Download to read offline


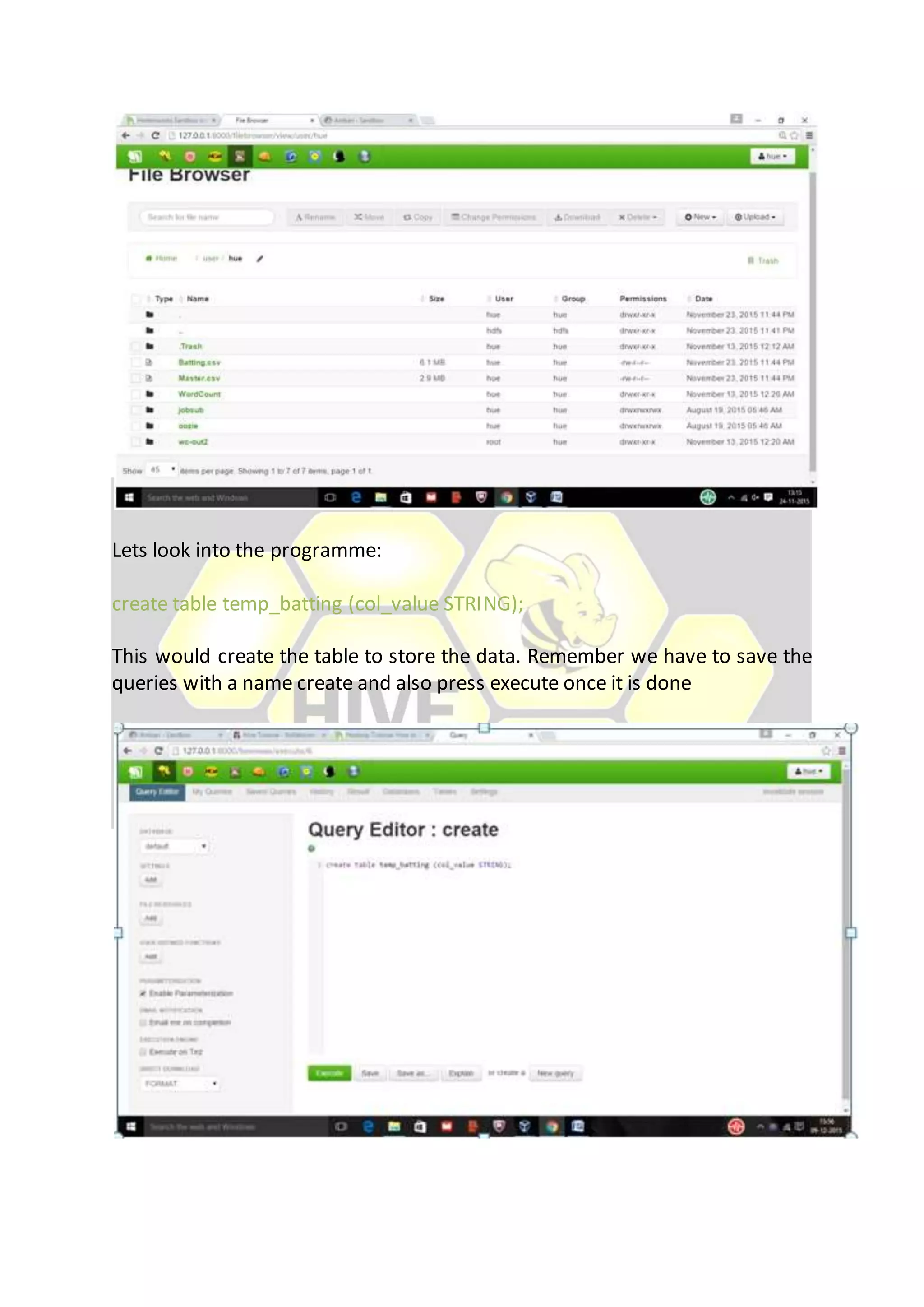
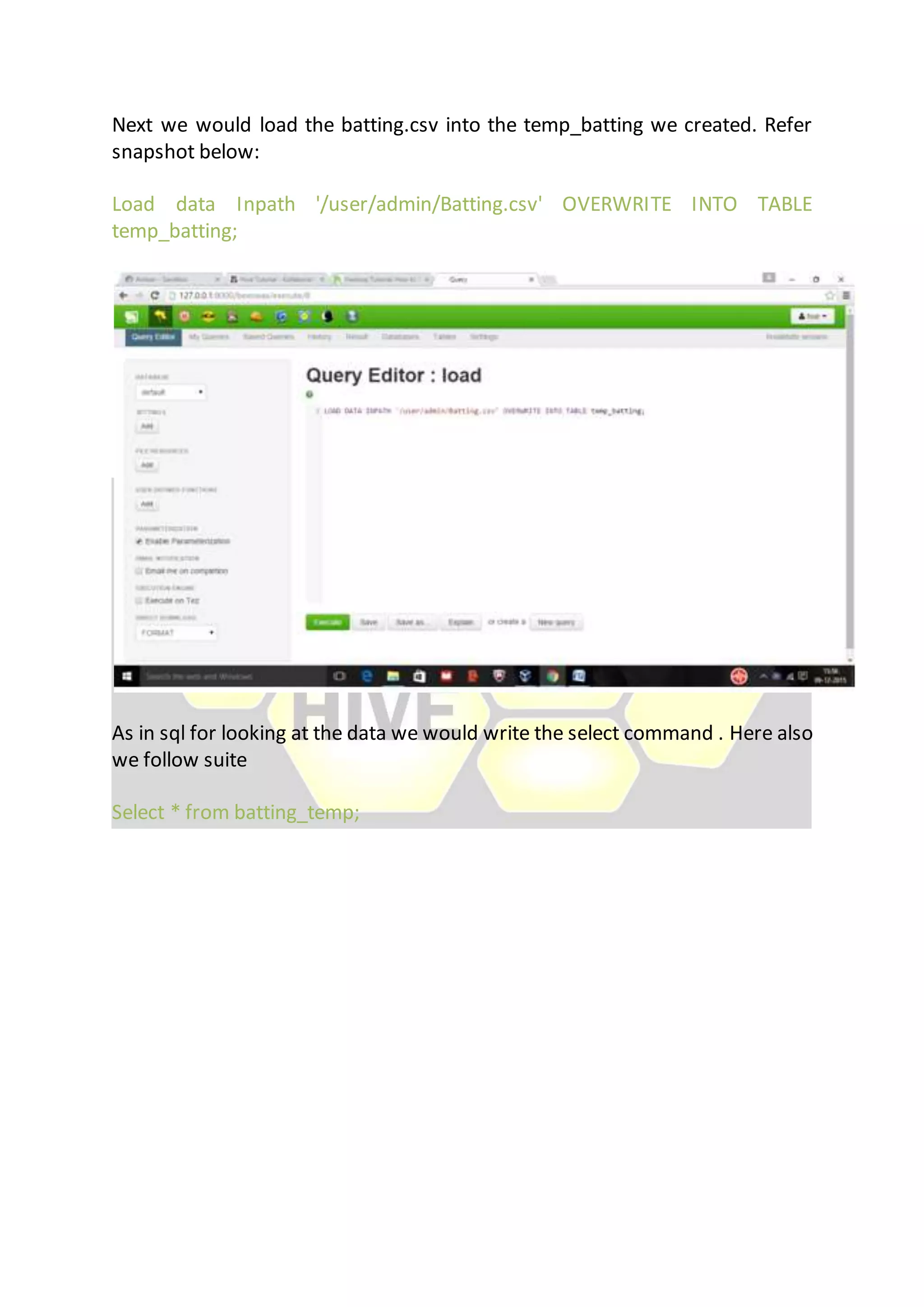
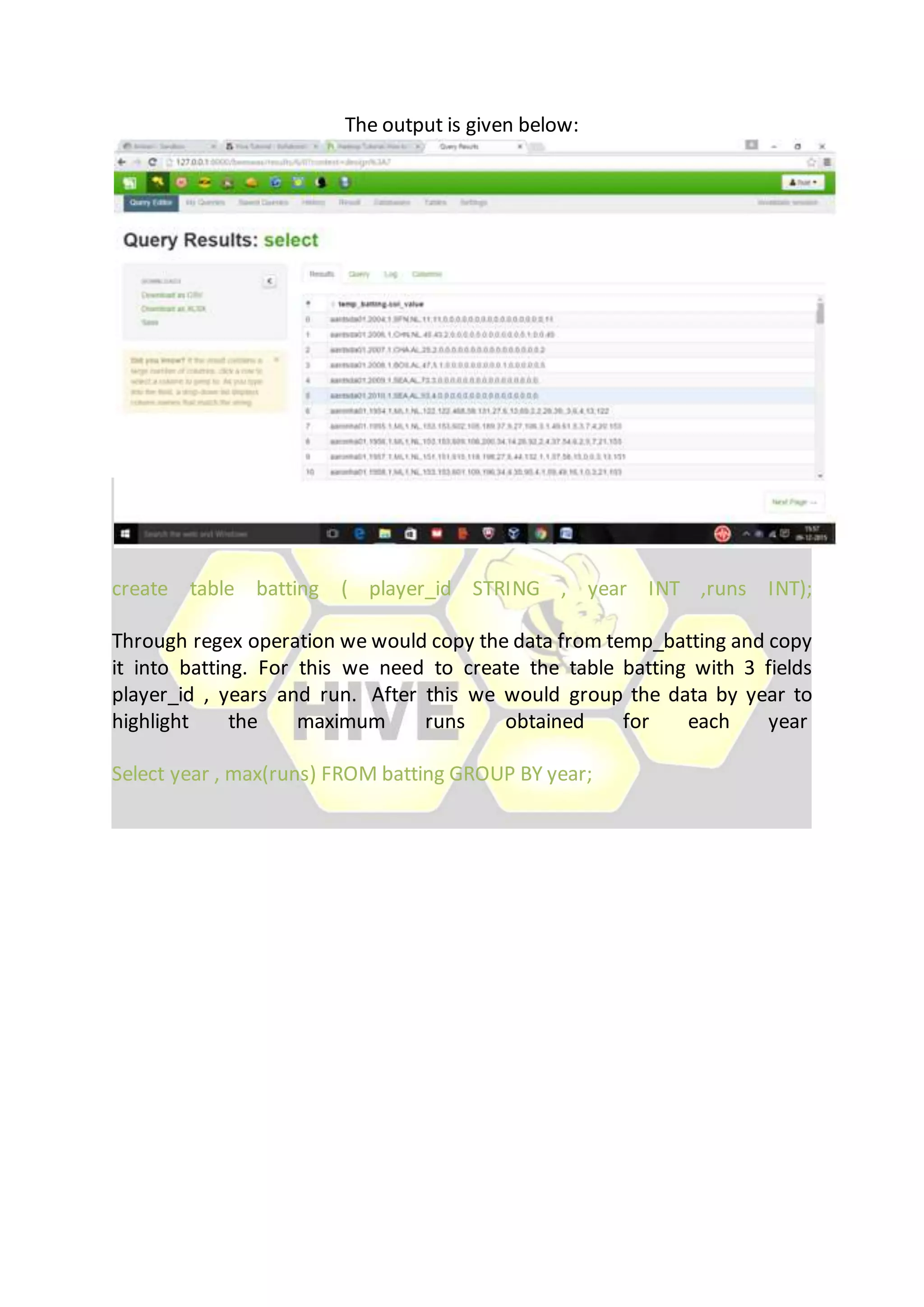
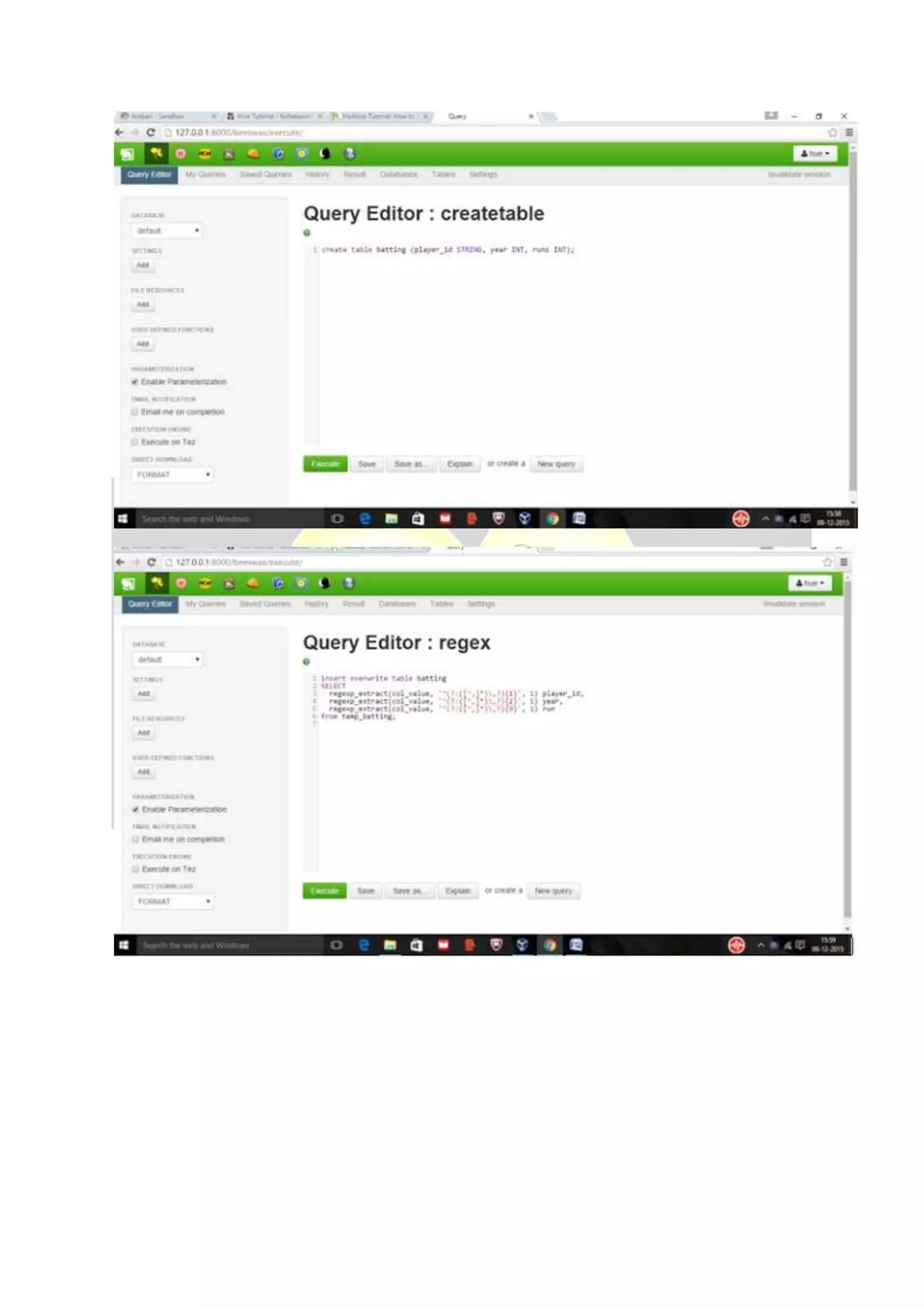
