43061a7db8d94aa9e293b85d96a2faeff7cf3535bbf93f2b2ff71999b5d49ab-poli-160324134237/85/Nbvtalkataitamimageprocessingconf-25-320.jpg)
![Combining pragmasCombining pragmas
These two code segments are equivalent
#pragma omp parallel
{
#pragma omp for
for (i=0;i< MAX; i++)
{ res[i]
= huge();
}
}
#pragma omp parallel for
for (i=0;i< MAX; i++) {
res[i] = huge();
}](https://image.slidesharecdn.com/e06x5kxtreabmxjigvr6-signature-f43061a7db8d94aa9e293b85d96a2faeff7cf3535bbf93f2b2ff71999b5d49ab-poli-160324134237/85/Nbvtalkataitamimageprocessingconf-26-320.jpg)







![Threadprivate Data
• threadprivate data can be initialized
in a thread using the copyin clause
associated with the parallel,
parallel do/for, and parallel
sections directives
• the value stored in the master thread
is copied into each team thread
• Syntax: copyin (name [,name])
where name is a variable or (in Fortran)
a named common block](https://image.slidesharecdn.com/e06x5kxtreabmxjigvr6-signature-f43061a7db8d94aa9e293b85d96a2faeff7cf3535bbf93f2b2ff71999b5d49ab-poli-160324134237/85/Nbvtalkataitamimageprocessingconf-34-320.jpg)












![Reality Check
Irregular and ambiguous aspects are
sources of language- and
implementation dependent behavior:
• nowait clause is allowed at the
beginning of [parallel] for (C/C+
+) but at the end of [parallel] DO
(Fortran)
• default clause can specify private
scope in Fortran, but not in C/C++](https://image.slidesharecdn.com/e06x5kxtreabmxjigvr6-signature-f43061a7db8d94aa9e293b85d96a2faeff7cf3535bbf93f2b2ff71999b5d49ab-poli-160324134237/85/Nbvtalkataitamimageprocessingconf-47-320.jpg)


![Compiling and Running
• Use MIPSpro with the option -mp both for
compiling and linking
default -MP:open_mp=ON must be in effect
• Fortran:
f90 [-freeform] [-cpp]-mp prog.f
-freeform needed for free form source
-cpp needed when using #ifdef s
• C/C++:
cc -mp -O3 prog.c
CC -mp -O3 prog.C](https://image.slidesharecdn.com/e06x5kxtreabmxjigvr6-signature-f43061a7db8d94aa9e293b85d96a2faeff7cf3535bbf93f2b2ff71999b5d49ab-poli-160324134237/85/Nbvtalkataitamimageprocessingconf-50-320.jpg)



















![• Regular distribution
!$SGI distribute a(d1[,d2])
[onto(p1[,p2])]
#pragma distribute a[d1][[d2]] [onto(p1[,p2])]
• Reshaped distribution
!$SGI distribute_reshape a(d1[,d2]) [onto(p1[,p2])]
#pragma distribute_reshape a[d1][[d2]]
• Distribution methods are denoted by d1, d2
• Optional clause onto specifies a processor
grid n1 x n2 , such that n1/n2 = p1/p2
SGI Data Placement Directives](https://image.slidesharecdn.com/e06x5kxtreabmxjigvr6-signature-f43061a7db8d94aa9e293b85d96a2faeff7cf3535bbf93f2b2ff71999b5d49ab-poli-160324134237/85/Nbvtalkataitamimageprocessingconf-71-320.jpg)



