Download to read offline



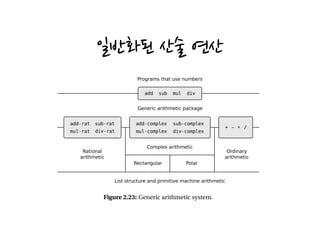






















The document describes a generic arithmetic system that allows uniform access to number packages with different data representations. It defines generic arithmetic procedures like add, sub, mul, and div that apply the corresponding operation for the specific number package. A scheme-number package for integer arithmetic is also installed. Generic tags are attached to values to identify their representation, and a mapping table is used to dispatch operations to appropriate handler procedures based on tags.























































































