DBRD의 설정
/etc/drbd.conf
resource r0{
protocol A;
on ws1 { # 호스트 명
device /dev/drbd0;
disk /dev/sdb1;
address 192.168.0.201:7789;
meta-disk internal;
}
on ws2 {
device /dev/drbd0;
disk /dev/sdb1;
address 192.168.0.202:7789;
meta-disk internal;
}
사용가능 프로토콜
A: 로컬 디스크에 쓰기가 끝나고 TCP 버퍼에
쓰기가 완료된 시점에서 쓰기 작업이 완료
B: 로컬 디스크에 쓰기가 끝나고 원격 호스트로
데이터가 도달한 시점에서 쓰기 작업이 완료
C: 원격 호스트의 디스크에도 쓰기가 완료된
시점에서 쓰기 작업이 완료
13년 4월 23일 화요일
16.
DBRD의 실행
Master
1. DRBD실행
2.primary 상태로 변경
3. /dev/drbd0 에 파일 시스템 생성
4. /dev/drbd0 을 마운트
Secondary
실행시 기본적으로 Secondary 상태임
13년 4월 23일 화요일
17.
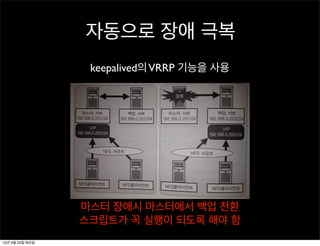
수동으로 장애 극복
백업전환 스크립트
#!/bin/sh
/etc/init.d/nfs-kernel-server stop
umount /mnt/drbd0
drbdadm secondary all
마스터 전환 스크립트
#!/bin/sh
drbdadm primary all
mount /dev/drbd0 /mnt/drbd0
/etc/init.d/nfs-kernel-server start
1. 마스터 서버의 DRBD를 secondary 상태로 변경
- 블록 디바이스가 마운트 되어 있으면 실패 함
2. 백업 서버를 master 상태로 변경하고 마운트
13년 4월 23일 화요일
NFS 서버를 장애극복시 주의할 점
새롭게 마스터가 된 NFS 서버는
어떠한 클라이언트에서도 마운트 되지 않은 상태임
- NFS 클라이언트는 서버 전환 유무를 알지 못함
- 서버는 클라이언트가 마운트되지 않았다고 판단
해결책
1. /var/lib/nfs/ 를 동기화
- 접속 정보를 미러링
2. nfsd 파일 시스템을 이용
- 마운트되지 않은 요청도 마운트 된 것 처럼 처리
13년 4월 23일 화요일
20.
이게 끝이 아니다.
DRBD는블록 디바이스를 미러링.
누군가 실수로 지운 파일을 복구가 안됨.
매일은 아니더라도 최악의 사태를
대비한 백업이 필요
13년 4월 23일 화요일
L1, L2에 레벨에장애가 발생한다면?
랜 카드, 케이블 등..
13년 4월 23일 화요일
24.
네트워크 장애 포인트
1.LAN 케이블
2. 네트워크 카드
3. 네트워크 스위치의 포트
4. 네트워크 스위치
1~3 장애: 링크 장애
4 장애: 스위치 장애
스위치간 접속시 1, 3 장애: 스위치간 접속 장애
13년 4월 23일 화요일
25.
링크 다중화
서버와 스위치사이의 접속을 다중화
서버에서 NIC을 여러개 사용하고,
LAN 케이블도 같은 수 만큼 연결
13년 4월 23일 화요일
26.
NIC 마다 IP가틀린데, 그럼 장애시
다른 IP로 접속을 해야 하나?
13년 4월 23일 화요일
27.
여러 물리 네트워크카드를 모아서 하나의
논리적인 네트워크 카드로 다룰 수 있게 함
Bonding 드라이버
13년 4월 23일 화요일
28.
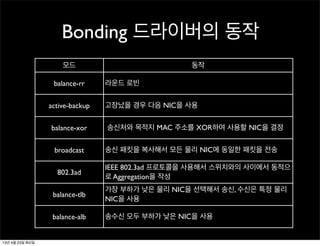
Bonding 드라이버의 동작
모드동작
balance-rr 라운드 로빈
active-backup 고장났을 경우 다음 NIC을 사용
balance-xor 송신처와 목적지 MAC 주소를 XOR하여 사용할 NIC을 결정
broadcast 송신 패킷을 복사해서 모든 물리 NIC에 동일한 패킷을 전송
802.3ad
IEEE 802.3ad 프로토콜을 사용해서 스위치와의 사이에서 동적으
로 Aggregation을 작성
balance-tlb
가장 부하가 낮은 물리 NIC을 선택해서 송신, 수신은 특정 물리
NIC을 사용
balance-alb 송수신 모두 부하가 낮은 NIC을 사용
13년 4월 23일 화요일
29.