![• Assumed size is not allowed for array
formal parameters which are declared
as distributed
• Specify array size:
void foo(int n, double a[n])
{
#pragma distribute_reshape a(block)
…
}
Distributed Arrays as
Formal Parameters](https://image.slidesharecdn.com/e06x5kxtreabmxjigvr6-signature-f43061a7db8d94aa9e293b85d96a2faeff7cf3535bbf93f2b2ff71999b5d49ab-poli-160324134237/85/Nbvtalkataitamimageprocessingconf-75-320.jpg)
![If a reshaped array is declared as
threadprivate, the compiler will
silently ignore the threadprivate
directive
» threadprivate is quietly ignored:
double a[n]
#pragma omp threadprivate(a)
#pragma distribute_reshape a(block)
Reshaped Array Pitfall](https://image.slidesharecdn.com/e06x5kxtreabmxjigvr6-signature-f43061a7db8d94aa9e293b85d96a2faeff7cf3535bbf93f2b2ff71999b5d49ab-poli-160324134237/85/Nbvtalkataitamimageprocessingconf-76-320.jpg)



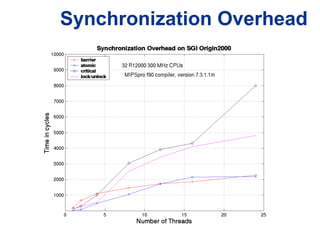







![Types of Data Dependencies
• Reduction operations:
const int n = 4096;
int a[n], i, sum=0;
for (i = 0; i < n; i++) {
sum += a[i];
}
– Easy to parallelize using reduction
variables](https://image.slidesharecdn.com/e06x5kxtreabmxjigvr6-signature-f43061a7db8d94aa9e293b85d96a2faeff7cf3535bbf93f2b2ff71999b5d49ab-poli-160324134237/85/Nbvtalkataitamimageprocessingconf-89-320.jpg)
![Types of Data Dependencies
– Auto-parallelizer is able to detect
reduction and parallelize it
const int n = 4096;
int a[n], i, sum = 0;
#pragma omp parallel for reduction(+:sum)
for (i = 0; i < n; i++) {
sum += a[i];
}](https://image.slidesharecdn.com/e06x5kxtreabmxjigvr6-signature-f43061a7db8d94aa9e293b85d96a2faeff7cf3535bbf93f2b2ff71999b5d49ab-poli-160324134237/85/Nbvtalkataitamimageprocessingconf-90-320.jpg)
![Types of Data Dependencies
• Carried dependence on a shared
array, e.g., recurrence:
const int n = 4096;
int a[n], i;
for (i = 0; i < n-1; i++) {
a[i] = a[i+1];
}
– Non-trivial to eliminate, the auto-
parallelizer cannot do it](https://image.slidesharecdn.com/e06x5kxtreabmxjigvr6-signature-f43061a7db8d94aa9e293b85d96a2faeff7cf3535bbf93f2b2ff71999b5d49ab-poli-160324134237/85/Nbvtalkataitamimageprocessingconf-91-320.jpg)
![Parallelizing the Recurrence
#define N 16384
int a[N], work[N+1];
// Save border element
work[N]= a[0];
// Save & shift even indices
#pragma omp parallel for
for ( i = 2; i < N; i+=2)
{
work[i-1] = a[i];
}
// Update even indices from odd
#pragma omp parallel for
for ( i = 0; i < N-1; i+=2)
{
a[i] = a[i+1];
}
// Update odd indices with even
#pragma omp parallel for
for ( i = 1; i < N-1; i+=2)
{
a[i] = work[i];
}
// Set border element
a[N-1] = work[N];
Idea: Segregate even and odd indices](https://image.slidesharecdn.com/e06x5kxtreabmxjigvr6-signature-f43061a7db8d94aa9e293b85d96a2faeff7cf3535bbf93f2b2ff71999b5d49ab-poli-160324134237/85/Nbvtalkataitamimageprocessingconf-92-320.jpg)
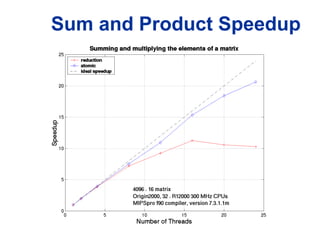
![Performing Reduction
The bad scalability of the reduction clause
affects its usefulness, e.g., bad speedup
when summing the elements of a matrix:
#define N 1<<12
#define M 16
int i, j;
double a[N][M], sum = 0.0;
#pragma omp parallel for reduction(+:sum)
for (i = 0; i < N; i++)
for (j = 0; j < M; j++)
sum += a[i][j];](https://image.slidesharecdn.com/e06x5kxtreabmxjigvr6-signature-f43061a7db8d94aa9e293b85d96a2faeff7cf3535bbf93f2b2ff71999b5d49ab-poli-160324134237/85/Nbvtalkataitamimageprocessingconf-93-320.jpg)
![Parallelizing the Sum
#define N 1<<12
#define M 16
int main() {
double a[N][M], sum = 0.0;
#pragma distribute a[block][*]
int i, j = 0;
#pragma omp parallel private(i,j)
{
double mysum = 0.0;
// initialization of a
// not shown
// compute partial sum
#pragma omp for nowait
for (i = 0; i < N; i++)
for (j = 0; j < M; i++)
mysum += a[i][j];
}
// each thread adds its
// partial sum
#pragma omp atomic
sum += mysum;
}
}
Idea: Use explicit partial sums and combine
them atomically](https://image.slidesharecdn.com/e06x5kxtreabmxjigvr6-signature-f43061a7db8d94aa9e293b85d96a2faeff7cf3535bbf93f2b2ff71999b5d49ab-poli-160324134237/85/Nbvtalkataitamimageprocessingconf-94-320.jpg)