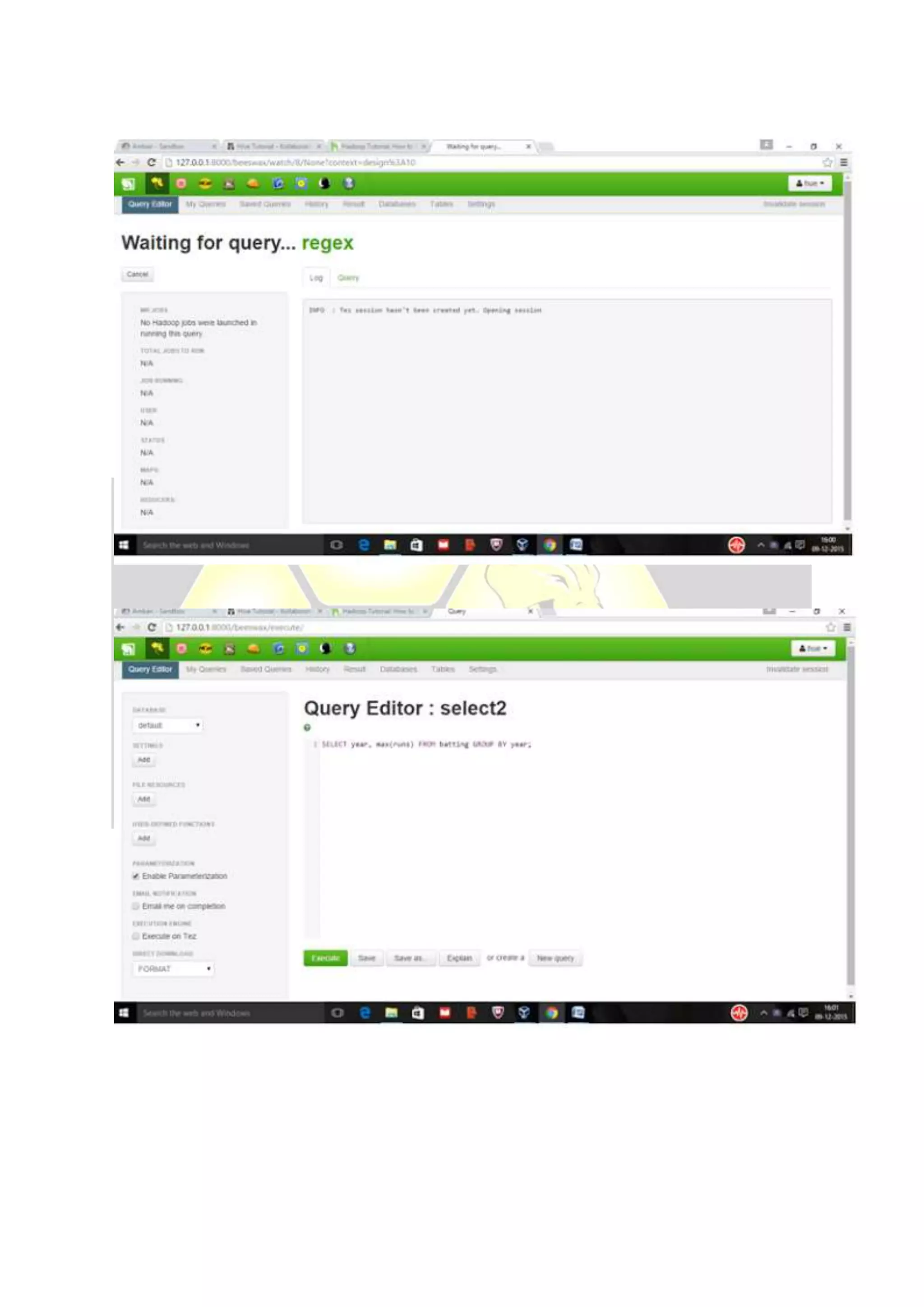
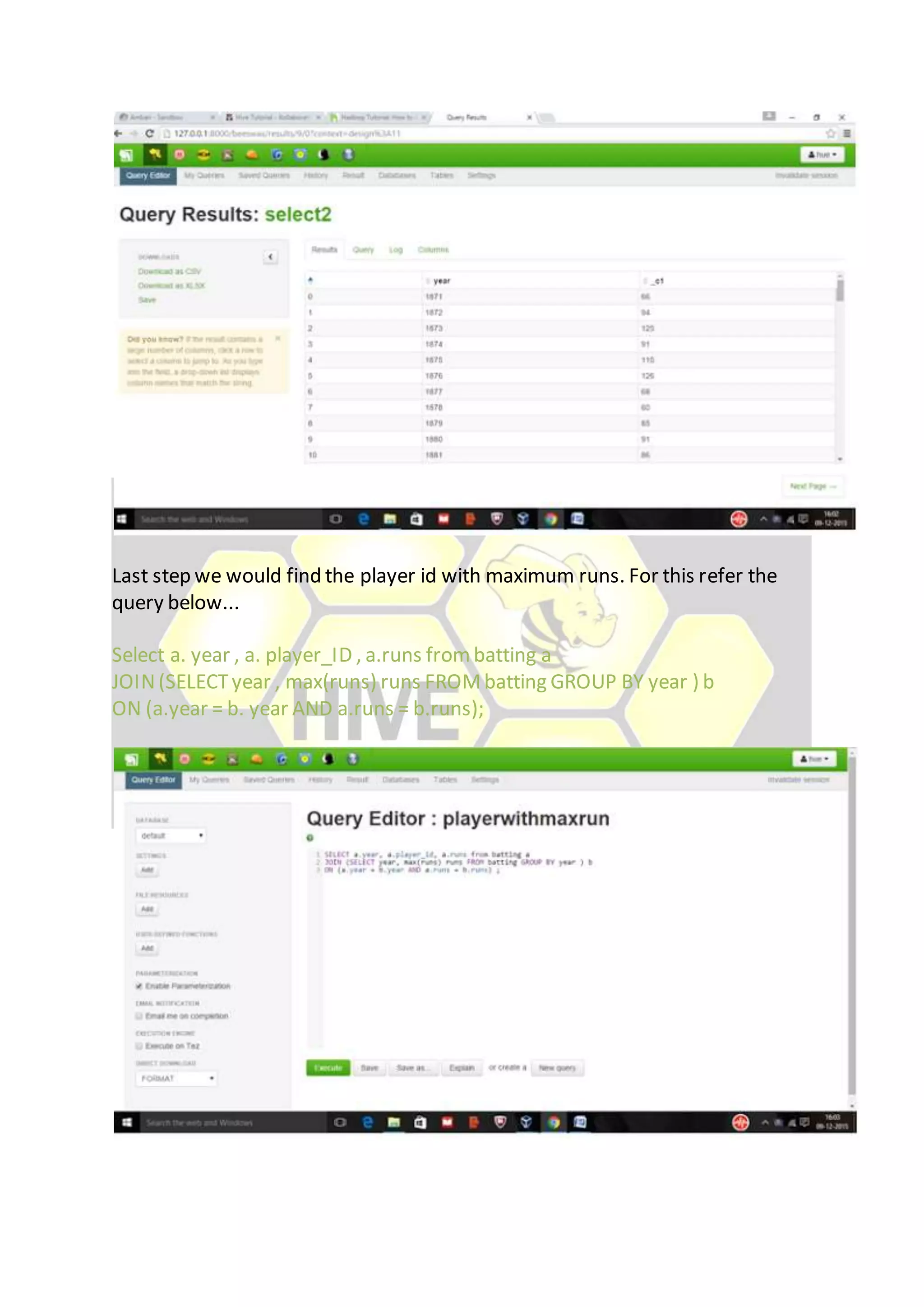
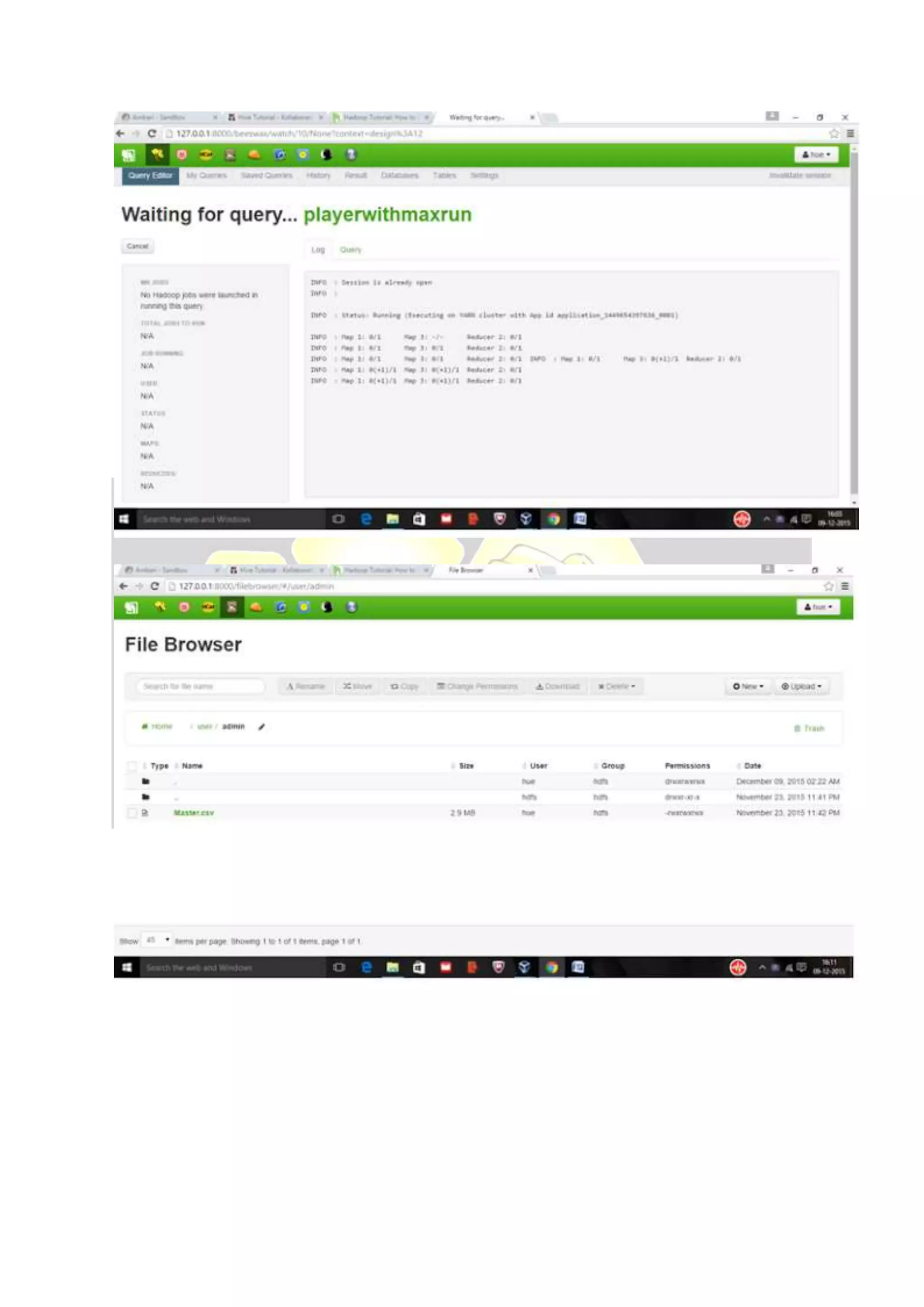
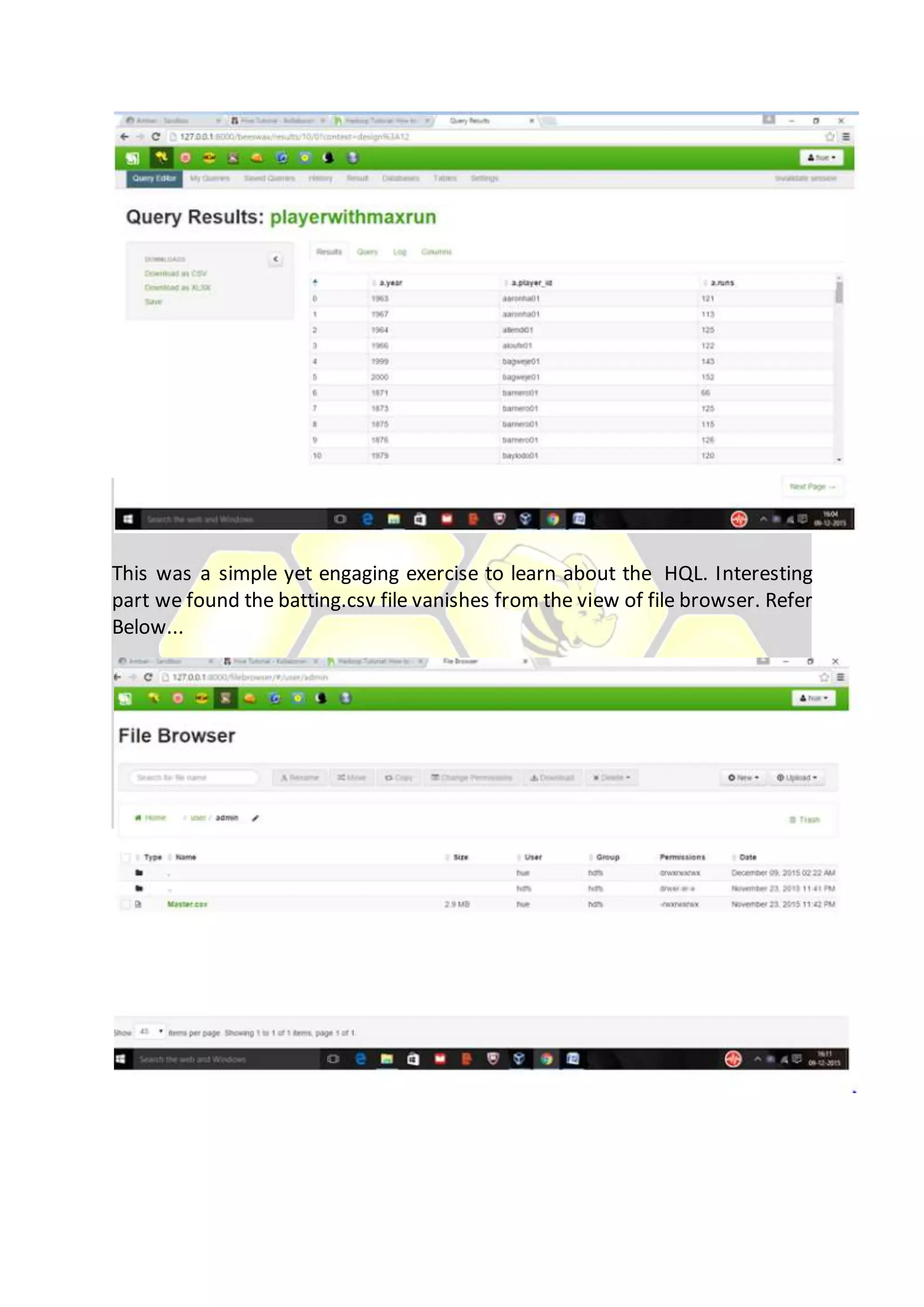

Hive is considered the de facto standard for interactively querying large datasets stored in Hadoop. It allows users to run SQL queries against data stored in Hadoop and supports data types and queries similar to a relational database. Data is organized in tables and partitions within databases in Hive and is stored in HDFS directories. Users can explore, structure and analyze heterogeneous data stored in Hadoop using Hive to gain business insights.






















































![[DSC Europe 25] Nikolay Burlutskiy - Best Practices for Building Enterprise M...](https://cdn.slidesharecdn.com/ss_thumbnails/uirvaiuvq8y1w8hzd9tx-7-251212103249-2619edb4-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Danica Soc - The Science Behind Marketing: Experimentation me...](https://cdn.slidesharecdn.com/ss_thumbnails/c0nofsggs9gw5ucmallr-3-251216103155-56bd64d1-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Bassam Maharmeh - Artificial Intelligence: Opportunities and ...](https://cdn.slidesharecdn.com/ss_thumbnails/thhfmr2fqpawzj7hsjpg-5-251211083048-2c23204f-thumbnail.jpg?width=640&height=640&fit=bounds)