MII 감시(Media IndependentInterface)
- 링크 다운되면 고장난 것으로 간주
ARP 감시(Address Resolution Protocol)
- ARP 요청을 보내고 응답이 오는지 감지하여 판단
Bonding 드라이버의
장애 탐지
13년 4월 23일 화요일
30.
스위치의 다중화
물리 NIC을묶어서 다중해 해도 동일한
스위치에 연결되어 있다면 스위치 장애에
대응할 수 없다
13년 4월 23일 화요일
31.
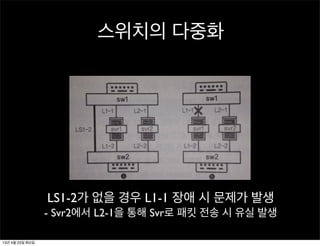
스위치의 다중화
LS1-2가 없을경우 L1-1 장애 시 문제가 발생
- Svr2에서 L2-1을 통해 Svr로 패킷 전송 시 유실 발생
13년 4월 23일 화요일
32.
링크를 이중화할 경우스위치의 포트 개수는
실질적으로 스위치 한 대분
서버 대수가 늘어나면 포트 수가 부족할 것
13년 4월 23일 화요일
33.
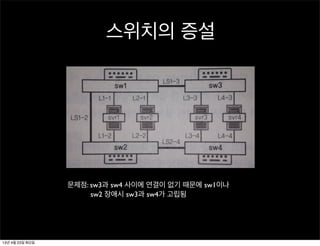
스위치의 증설
문제점: sw3과sw4 사이에 연결이 없기 때문에 sw1이나
sw2 장애시 sw3과 sw4가 고립됨
13년 4월 23일 화요일
34.
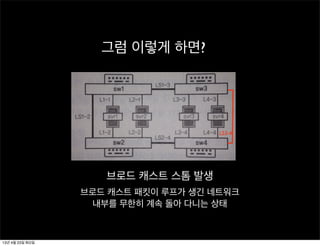
그럼 이렇게 하면?
브로드캐스트 스톰 발생
브로드 캐스트 패킷이 루프가 생긴 네트워크
내부를 무한히 계속 돌아 다니는 상태
LS3-4
13년 4월 23일 화요일
35.
RSTP
(Rapid Spanning TreeProtocol)
각 스위치가 협조해서 네트워크 상에서
생긴 루프를 검출하고, 다중화된 연결을 자동적으로
차단하기 위한 데이터 링크 계층의 프로토콜
13년 4월 23일 화요일
36.
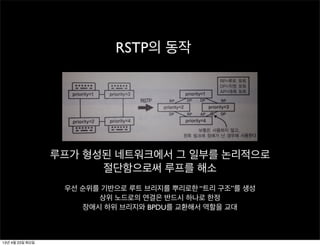
RSTP의 동작
루프가 형성된네트워크에서 그 일부를 논리적으로
절단함으로써 루프를 해소
우선 순위를 기반으로 루트 브리지를 뿌리로한 “트리 구조”를 생성
상위 노드로의 연결은 반드시 하나로 한정
장애시 하위 브리지와 BPDU를 교환해서 역할을 교대
13년 4월 23일 화요일
37.
Bonding 드라이버를 사용하면
서버와스위치 간의 접속을 다중화할 수 있음
이에 따라 포트 증설이 필요할 경우
RSTP를 지원하는 스위치를 사용하여
스위치 확장이 가능함.
13년 4월 23일 화요일


























































![3.[d2 오픈세미나]분산시스템 개발 및 교훈 n base arc](https://cdn.slidesharecdn.com/ss_thumbnails/3-140905000012-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


![[AWSKRUG] 모바일게임 하이브 런칭기 (2018)](https://cdn.slidesharecdn.com/ss_thumbnails/awskrugawsformobilegame-190419125248-thumbnail.jpg?width=640&height=640&fit=bounds)

