![Perfex Tool
perfex -mp [other options] a.out
• To profile secondary cache misses in the
data cache (event 26) and instruction
cache (event 10):
perfex -mp -e 26 -e 10 a.out
• To multiplex all 32 events (-a) , get time
estimates (-y) and trace exceptions (-x)
perfex -a -x -y a.out](https://image.slidesharecdn.com/e06x5kxtreabmxjigvr6-signature-f43061a7db8d94aa9e293b85d96a2faeff7cf3535bbf93f2b2ff71999b5d49ab-poli-160324134237/85/Nbvtalkataitamimageprocessingconf-107-320.jpg)







![Data Profiling: dprof
• Syntax
dprof [-hwpc [-cntr n] [-ovfl m]]
[-itimer [-ms t]] [-out profile_file]
a.out
• Default is interval timer ( -itimer )
with t=100 ms
• Can select hardware counter (-hwpc)
which has the defaults
n = 0 is the R1X000 cycle counter
m=10000 is the counter’s overflow value](https://image.slidesharecdn.com/e06x5kxtreabmxjigvr6-signature-f43061a7db8d94aa9e293b85d96a2faeff7cf3535bbf93f2b2ff71999b5d49ab-poli-160324134237/85/Nbvtalkataitamimageprocessingconf-115-320.jpg)


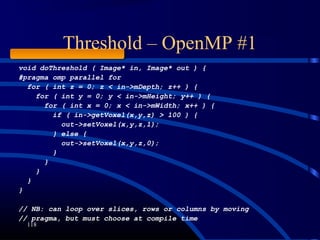
![Threshold – OpenMP #2
119
void doThreshold ( Image* in, Image* out ) {
#pragma omp parallel for
for ( int s = 0; s < in->mVoxelsPerVolume; s++ ) {
if ( in->mData[s] > 100 ) {
out->mData[s] = 1;
} else {
out->mData[s] = 0;
}
}
}
// Likely a lot faster than previous code](https://image.slidesharecdn.com/e06x5kxtreabmxjigvr6-signature-f43061a7db8d94aa9e293b85d96a2faeff7cf3535bbf93f2b2ff71999b5d49ab-poli-160324134237/85/Nbvtalkataitamimageprocessingconf-119-320.jpg)


This document provides an overview of writing OpenMP programs on multi-core machines. It discusses: 1) Why OpenMP is useful for parallel programming and its main components like compiler directives and library routines. 2) Elements of OpenMP like parallel regions, work sharing constructs, data scoping, and synchronization methods. 3) Achieving scalable speedup through techniques like breaking data dependencies, avoiding synchronization overheads, and improving data locality with cache and page placement.


































































































